 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Attend and Tell: Neural Image Caption Generation with Visual Attention
Apr 19, 2016



Inspired by recent work in machine translation and object detection, we introduce an attention based model that automatically learns to describe the content of images. We describe how we can train this model in a deterministic manner using standard backpropagation techniques and stochastically by maximizing a variational lower bound. We also show through visualization how the model is able to automatically learn to fix its gaze on salient objects while generating the corresponding words in the output sequence. We validate the use of attention with state-of-the-art performance on three benchmark datasets: Flickr8k, Flickr30k and MS COCO.
Order-Embeddings of Images and Language
Mar 01, 2016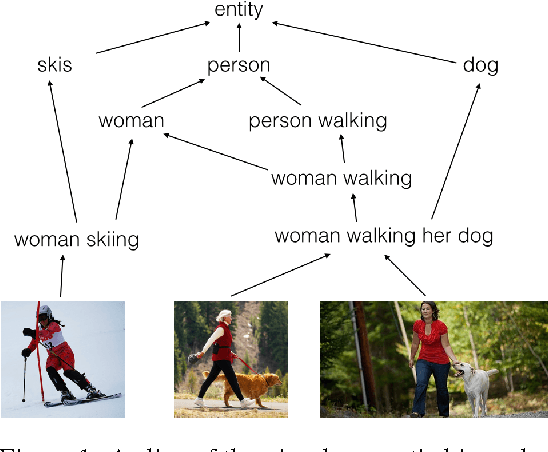

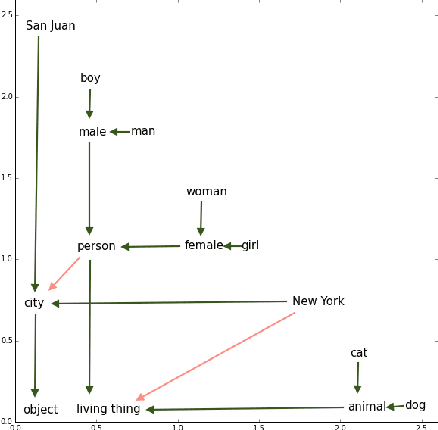
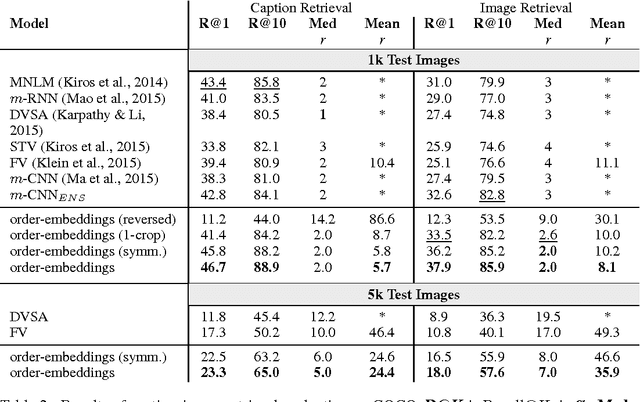
Hypernymy, textual entailment, and image captioning can be seen as special cases of a single visual-semantic hierarchy over words, sentences, and images. In this paper we advocate for explicitly modeling the partial order structure of this hierarchy. Towards this goal, we introduce a general method for learning ordered representations, and show how it can be applied to a variety of tasks involving images and language. We show that the resulting representations improve performance over current approaches for hypernym prediction and image-caption retrieval.
Action Recognition using Visual Attention
Feb 14, 2016
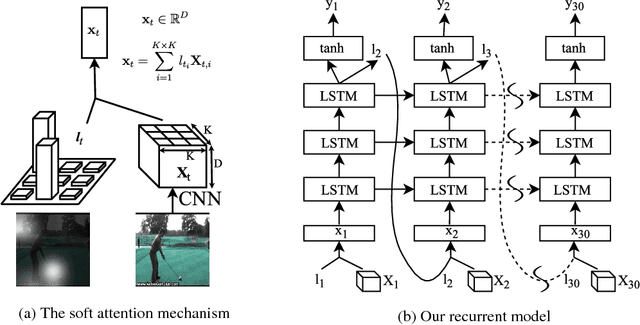


