 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning at 15PF: Supervised and Semi-Supervised Classification for Scientific Data
Aug 17, 2017
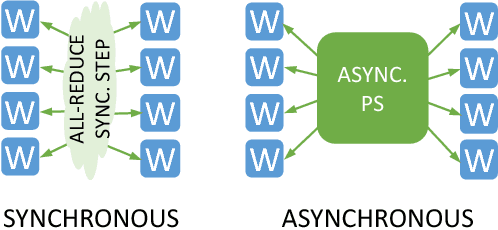
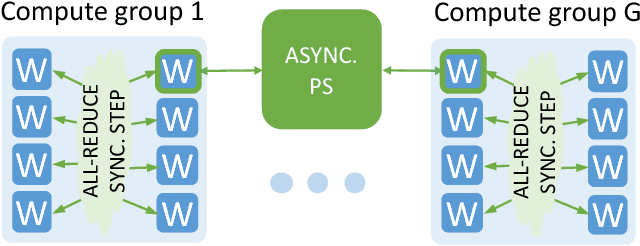
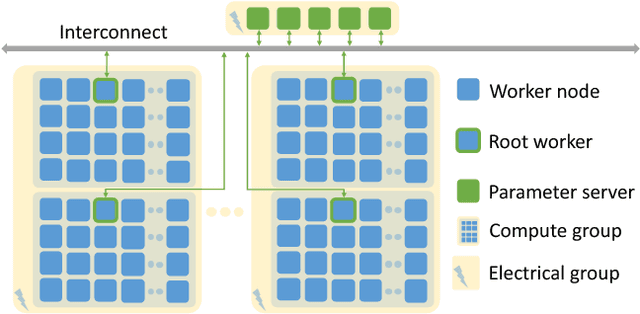
This paper presents the first, 15-PetaFLOP Deep Learning system for solving scientific pattern classification problems on contemporary HPC architectures. We develop supervised convolutional architectures for discriminating signals in high-energy physics data as well as semi-supervised architectures for localizing and classifying extreme weather in climate data. Our Intelcaffe-based implementation obtains $\sim$2TFLOP/s on a single Cori Phase-II Xeon-Phi node. We use a hybrid strategy employing synchronous node-groups, while using asynchronous communication across groups. We use this strategy to scale training of a single model to $\sim$9600 Xeon-Phi nodes; obtaining peak performance of 11.73-15.07 PFLOP/s and sustained performance of 11.41-13.27 PFLOP/s. At scale, our HEP architecture produces state-of-the-art classification accuracy on a dataset with 10M images, exceeding that achieved by selections on high-level physics-motivated features. Our semi-supervised architecture successfully extracts weather patterns in a 15TB climate dataset. Our results demonstrate that Deep Learning can be optimized and scaled effectively on many-core, HPC systems.
Parallelizing Word2Vec in Multi-Core and Many-Core Architectures
Dec 23, 2016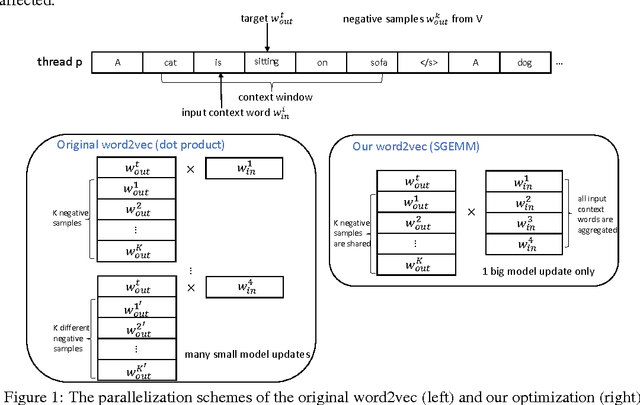
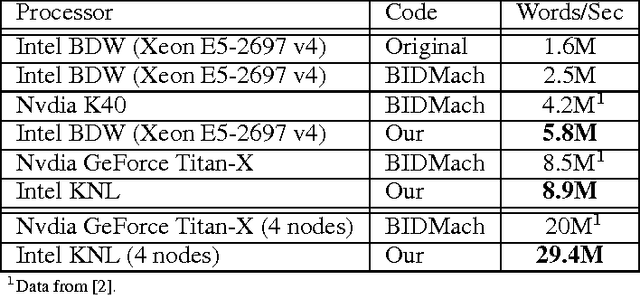

Word2vec is a widely used algorithm for extracting low-dimensional vector representations of words. State-of-the-art algorithms including those by Mikolov et al. have been parallelized for multi-core CPU architectures, but are based on vector-vector operations with "Hogwild" updates that are memory-bandwidth intensive and do not efficiently use computational resources. In this paper, we propose "HogBatch" by improving reuse of various data structures in the algorithm through the use of minibatching and negative sample sharing, hence allowing us to express the problem using matrix multiply operations. We also explore different techniques to distribute word2vec computation across nodes in a compute cluster, and demonstrate good strong scalability up to 32 nodes. The new algorithm is particularly suitable for modern multi-core/many-core architectures, especially Intel's latest Knights Landing processors, and allows us to scale up the computation near linearly across cores and nodes, and process hundreds of millions of words per second, which is the fastest word2vec implementation to the best of our knowledge.
