 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENIGMA: EEG-to-Image in 15 Minutes Using Less Than 1% of the Parameters
Feb 10, 2026To be practical for real-life applications, models for brain-computer interfaces must be easily and quickly deployable on new subjects, effective on affordable scanning hardware, and small enough to run locally on accessible computing resources. To directly address these current limitations, we introduce ENIGMA, a multi-subject electroencephalography (EEG)-to-Image decoding model that reconstructs seen images from EEG recordings and achieves state-of-the-art (SOTA) performance on the research-grade THINGS-EEG2 and consumer-grade AllJoined-1.6M benchmarks, while fine-tuning effectively on new subjects with as little as 15 minutes of data. ENIGMA boasts a simpler architecture and requires less than 1% of the trainable parameters necessary for previous approaches. Our approach integrates a subject-unified spatio-temporal backbone along with a set of multi-subject latent alignment layers and an MLP projector to map raw EEG signals to a rich visual latent space. We evaluate our approach using a broad suite of image reconstruction metrics that have been standardized in the adjacent field of fMRI-to-Image research, and we describe the first EEG-to-Image study to conduct extensive behavioral evaluations of our reconstructions using human raters. Our simple and robust architecture provides a significant performance boost across both research-grade and consumer-grade EEG hardware, and a substantial improvement in fine-tuning efficiency and inference cost. Finally, we provide extensive ablations to determine the architectural choices most responsible for our performance gains in both single and multi-subject cases across multiple benchmark datasets. Collectively, our work provides a substantial step towards the development of practical brain-computer interface applications.
Progress Towards Decoding Visual Imagery via fNIRS
Jun 11, 2024
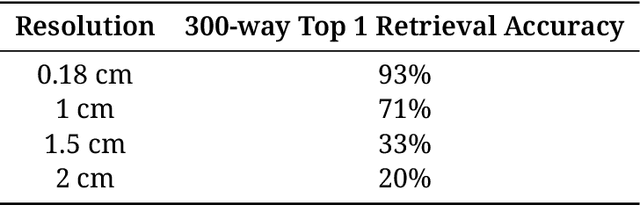

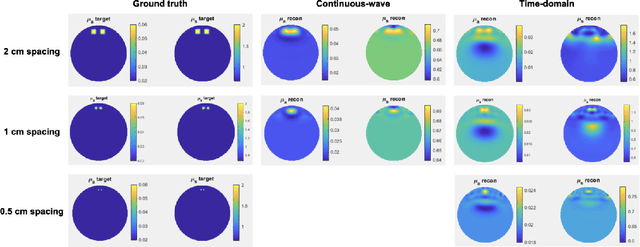
We demonstrate the possibility of reconstructing images from fNIRS brain activity and start building a prototype to match the required specs. By training an image reconstruction model on downsampled fMRI data, we discovered that cm-scale spatial resolution is sufficient for image generation. We obtained 71% retrieval accuracy with 1-cm resolution, compared to 93% on the full-resolution fMRI, and 20% with 2-cm resolution. With simulations and high-density tomography, we found that time-domain fNIRS can achieve 1-cm resolution, compared to 2-cm resolution for continuous-wave fNIRS. Lastly, we share designs for a prototype time-domain fNIRS device, consisting of a laser driver, a single photon detector, and a time-to-digital converter system.
Alljoined -- A dataset for EEG-to-Image decoding
Apr 08, 2024We present Alljoined, a dataset built specifically for EEG-to-Image decoding. Recognizing that an extensive and unbiased sampling of neural responses to visual stimuli is crucial for image reconstruction efforts, we collected data from 8 participants looking at 10,000 natural images each. We have currently gathered 46,080 epochs of brain responses recorded with a 64-channel EEG headset. The dataset combines response-based stimulus timing, repetition between blocks and sessions, and diverse image classes with the goal of improving signal quality. For transparency, we also provide data quality scores. We publicly release the dataset and all code at https://linktr.ee/alljoined1.
MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Mar 17, 2024Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
HarvestNet: A Dataset for Detecting Smallholder Farming Activity Using Harvest Piles and Remote Sensing
Aug 23, 2023
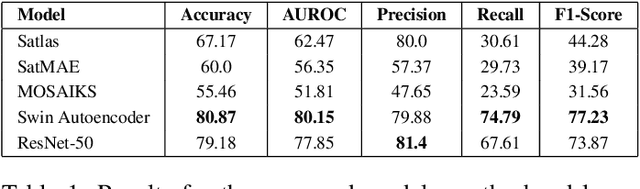


Small farms contribute to a large share of the productive land in developing countries. In regions such as sub-Saharan Africa, where 80% of farms are small (under 2 ha in size), the task of mapping smallholder cropland is an important part of tracking sustainability measures such as crop productivity. However, the visually diverse and nuanced appearance of small farms has limited the effectiveness of traditional approaches to cropland mapping. Here we introduce a new approach based on the detection of harvest piles characteristic of many smallholder systems throughout the world. We present HarvestNet, a dataset for mapping the presence of farms in the Ethiopian regions of Tigray and Amhara during 2020-2023, collected using expert knowledge and satellite images, totaling 7k hand-labeled images and 2k ground collected labels. We also benchmark a set of baselines including SOTA models in remote sensing with our best models having around 80% classification performance on hand labelled data and 90%, 98% accuracy on ground truth data for Tigray, Amhara respectively. We also perform a visual comparison with a widely used pre-existing coverage map and show that our model detects an extra 56,621 hectares of cropland in Tigray. We conclude that remote sensing of harvest piles can contribute to more timely and accurate cropland assessments in food insecure region.