 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSD-Imagery: A benchmark dataset for extending fMRI vision decoding methods to mental imagery
Jun 07, 2025We release NSD-Imagery, a benchmark dataset of human fMRI activity paired with mental images, to complement the existing Natural Scenes Dataset (NSD), a large-scale dataset of fMRI activity paired with seen images that enabled unprecedented improvements in fMRI-to-image reconstruction efforts. Recent models trained on NSD have been evaluated only on seen image reconstruction. Using NSD-Imagery, it is possible to assess how well these models perform on mental image reconstruction. This is a challenging generalization requirement because mental images are encoded in human brain activity with relatively lower signal-to-noise and spatial resolution; however, generalization from seen to mental imagery is critical for real-world applications in medical domains and brain-computer interfaces, where the desired information is always internally generated. We provide benchmarks for a suite of recent NSD-trained open-source visual decoding models (MindEye1, MindEye2, Brain Diffuser, iCNN, Takagi et al.) on NSD-Imagery, and show that the performance of decoding methods on mental images is largely decoupled from performance on vision reconstruction. We further demonstrate that architectural choices significantly impact cross-decoding performance: models employing simple linear decoding architectures and multimodal feature decoding generalize better to mental imagery, while complex architectures tend to overfit visual training data. Our findings indicate that mental imagery datasets are critical for the development of practical applications, and establish NSD-Imagery as a useful resource for better aligning visual decoding methods with this goal.
MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Mar 17, 2024Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
Brain-optimized inference improves reconstructions of fMRI brain activity
Dec 12, 2023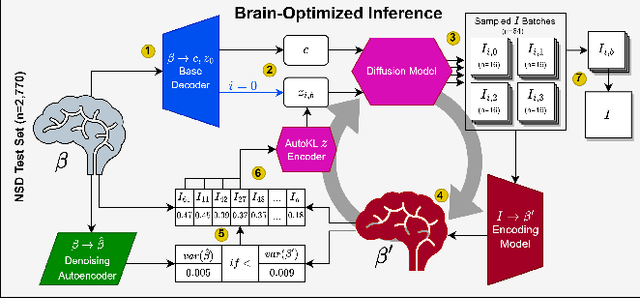
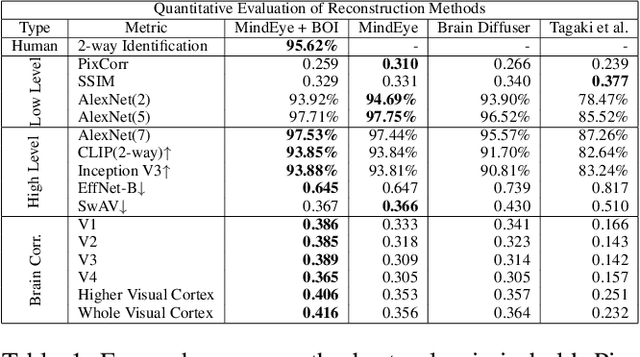
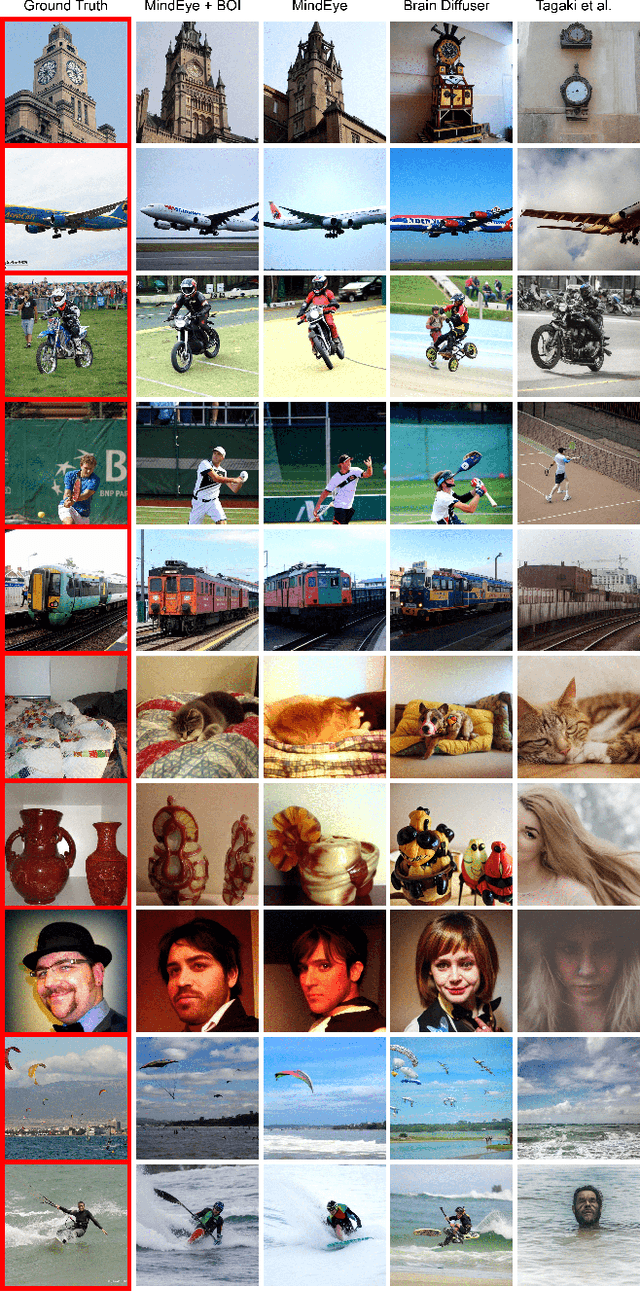

