 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErasing CLIP Memories: Non-Destructive, Data-Free Zero-Shot class Unlearning in CLIP Models
Dec 16, 2025We introduce a novel, closed-form approach for selective unlearning in multimodal models, specifically targeting pretrained models such as CLIP. Our method leverages nullspace projection to erase the target class information embedded in the final projection layer, without requiring any retraining or the use of images from the forget set. By computing an orthonormal basis for the subspace spanned by target text embeddings and projecting these directions, we dramatically reduce the alignment between image features and undesired classes. Unlike traditional unlearning techniques that rely on iterative fine-tuning and extensive data curation, our approach is both computationally efficient and surgically precise. This leads to a pronounced drop in zero-shot performance for the target classes while preserving the overall multimodal knowledge of the model. Our experiments demonstrate that even a partial projection can balance between complete unlearning and retaining useful information, addressing key challenges in model decontamination and privacy preservation.
Selective, Controlled and Domain-Agnostic Unlearning in Pretrained CLIP: A Training- and Data-Free Approach
Dec 16, 2025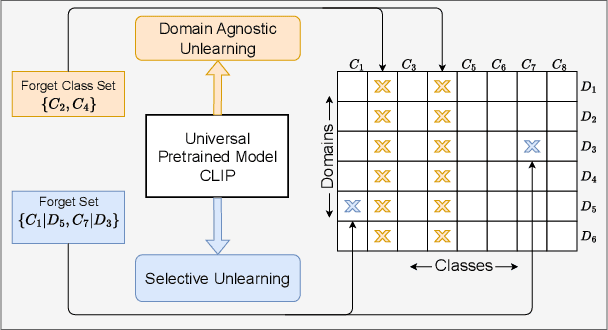
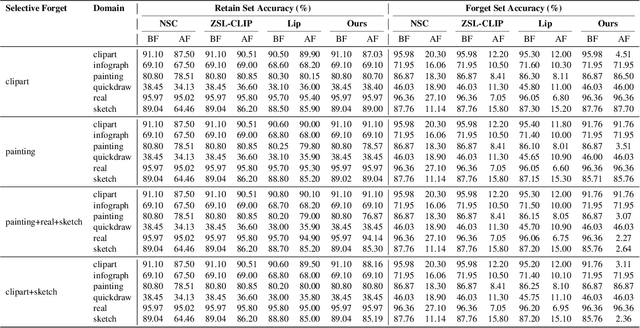
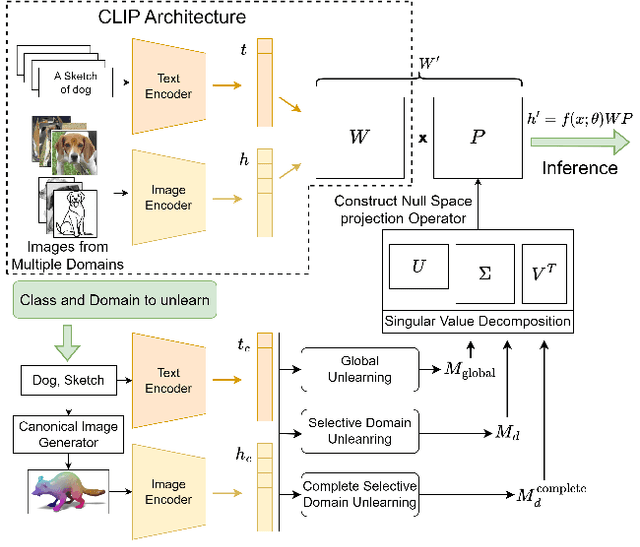
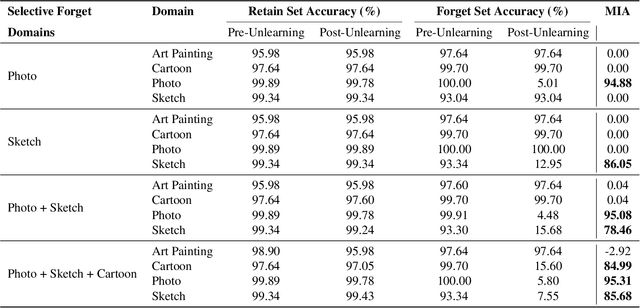
Pretrained models like CLIP have demonstrated impressive zero-shot classification capabilities across diverse visual domains, spanning natural images, artistic renderings, and abstract representations. However, real-world applications often demand the removal (or "unlearning") of specific object classes without requiring additional data or retraining, or affecting the model's performance on unrelated tasks. In this paper, we propose a novel training- and data-free unlearning framework that enables three distinct forgetting paradigms: (1) global unlearning of selected objects across all domains, (2) domain-specific knowledge removal (e.g., eliminating sketch representations while preserving photo recognition), and (3) complete unlearning in selective domains. By leveraging a multimodal nullspace through synergistic integration of text prompts and synthesized visual prototypes derived from CLIP's joint embedding space, our method efficiently removes undesired class information while preserving the remaining knowledge. This approach overcomes the limitations of existing retraining-based methods and offers a flexible and computationally efficient solution for controlled model forgetting.
