 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Deployed Distributed Magnetic Resonance Imaging Reconstruction: Application to Pediatric Knee Imaging
Sep 11, 2018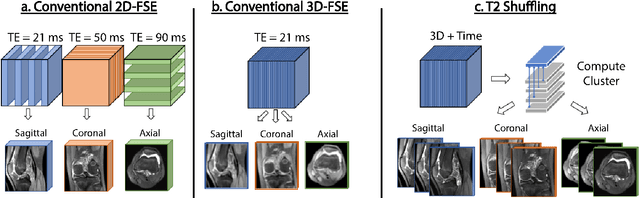
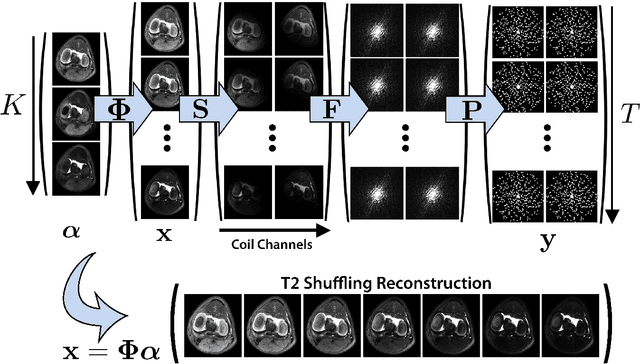
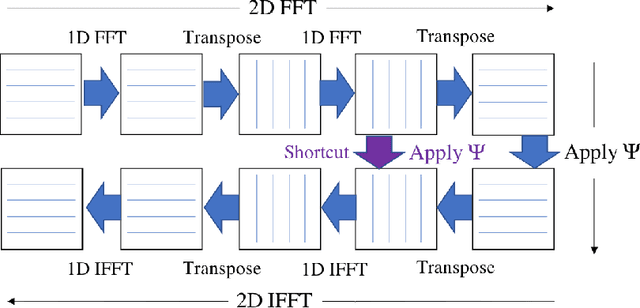
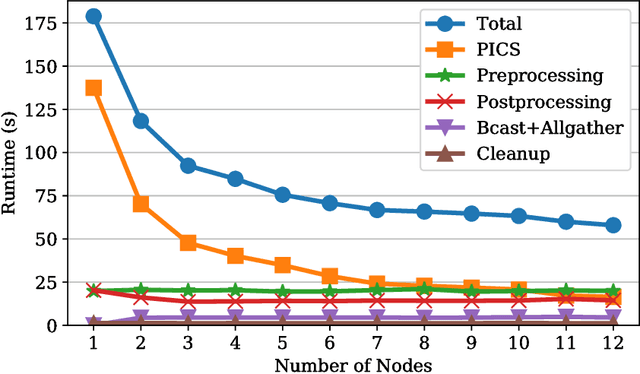
Magnetic resonance imaging is capable of producing volumetric images without ionizing radiation. Nonetheless, long acquisitions lead to prohibitively long exams. Compressed sensing (CS) can enable faster scanning via sub-sampling with reduced artifacts. However, CS requires significantly higher reconstruction computation, limiting current clinical applications to 2D/3D or limited-resolution dynamic imaging. Here we analyze the practical limitations to T2 Shuffling, a four-dimensional CS-based acquisition, which provides sharp 3D-isotropic-resolution and multi-contrast images in a single scan. Our improvements to the pipeline on a single machine provide a 3x overall reconstruction speedup, which allowed us to add algorithmic changes improving image quality. Using four machines, we achieved additional 2.1x improvement through distributed parallelization. Our solution reduced the reconstruction time in the hospital to 90 seconds on a 4-node cluster, enabling its use clinically. To understand the implications of scaling this application, we simulated running our reconstructions with a multiple scanner setup typical in hospitals.
Enabling Factor Analysis on Thousand-Subject Neuroimaging Datasets
Aug 18, 2016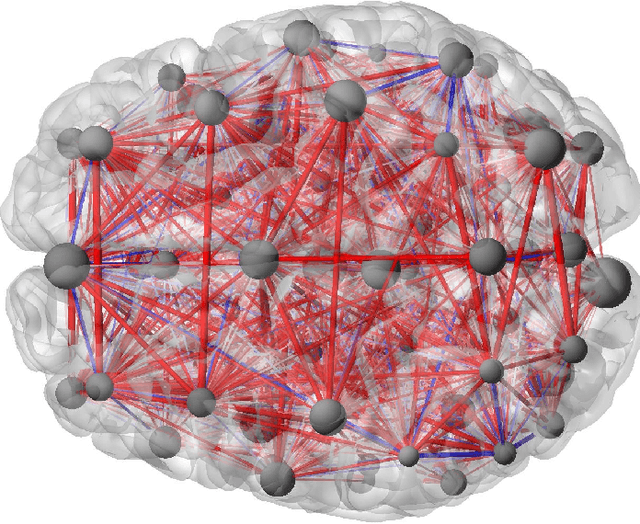
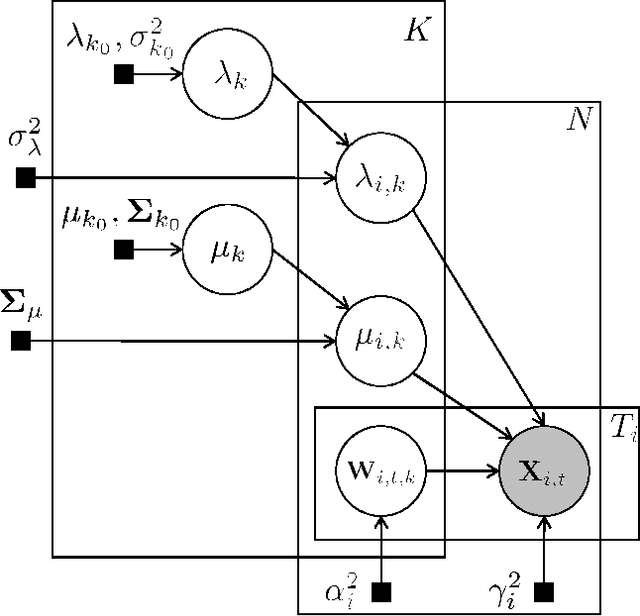
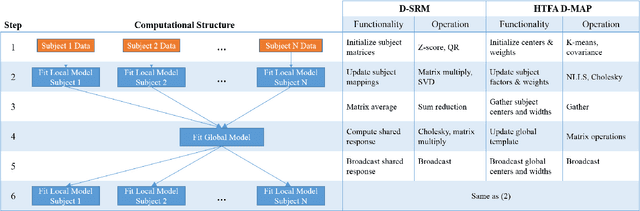
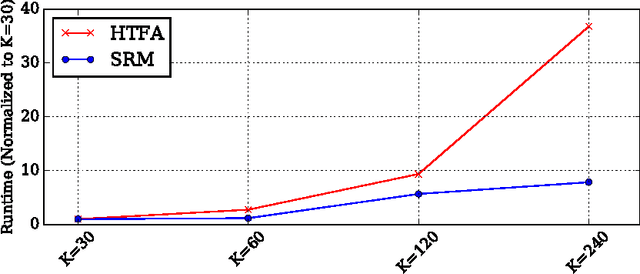
The scale of functional magnetic resonance image data is rapidly increasing as large multi-subject datasets are becoming widely available and high-resolution scanners are adopted. The inherent low-dimensionality of the information in this data has led neuroscientists to consider factor analysis methods to extract and analyze the underlying brain activity. In this work, we consider two recent multi-subject factor