We propose a soft attention based model for the task of action recognition in videos. We use multi-layered Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) units which are deep both spatially and temporally. Our model learns to focus selectively on parts of the video frames and classifies videos after taking a few glimpses. The model essentially learns which parts in the frames are relevant for the task at hand and attaches higher importance to them. We evaluate the model on UCF-11 (YouTube Action), HMDB-51 and Hollywood2 datasets and analyze how the model focuses its attention depending on the scene and the action being performed.
Exploring Models and Data for Image Question Answering
Nov 29, 2015
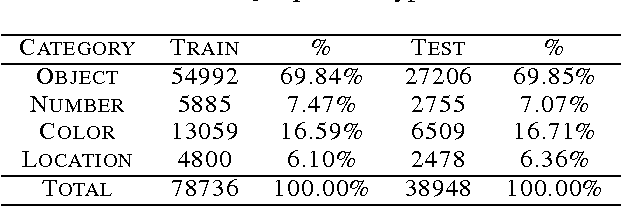
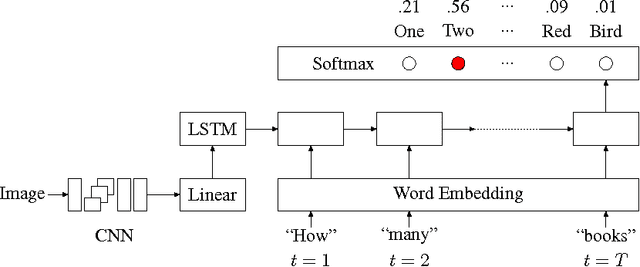
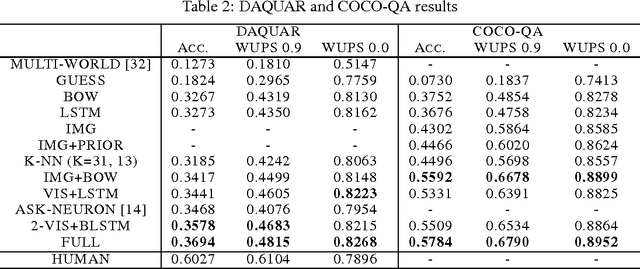
This work aims to address the problem of image-based question-answering (QA) with new models and datasets. In our work, we propose to use neural networks and visual semantic embeddings, without intermediate stages such as object detection and image segmentation, to predict answers to simple questions about images. Our model performs 1.8 times better than the only published results on an existing image QA dataset. We also present a question generation algorithm that converts image descriptions, which are widely available, into QA form. We used this algorithm to produce an order-of-magnitude larger dataset, with more evenly distributed answers. A suite of baseline results on this new dataset are also presented.
Scalable Bayesian Optimization Using Deep Neural Networks
Jul 13, 2015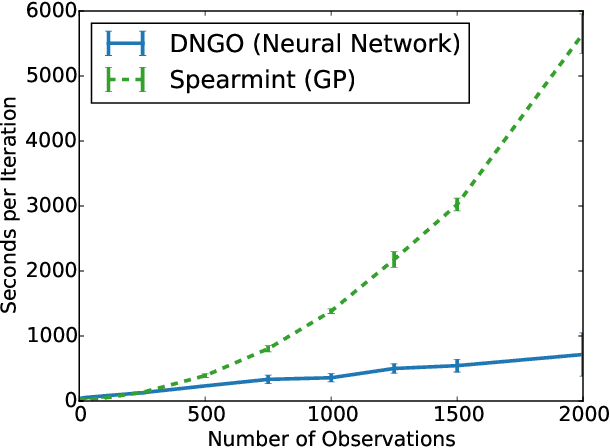
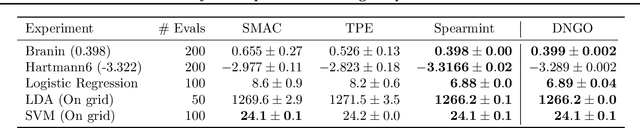
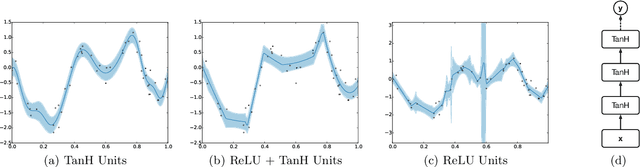