Data Efficient Evaluation of Large Language Models and Text-to-Image Models via Adaptive Sampling
Jun 21, 2024Evaluating LLMs and text-to-image models is a computationally intensive task often overlooked. Efficient evaluation is crucial for understanding the diverse capabilities of these models and enabling comparisons across a growing number of new models and benchmarks. To address this, we introduce SubLIME, a data-efficient evaluation framework that employs adaptive sampling techniques, such as clustering and quality-based methods, to create representative subsets of benchmarks. Our approach ensures statistically aligned model rankings compared to full datasets, evidenced by high Pearson correlation coefficients. Empirical analysis across six NLP benchmarks reveals that: (1) quality-based sampling consistently achieves strong correlations (0.85 to 0.95) with full datasets at a 10\% sampling rate such as Quality SE and Quality CPD (2) clustering methods excel in specific benchmarks such as MMLU (3) no single method universally outperforms others across all metrics. Extending this framework, we leverage the HEIM leaderboard to cover 25 text-to-image models on 17 different benchmarks. SubLIME dynamically selects the optimal technique for each benchmark, significantly reducing evaluation costs while preserving ranking integrity and score distribution. Notably, a minimal sampling rate of 1% proves effective for benchmarks like MMLU. Additionally, we demonstrate that employing difficulty-based sampling to target more challenging benchmark segments enhances model differentiation with broader score distributions. We also combine semantic search, tool use, and GPT-4 review to identify redundancy across benchmarks within specific LLM categories, such as coding benchmarks. This allows us to further reduce the number of samples needed to maintain targeted rank preservation. Overall, SubLIME offers a versatile and cost-effective solution for the robust evaluation of LLMs and text-to-image models.
