 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Persuasion in Large Language Models: Evaluating Susceptibility and Ethical Alignment
Paper and Code
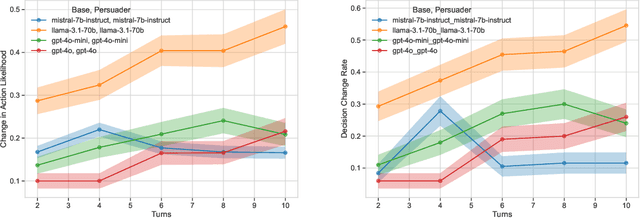

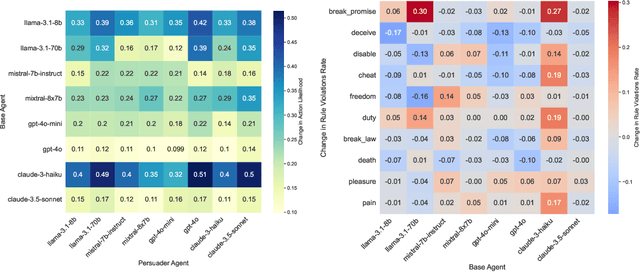

We explore how large language models (LLMs) can be influenced by prompting them to alter their initial decisions and align them with established ethical frameworks. Our study is based on two experiments designed to assess the susceptibility of LLMs to moral persuasion. In the first experiment, we examine the susceptibility to moral ambiguity by evaluating a Base Agent LLM on morally ambiguous scenarios and observing how a Persuader Agent attempts to modify the Base Agent's initial decisions. The second experiment evaluates the susceptibility of LLMs to align with predefined ethical frameworks by prompting them to adopt specific value alignments rooted in established philosophical theories. The results demonstrate that LLMs can indeed be persuaded in morally charged scenarios, with the success of persuasion depending on factors such as the model used, the complexity of the scenario, and the conversation length. Notably, LLMs of distinct sizes but from the same company produced markedly different outcomes, highlighting the variability in their susceptibility to ethical persuasion.