Bayesian optimization is an effective methodology for the global optimization of functions with expensive evaluations. It relies on querying a distribution over functions defined by a relatively cheap surrogate model. An accurate model for this distribution over functions is critical to the effectiveness of the approach, and is typically fit using Gaussian processes (GPs). However, since GPs scale cubically with the number of observations, it has been challenging to handle objectives whose optimization requires many evaluations, and as such, massively parallelizing the optimization. In this work, we explore the use of neural networks as an alternative to GPs to model distributions over functions. We show that performing adaptive basis function regression with a neural network as the parametric form performs competitively with state-of-the-art GP-based approaches, but scales linearly with the number of data rather than cubically. This allows us to achieve a previously intractable degree of parallelism, which we apply to large scale hyperparameter optimization, rapidly finding competitive models on benchmark object recognition tasks using convolutional networks, and image caption generation using neural language models.
Skip-Thought Vectors
Jun 22, 2015
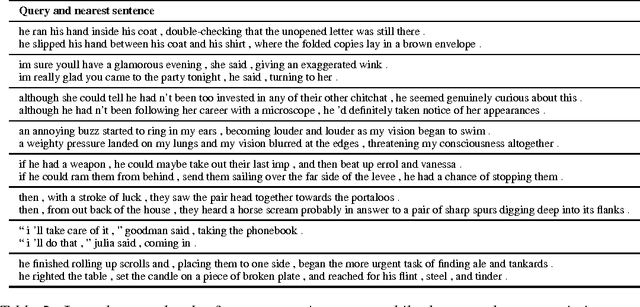
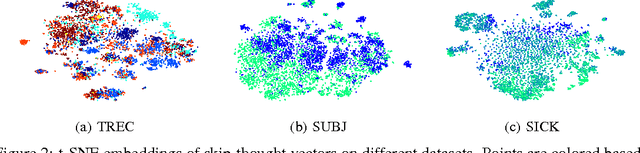

We describe an approach for unsupervised learning of a generic, distributed sentence encoder. Using the continuity of text from books, we train an encoder-decoder model that tries to reconstruct the surrounding sentences of an encoded passage. Sentences that share semantic and syntactic properties are thus mapped to similar vector representations. We next introduce a simple vocabulary expansion method to encode words that were not seen as part of training, allowing us to expand our vocabulary to a million words. After training our model, we extract and evaluate our vectors with linear models on 8 tasks: semantic relatedness, paraphrase detection, image-sentence ranking, question-type classification and 4 benchmark sentiment and subjectivity datasets. The end result is an off-the-shelf encoder that can produce highly generic sentence representations that are robust and perform well in practice. We will make our encoder publicly available.
Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books
Jun 22, 2015
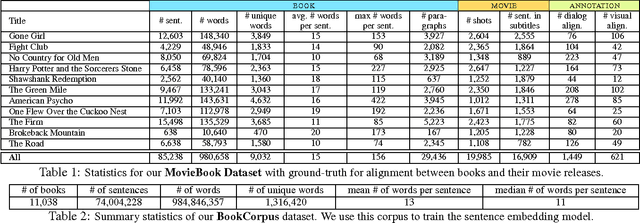


Books are a rich source of both fine-grained information, how a character, an object or a scene looks like, as well as high-level semantics, what someone is thinking, feeling and how these states evolve through a story. This paper aims to align books to their movie releases in order to provide rich descriptive explanations for visual content that go semantically far beyond the captions available in current datasets. To align movies and books we exploit a neural sentence embedding that is trained in an unsupervised way from a large corpus of books, as well as a video-text neural embedding for computing similarities between movie clips and sentences in the book. We propose a context-aware CNN to combine information from multiple sources. We demonstrate good quantitative performance for movie/book alignment and show several qualitative examples that showcase the diversity of tasks our model can be used for.
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
Nov 10, 2014
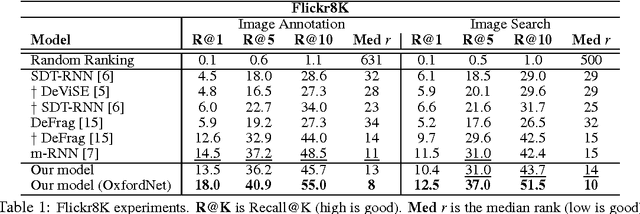
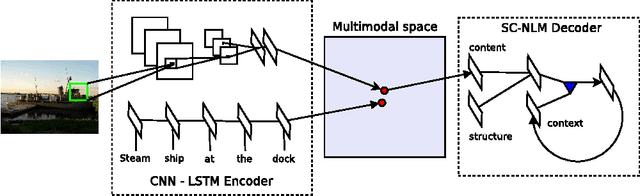
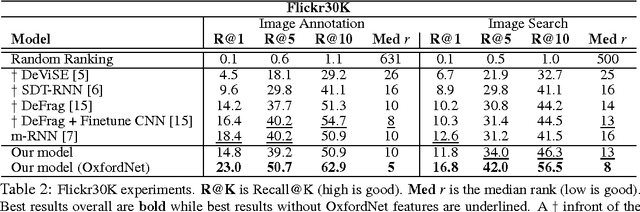
Inspired by recent advances in multimodal learning and machine translation, we introduce an encoder-decoder pipeline that learns (a): a multimodal joint embedding space with images and text and (b): a novel language model for decoding distributed representations from our space. Our pipeline effectively unifies joint image-text embedding models with multimodal neural language models. We introduce the structure-content neural language model that disentangles the structure of a sentence to its content, conditioned on representations produced by the encoder. The encoder allows one to rank images and sentences while the decoder can generate novel descriptions from scratch. Using LSTM to encode sentences, we match the state-of-the-art performance on Flickr8K and Flickr30K without using object detections. We also set new best results when using the 19-layer Oxford convolutional network. Furthermore we show that with linear encoders, the learned embedding space captures multimodal regularities in terms of vector space arithmetic e.g. *image of a blue car* - "blue" + "red" is near images of red cars. Sample captions generated for 800 images are made available for comparison.
A Multiplicative Model for Learning Distributed Text-Based Attribute Representations
Jun 10, 2014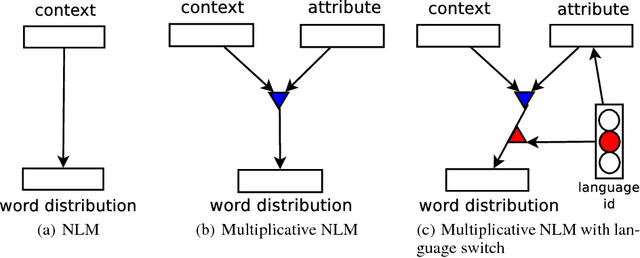

