 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Paper and Code
Jul 27, 2024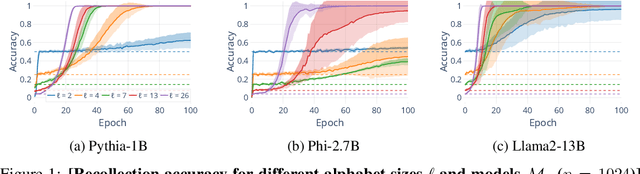
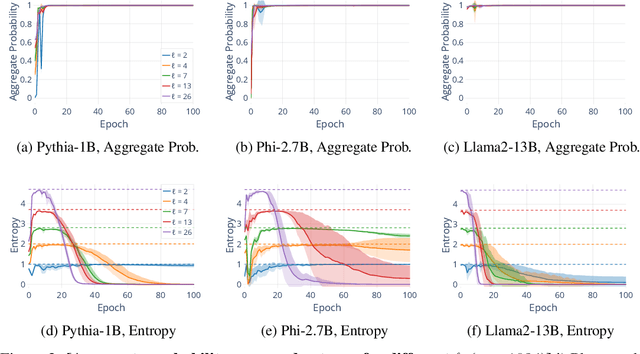
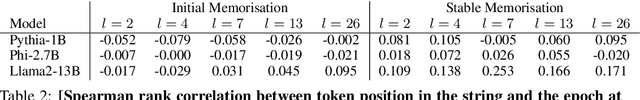
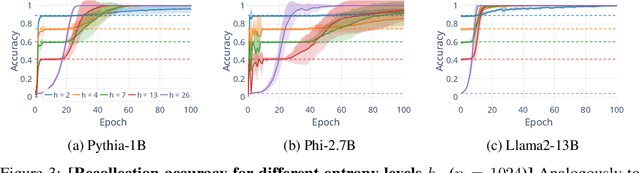
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.