Parallelizing Word2Vec in Shared and Distributed Memory
Aug 08, 2016


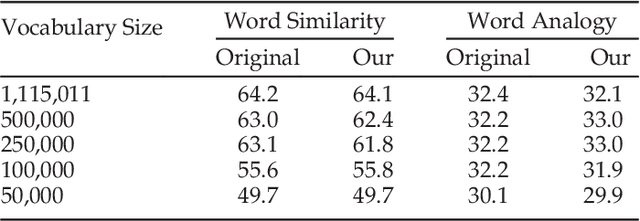
Word2Vec is a widely used algorithm for extracting low-dimensional vector representations of words. It generated considerable excitement in the machine learning and natural language processing (NLP) communities recently due to its exceptional performance in many NLP applications such as named entity recognition, sentiment analysis, machine translation and question answering. State-of-the-art algorithms including those by Mikolov et al. have been parallelized for multi-core CPU architectures but are based on vector-vector operations that are memory-bandwidth intensive and do not efficiently use computational resources. In this paper, we improve reuse of various data structures in the algorithm through the use of minibatching, hence allowing us to express the problem using matrix multiply operations. We also explore different techniques to distribute word2vec computation across nodes in a compute cluster, and demonstrate good strong scalability up to 32 nodes. In combination, these techniques allow us to scale up the computation near linearly across cores and nodes, and process hundreds of millions of words per second, which is the fastest word2vec implementation to the best of our knowledge.
BlackOut: Speeding up Recurrent Neural Network Language Models With Very Large Vocabularies
Mar 31, 2016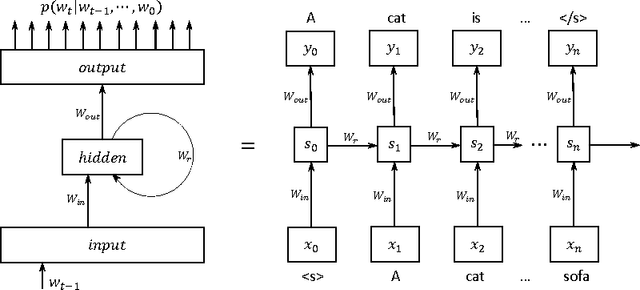
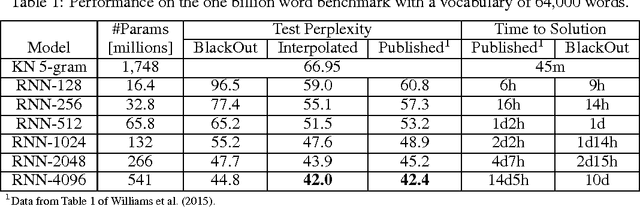
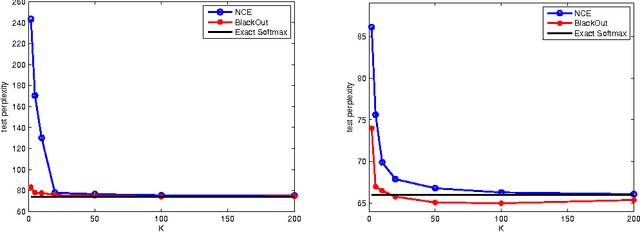
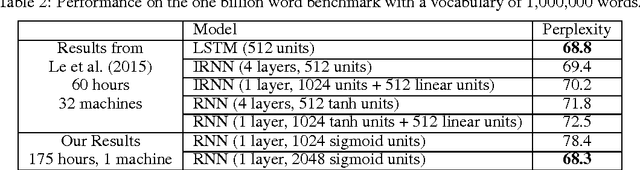
We propose BlackOut, an approximation algorithm to efficiently train massive recurrent neural network language models (RNNLMs) with million word vocabularies. BlackOut is motivated by using a discriminative loss, and we describe a new sampling strategy which significantly reduces computation while improving stability, sample efficiency, and rate of convergence. One way to understand BlackOut is to view it as an extension of the DropOut strategy to the output layer, wherein we use a discriminative training loss and a weighted sampling scheme. We also establish close