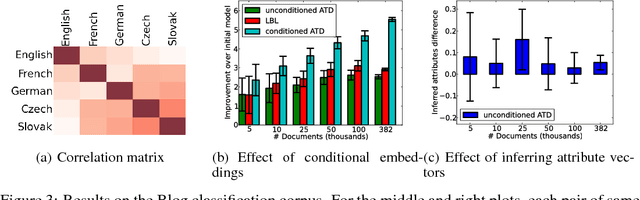

In this paper we propose a general framework for learning distributed representations of attributes: characteristics of text whose representations can be jointly learned with word embeddings. Attributes can correspond to document indicators (to learn sentence vectors), language indicators (to learn distributed language representations), meta-data and side information (such as the age, gender and industry of a blogger) or representations of authors. We describe a third-order model where word context and attribute vectors interact multiplicatively to predict the next word in a sequence. This leads to the notion of conditional word similarity: how meanings of words change when conditioned on different attributes. We perform several experimental tasks including sentiment classification, cross-lingual document classification, and blog authorship attribution. We also qualitatively evaluate conditional word neighbours and attribute-conditioned text generation.
Training Neural Networks with Stochastic Hessian-Free Optimization
May 01, 2013
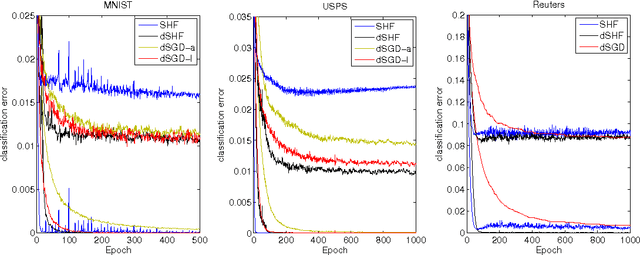
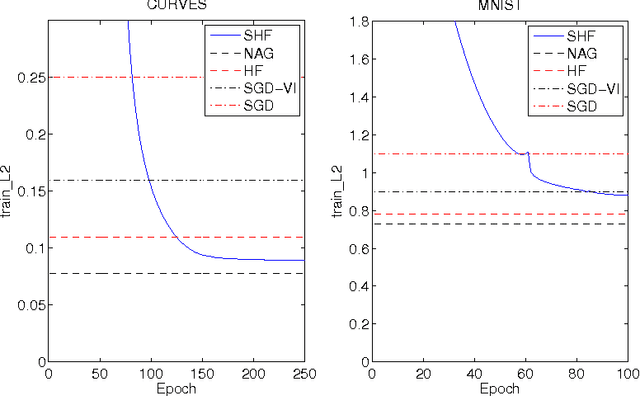
Hessian-free (HF) optimization has been successfully used for training deep autoencoders and recurrent networks. HF uses the conjugate gradient algorithm to construct update directions through curvature-vector products that can be computed on the same order of time as gradients. In this paper we exploit this property and study stochastic HF with gradient and curvature mini-batches independent of the dataset size. We modify Martens' HF for these settings and integrate dropout, a method for preventing co-adaptation of feature detectors, to guard against overfitting. Stochastic Hessian-free optimization gives an intermediary between SGD and HF that achieves competitive performance on both classification and deep autoencoder experiments.