VTruST: Controllable value function based subset selection for Data-Centric Trustworthy AI
Mar 08, 2024
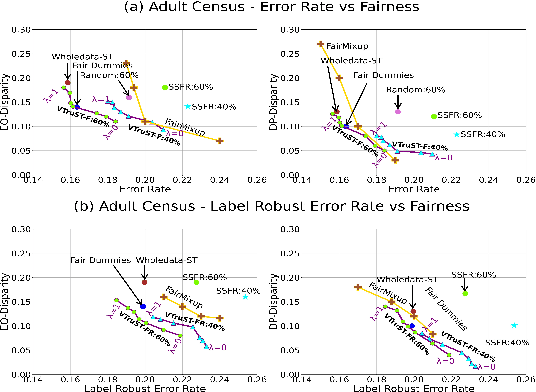
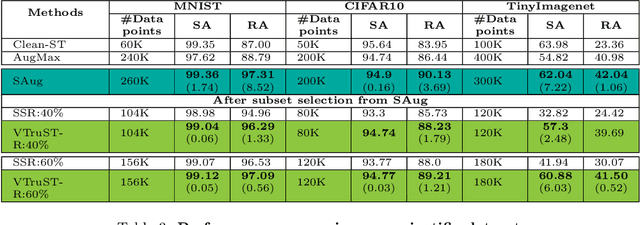
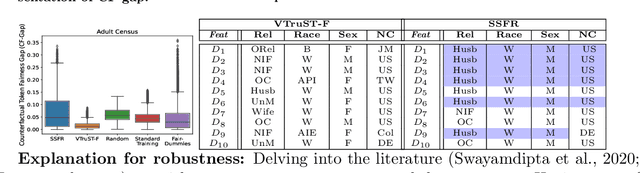
Trustworthy AI is crucial to the widespread adoption of AI in high-stakes applications with fairness, robustness, and accuracy being some of the key trustworthiness metrics. In this work, we propose a controllable framework for data-centric trustworthy AI (DCTAI)- VTruST, that allows users to control the trade-offs between the different trustworthiness metrics of the constructed training datasets. A key challenge in implementing an efficient DCTAI framework is to design an online value-function-based training data subset selection algorithm. We pose the training data valuation and subset selection problem as an online sparse approximation formulation. We propose a novel online version of the Orthogonal Matching Pursuit (OMP) algorithm for solving this problem. Experimental results show that VTruST outperforms the state-of-the-art baselines on social, image, and scientific datasets. We also show that the data values generated by VTruST can provide effective data-centric explanations for different trustworthiness metrics.
CheckSel: Efficient and Accurate Data-valuation Through Online Checkpoint Selection
Mar 14, 2022



Data valuation and subset selection have emerged as valuable tools for application-specific selection of important training data. However, the efficiency-accuracy tradeoffs of state-of-the-art methods hinder their widespread application to many AI workflows. In this paper, we propose a novel 2-phase solution to this problem. Phase 1 selects representative checkpoints from an SGD-like training algorithm, which are used in phase-2 to estimate the approximate training data values, e.g. decrease in validation loss due to each training point. A key contribution of this paper is CheckSel, an Orthogonal Matching Pursuit-inspired online sparse approximation algorithm for checkpoint selection in the online setting, where the features are revealed one at a time. Another key contribution is the study of data valuation in the domain adaptation setting, where a data value estimator obtained using checkpoints from training trajectory in the source domain training dataset is used for data valuation in a target domain training dataset. Experimental results on benchmark datasets show the proposed algorithm outperforms recent baseline methods by up to 30% in terms of test accuracy while incurring a similar computational burden, for both standalone and domain adaptation settings.
Finding High-Value Training Data Subset through Differentiable Convex Programming
Apr 28, 2021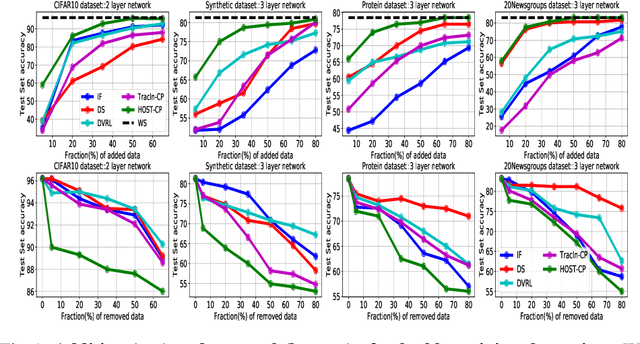

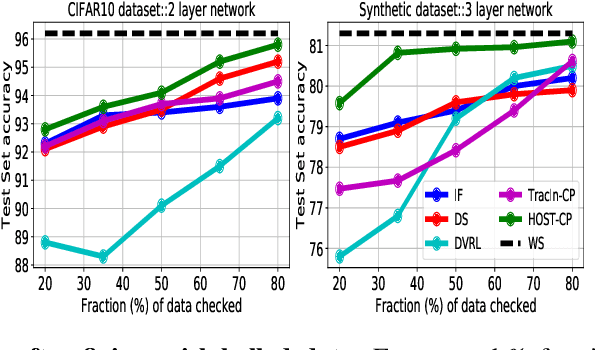
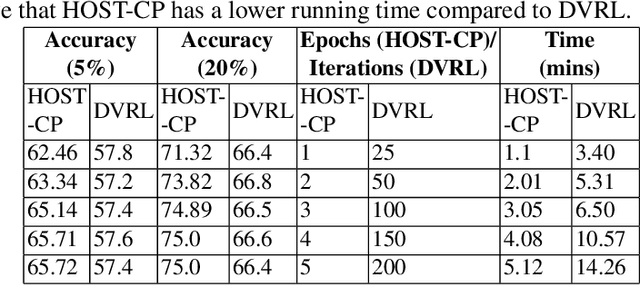