connections between BlackOut, importance sampling, and noise contrastive estimation (NCE). Our experiments, on the recently released one billion word language modeling benchmark, demonstrate scalability and accuracy of BlackOut; we outperform the state-of-the art, and achieve the lowest perplexity scores on this dataset. Moreover, unlike other established methods which typically require GPUs or CPU clusters, we show that a carefully implemented version of BlackOut requires only 1-10 days on a single machine to train a RNNLM with a million word vocabulary and billions of parameters on one billion words. Although we describe BlackOut in the context of RNNLM training, it can be used to any networks with large softmax output layers.
Scalable Bayesian Optimization Using Deep Neural Networks
Jul 13, 2015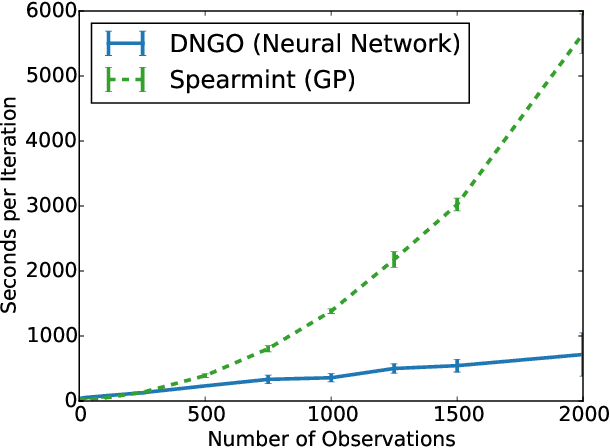
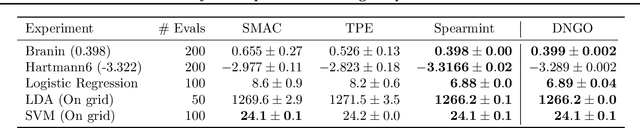
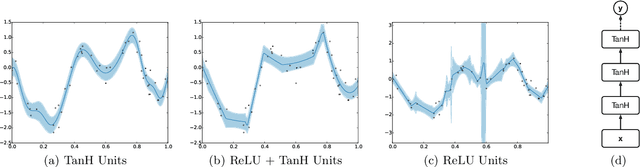

Bayesian optimization is an effective methodology for the global optimization of functions with expensive evaluations. It relies on querying a distribution over functions defined by a relatively cheap surrogate model. An accurate model for this distribution over functions is critical to the effectiveness of the approach, and is typically fit using Gaussian processes (GPs). However, since GPs scale cubically with the number of observations, it has been challenging to handle objectives whose optimization requires many evaluations, and as such, massively parallelizing the optimization. In this work, we explore the use of neural networks as an alternative to GPs to model distributions over functions. We show that performing adaptive basis function regression with a neural network as the parametric form performs competitively with state-of-the-art GP-based approaches, but scales linearly with the number of data rather than cubically. This allows us to achieve a previously intractable degree of parallelism, which we apply to large scale hyperparameter optimization, rapidly finding competitive models on benchmark object recognition tasks using convolutional networks, and image caption generation using neural language models.