 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-normal models for fMRI analysis
Nov 10, 2017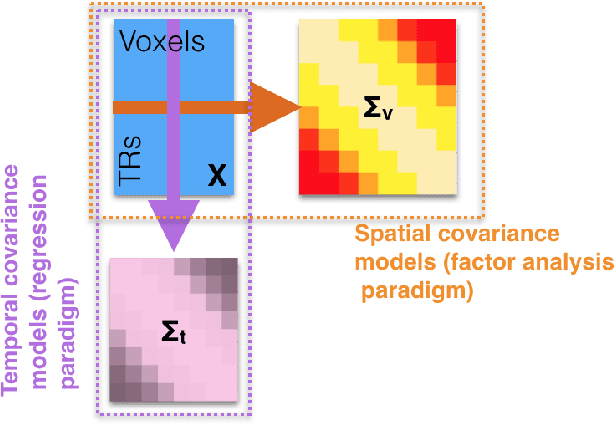

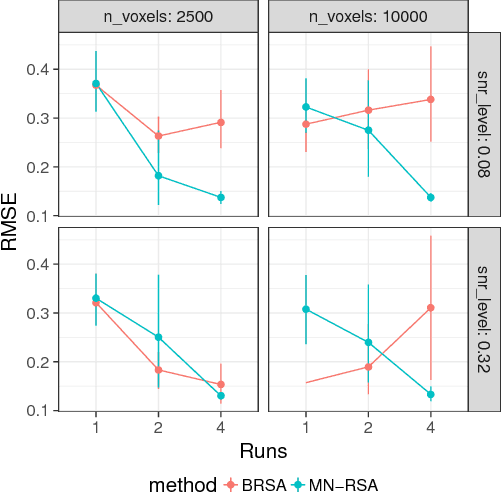
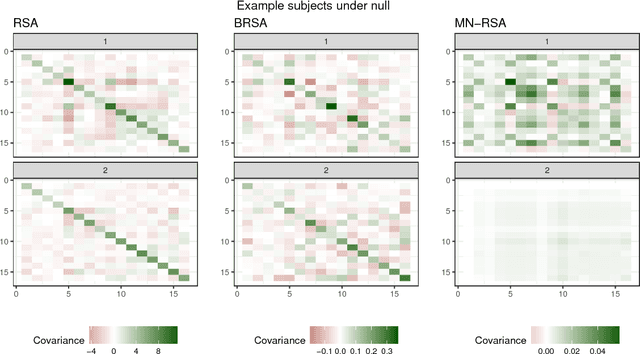
Multivariate analysis of fMRI data has benefited substantially from advances in machine learning. Most recently, a range of probabilistic latent variable models applied to fMRI data have been successful in a variety of tasks, including identifying similarity patterns in neural data (Representational Similarity Analysis and its empirical Bayes variant, RSA and BRSA; Intersubject Functional Connectivity, ISFC), combining multi-subject datasets (Shared Response Mapping; SRM), and mapping between brain and behavior (Joint Modeling). Although these methods share some underpinnings, they have been developed as distinct methods, with distinct algorithms and software tools. We show how the matrix-variate normal (MN) formalism can unify some of these methods into a single framework. In doing so, we gain the ability to reuse noise modeling assumptions, algorithms, and code across models. Our primary theoretical contribution shows how some of these methods can be written as instantiations of the same model, allowing us to generalize them to flexibly modeling structured noise covariances. Our formalism permits novel model variants and improved estimation strategies: in contrast to SRM, the number of parameters for MN-SRM does not scale with the number of voxels or subjects; in contrast to BRSA, the number of parameters for MN-RSA scales additively rather than multiplicatively in the number of voxels. We empirically demonstrate advantages of two new methods derived in the formalism: for MN-RSA, we show up to 10x improvement in runtime, up to 6x improvement in RMSE, and more conservative behavior under the null. For MN-SRM, our method grants a modest improvement to out-of-sample reconstruction while relaxing an orthonormality constraint of SRM. We also provide a software prototyping tool for MN models that can flexibly reuse noise covariance assumptions and algorithms across models.