analysis methods: the Shared Response Model and Hierarchical Topographic Factor Analysis. We perform analytical, algorithmic, and code optimization to enable multi-node parallel implementations to scale. Single-node improvements result in 99x and 1812x speedups on these two methods, and enables the processing of larger datasets. Our distributed implementations show strong scaling of 3.3x and 5.5x respectively with 20 nodes on real datasets. We also demonstrate weak scaling on a synthetic dataset with 1024 subjects, on up to 1024 nodes and 32,768 cores.
BlackOut: Speeding up Recurrent Neural Network Language Models With Very Large Vocabularies
Mar 31, 2016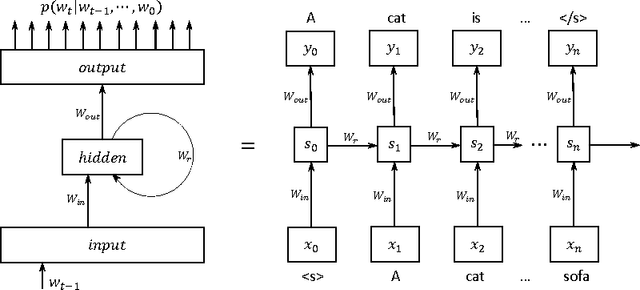
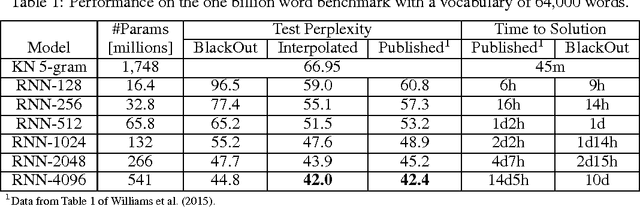
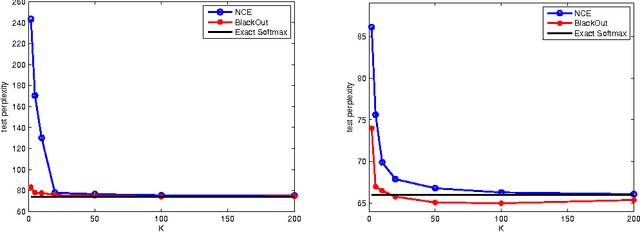
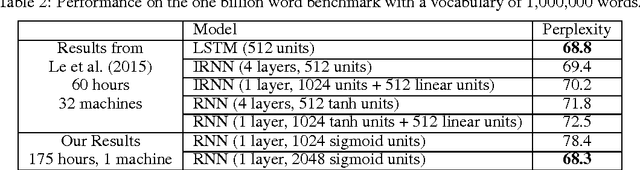
We propose BlackOut, an approximation algorithm to efficiently train massive recurrent neural network language models (RNNLMs) with million word vocabularies. BlackOut is motivated by using a discriminative loss, and we describe a new sampling strategy which significantly reduces computation while improving stability, sample efficiency, and rate of convergence. One way to understand BlackOut is to view it as an extension of the DropOut strategy to the output layer, wherein we use a discriminative training loss and a weighted sampling scheme. We also establish close connections between BlackOut, importance sampling, and noise contrastive estimation (NCE). Our experiments, on the recently released one billion word language modeling benchmark, demonstrate scalability and accuracy of BlackOut; we outperform the state-of-the art, and achieve the lowest perplexity scores on this dataset. Moreover, unlike other established methods which typically require GPUs or CPU clusters, we show that a carefully implemented version of BlackOut requires only 1-10 days on a single machine to train a RNNLM with a million word vocabulary and billions of parameters on one billion words. Although we describe BlackOut in the context of RNNLM training, it can be used to any networks with large softmax output layers.