Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks with Stochastic Hessian-Free Optimization
Paper and Code
May 01, 2013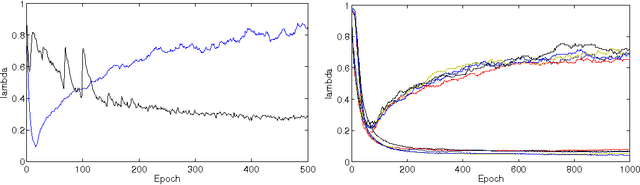
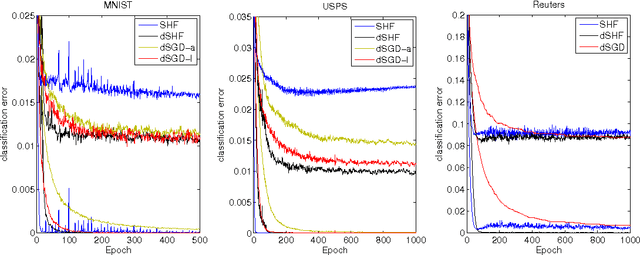
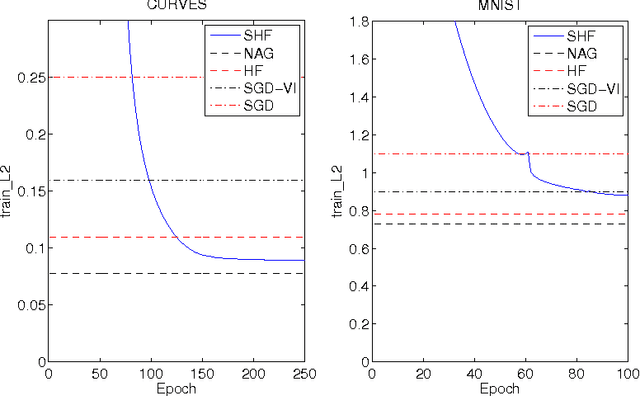
Hessian-free (HF) optimization has been successfully used for training deep autoencoders and recurrent networks. HF uses the conjugate gradient algorithm to construct update directions through curvature-vector products that can be computed on the same order of time as gradients. In this paper we exploit this property and study stochastic HF with gradient and curvature mini-batches independent of the dataset size. We modify Martens' HF for these settings and integrate dropout, a method for preventing co-adaptation of feature detectors, to guard against overfitting. Stochastic Hessian-free optimization gives an intermediary between SGD and HF that achieves competitive performance on both classification and deep autoencoder experiments.
* 11 pages, ICLR 2013
View paper on