The release of large datasets and developments in AI have led to dramatic improvements in decoding methods that reconstruct seen images from human brain activity. We evaluate the prospect of further improving recent decoding methods by optimizing for consistency between reconstructions and brain activity during inference. We sample seed reconstructions from a base decoding method, then iteratively refine these reconstructions using a brain-optimized encoding model that maps images to brain activity. At each iteration, we sample a small library of images from an image distribution (a diffusion model) conditioned on a seed reconstruction from the previous iteration. We select those that best approximate the measured brain activity when passed through our encoding model, and use these images for structural guidance during the generation of the small library in the next iteration. We reduce the stochasticity of the image distribution at each iteration, and stop when a criterion on the "width" of the image distribution is met. We show that when this process is applied to recent decoding methods, it outperforms the base decoding method as measured by human raters, a variety of image feature metrics, and alignment to brain activity. These results demonstrate that reconstruction quality can be significantly improved by explicitly aligning decoding distributions to brain activity distributions, even when the seed reconstruction is output from a state-of-the-art decoding algorithm. Interestingly, the rate of refinement varies systematically across visual cortex, with earlier visual areas generally converging more slowly and preferring narrower image distributions, relative to higher-level brain areas. Brain-optimized inference thus offers a succinct and novel method for improving reconstructions and exploring the diversity of representations across visual brain areas.
Second Sight: Using brain-optimized encoding models to align image distributions with human brain activity
Jun 01, 2023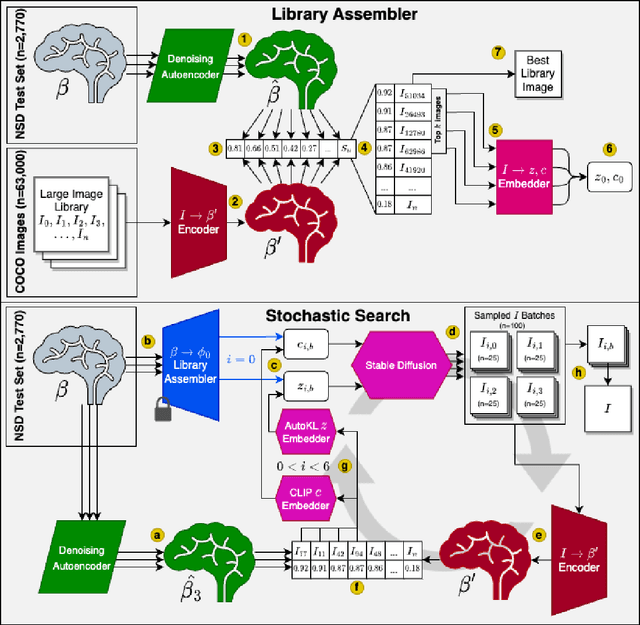
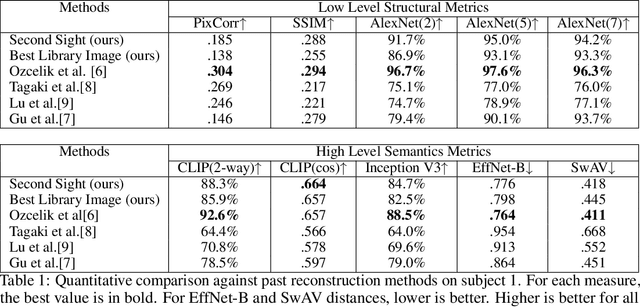


Two recent developments have accelerated progress in image reconstruction from human brain activity: large datasets that offer samples of brain activity in response to many thousands of natural scenes, and the open-sourcing of powerful stochastic image-generators that accept both low- and high-level guidance. Most work in this space has focused on obtaining point estimates of the target image, with the ultimate goal of approximating literal pixel-wise reconstructions of target images from the brain activity patterns they evoke. This emphasis belies the fact that there is always a family of images that are equally compatible with any evoked brain activity pattern, and the fact that many image-generators are inherently stochastic and do not by themselves offer a method for selecting the single best reconstruction from among the samples they generate. We introduce a novel reconstruction procedure (Second Sight) that iteratively refines an image distribution to explicitly maximize the alignment between the predictions of a voxel-wise encoding model and the brain activity patterns evoked by any target image. We show that our process converges on a distribution of high-quality reconstructions by refining both semantic content and low-level image details across iterations. Images sampled from these converged image distributions are competitive with state-of-the-art reconstruction algorithms. Interestingly, the time-to-convergence varies systematically across visual cortex, with earlier visual areas generally taking longer and converging on narrower image distributions, relative to higher-level brain areas. Second Sight thus offers a succinct and novel method for exploring the diversity of representations across visual brain areas.
Reconstructing seen images from human brain activity via guided stochastic search
May 02, 2023



Visual reconstruction algorithms are an interpretive tool that map brain activity to pixels. Past reconstruction algorithms employed brute-force search through a massive library to select candidate images that, when passed through an encoding model, accurately predict brain activity. Here, we use conditional generative diffusion models to extend and improve this search-based strategy. We decode a semantic descriptor from human brain activity (7T fMRI) in voxels across most of visual cortex, then use a diffusion model to sample a small library of images conditioned on this descriptor. We pass each sample through an encoding model, select the images that best predict brain activity, and then use these images to seed another library. We show that this process converges on high-quality reconstructions by refining low-level image details while preserving semantic content across iterations. Interestingly, the time-to-convergence differs systematically across visual cortex, suggesting a succinct new way to measure the diversity of representations across visual brain areas.