 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a More Biologically Plausible Neural Network Model of Latent Cause Inference
Dec 13, 2023Humans spontaneously perceive a continuous stream of experience as discrete events. It has been hypothesized that this ability is supported by latent cause inference (LCI). We implemented this hypothesis using Latent Cause Network (LCNet), a neural network model of LCI. LCNet interacts with a Bayesian LCI mechanism that activates a unique context vector for each inferred latent cause. This architecture makes LCNet more biologically plausible than existing models of LCI and supports extraction of shared structure across latent causes. Across three simulations, we found that LCNet could 1) extract shared structure across latent causes in a function-learning task while avoiding catastrophic interference, 2) capture human data on curriculum effects in schema learning, and 3) infer the underlying event structure when processing naturalistic videos of daily activities. Our work provides a biologically plausible computational model that can operate in both laboratory experiment settings and naturalistic settings, opening up the possibility of providing a unified model of event cognition.
Learning to Apply Schematic Knowledge to Novel Instances
Feb 24, 2019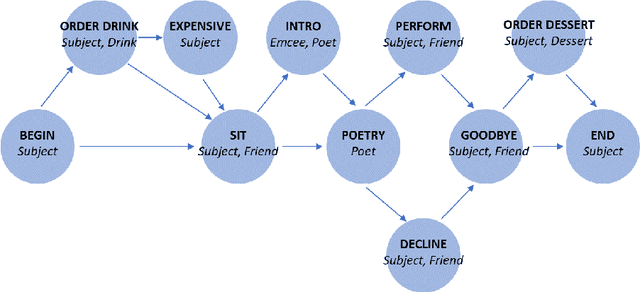


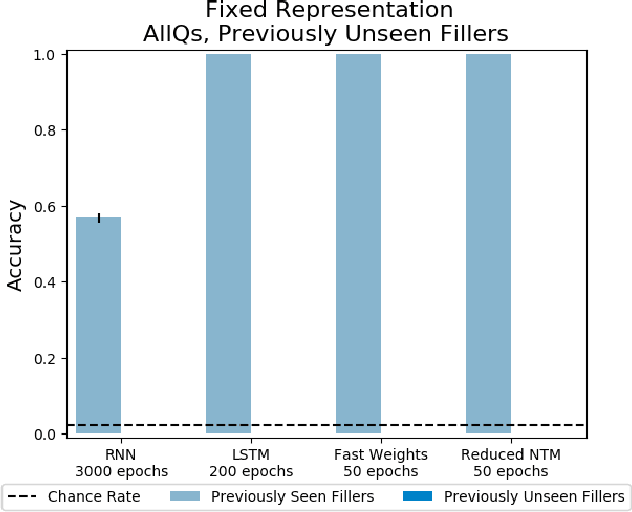
Humans have schematic knowledge of how certain types of events unfold (e.g. coffeeshop visits) that can readily be generalized to new instances of those events. Schematic knowledge allows humans to perform role-filler binding, the task of associating schematic roles (e.g. "barista") with specific fillers (e.g. "Bob"). Here we examined whether and how recurrent neural networks learn to do this. We procedurally generated stories from an underlying generative graph, and trained networks on role-filler binding question-answering tasks. We tested whether networks can learn to maintain filler information on their own, and whether they can generalize to fillers that they have not seen before. We studied networks by analyzing their behavior and decoding their memory states. We found that a network's success in learning role-filler binding depends on both the breadth of roles introduced during training, and the network's memory architecture. In our decoding analyses, we observed a close relationship between the information we could decode from various parts of network architecture, and the information the network could recall.
Shared Representational Geometry Across Neural Networks
Nov 28, 2018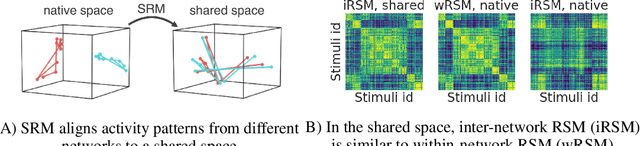
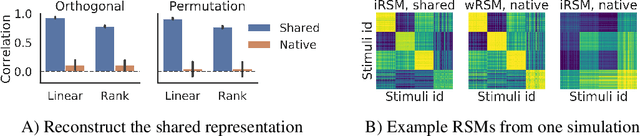
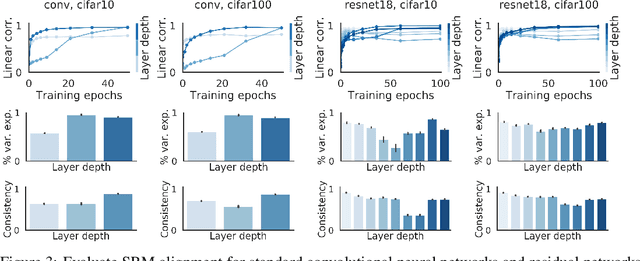
Different neural networks trained on the same dataset often learn similar input-output mappings with very different weights. Is there some correspondence between these neural network solutions? For linear networks, it has been shown that different instances of the same network architecture encode the same representational similarity matrix, and their neural activity patterns are connected by orthogonal transformations. However, it is unclear if this holds for non-linear networks. Using a shared response model, we show that different neural networks encode the same input examples as different orthogonal transformations of an underlying shared representation. We test this claim using both standard convolutional neural networks and residual networks on CIFAR10 and CIFAR100.