Deep Learning at 15PF: Supervised and Semi-Supervised Classification for Scientific Data
Aug 17, 2017
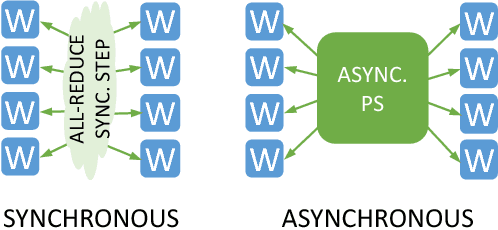
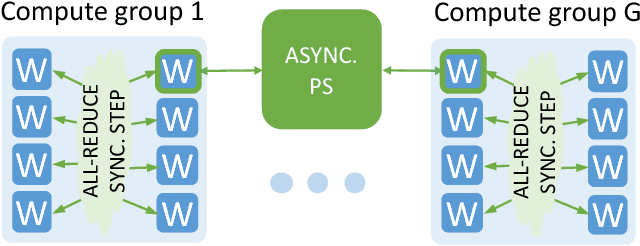
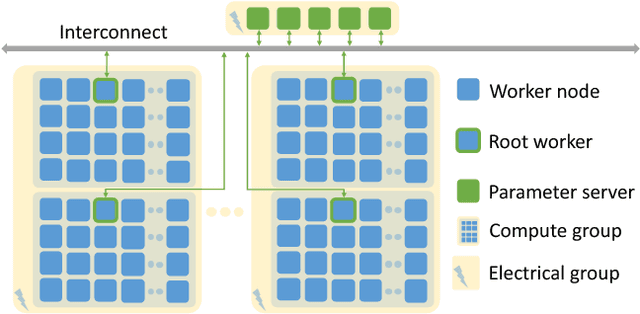
This paper presents the first, 15-PetaFLOP Deep Learning system for solving scientific pattern classification problems on contemporary HPC architectures. We develop supervised convolutional architectures for discriminating signals in high-energy physics data as well as semi-supervised architectures for localizing and classifying extreme weather in climate data. Our Intelcaffe-based implementation obtains $\sim$2TFLOP/s on a single Cori Phase-II Xeon-Phi node. We use a hybrid strategy employing synchronous node-groups, while using asynchronous communication across groups. We use this strategy to scale training of a single model to $\sim$9600 Xeon-Phi nodes; obtaining peak performance of 11.73-15.07 PFLOP/s and sustained performance of 11.41-13.27 PFLOP/s. At scale, our HEP architecture produces state-of-the-art classification accuracy on a dataset with 10M images, exceeding that achieved by selections on high-level physics-motivated features. Our semi-supervised architecture successfully extracts weather patterns in a 15TB climate dataset. Our results demonstrate that Deep Learning can be optimized and scaled effectively on many-core, HPC systems.
Scalable Bayesian Optimization Using Deep Neural Networks
Jul 13, 2015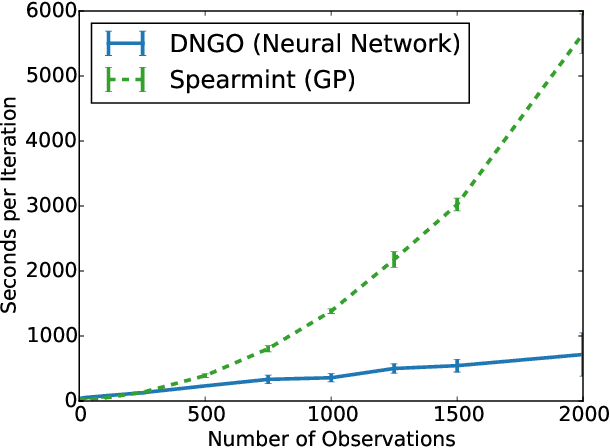
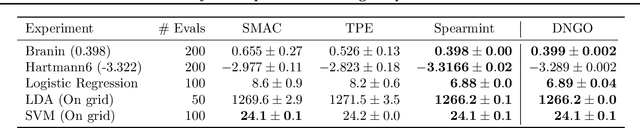
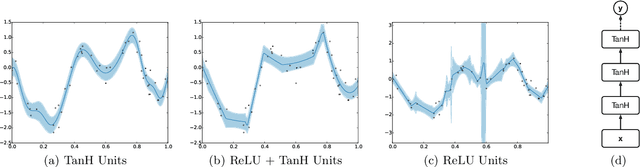

Bayesian optimization is an effective methodology for the global optimization of functions with expensive evaluations. It relies on querying a distribution over functions defined by a relatively cheap surrogate model. An accurate model for this distribution over functions is critical to the effectiveness of the approach, and is typically fit using Gaussian processes (GPs). However, since GPs scale cubically with the number of observations, it has been challenging to handle objectives whose optimization requires many evaluations, and as such, massively parallelizing the optimization. In this work, we explore the use of neural networks as an alternative to GPs to model distributions over functions. We show that performing adaptive basis function regression with a neural network as the parametric form performs competitively with state-of-the-art GP-based approaches, but scales linearly with the number of data rather than cubically. This allows us to achieve a previously intractable degree of parallelism, which we apply to large scale hyperparameter optimization, rapidly finding competitive models on benchmark object recognition tasks using convolutional networks, and image caption generation using neural language models.