 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Online Video Frame Subset Selection using Multiple Criteria for Data Efficient Autonomous Driving
Paper and Code
Mar 24, 2021

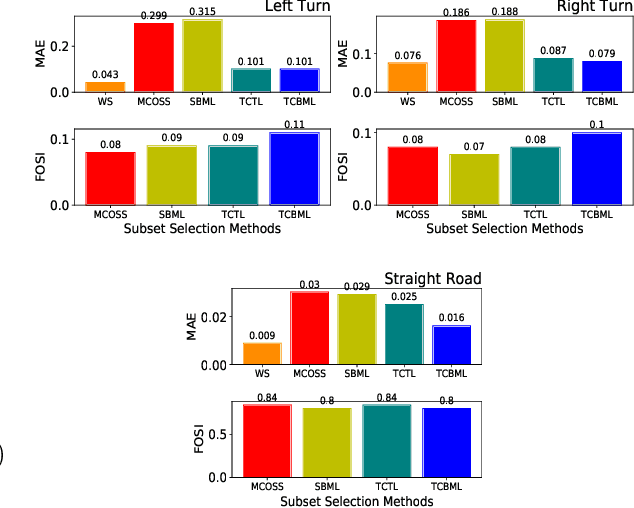

Training vision-based Urban Autonomous driving models is a challenging problem, which is highly researched in recent times. Training such models is a data-intensive task requiring the storage and processing of vast volumes of (possibly redundant) driving video data. In this paper, we study the problem of developing data-efficient autonomous driving systems. In this context, we study the problem of multi-criteria online video frame subset selection. We study convex optimization-based solutions and show that they are unable to provide solutions with high weightage to the loss of selected video frames. We design a novel convex optimization-based multi-criteria online subset selection algorithm that uses a thresholded concave function of selection variables. We also propose and study a submodular optimization-based algorithm. Extensive experiments using the driving simulator CARLA show that we are able to drop 80% of the frames while succeeding to complete 100% of the episodes w.r.t. the model trained on 100% data, in the most difficult task of taking turns. This results in a training time of less than 30% compared to training on the whole dataset. We also perform detailed experiments on prediction performances of various affordances used by the Conditional Affordance Learning (CAL) model and show that our subset selection improves performance on the crucial affordance "Relative Angle" during turns.