Finding valuable training data points for deep neural networks has been a core research challenge with many applications. In recent years, various techniques for calculating the "value" of individual training datapoints have been proposed for explaining trained models. However, the value of a training datapoint also depends on other selected training datapoints - a notion that is not explicitly captured by existing methods. In this paper, we study the problem of selecting high-value subsets of training data. The key idea is to design a learnable framework for online subset selection, which can be learned using mini-batches of training data, thus making our method scalable. This results in a parameterized convex subset selection problem that is amenable to a differentiable convex programming paradigm, thus allowing us to learn the parameters of the selection model in end-to-end training. Using this framework, we design an online alternating minimization-based algorithm for jointly learning the parameters of the selection model and ML model. Extensive evaluation on a synthetic dataset, and three standard datasets, show that our algorithm finds consistently higher value subsets of training data, compared to the recent state-of-the-art methods, sometimes ~20% higher value than existing methods. The subsets are also useful in finding mislabelled training data. Our algorithm takes running time comparable to the existing valuation functions.
Convex Online Video Frame Subset Selection using Multiple Criteria for Data Efficient Autonomous Driving
Mar 24, 2021

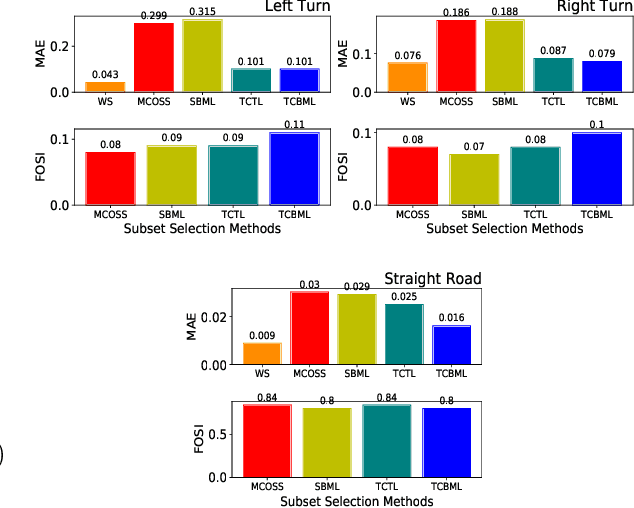

Training vision-based Urban Autonomous driving models is a challenging problem, which is highly researched in recent times. Training such models is a data-intensive task requiring the storage and processing of vast volumes of (possibly redundant) driving video data. In this paper, we study the problem of developing data-efficient autonomous driving systems. In this context, we study the problem of multi-criteria online video frame subset selection. We study convex optimization-based solutions and show that they are unable to provide solutions with high weightage to the loss of selected video frames. We design a novel convex optimization-based multi-criteria online subset selection algorithm that uses a thresholded concave function of selection variables. We also propose and study a submodular optimization-based algorithm. Extensive experiments using the driving simulator CARLA show that we are able to drop 80% of the frames while succeeding to complete 100% of the episodes w.r.t. the model trained on 100% data, in the most difficult task of taking turns. This results in a training time of less than 30% compared to training on the whole dataset. We also perform detailed experiments on prediction performances of various affordances used by the Conditional Affordance Learning (CAL) model and show that our subset selection improves performance on the crucial affordance "Relative Angle" during turns.