 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliniChat: A Multi-Source Knowledge-Driven Framework for Clinical Interview Dialogue Reconstruction and Evaluation
Paper and Code
Apr 14, 2025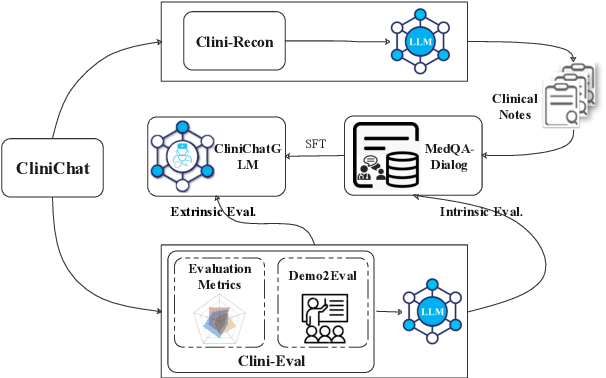

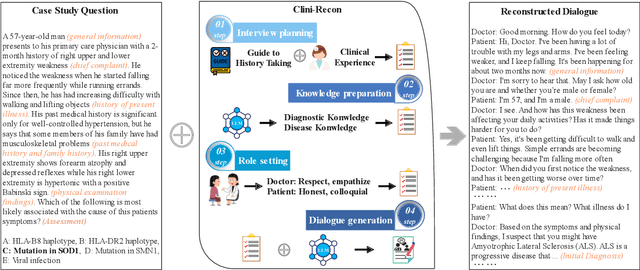
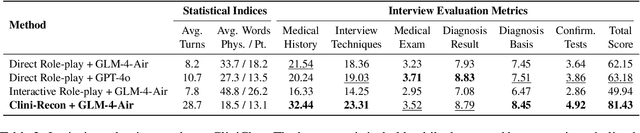
Large language models (LLMs) hold great promise for assisting clinical interviews due to their fluent interactive capabilities and extensive medical knowledge. However, the lack of high-quality interview dialogue data and widely accepted evaluation methods has significantly impeded this process. So we propose CliniChat, a framework that integrates multi-source knowledge to enable LLMs to simulate real-world clinical interviews. It consists of two modules: Clini-Recon and Clini-Eval, each responsible for reconstructing and evaluating interview dialogues, respectively. By incorporating three sources of knowledge, Clini-Recon transforms clinical notes into systematic, professional, and empathetic interview dialogues. Clini-Eval combines a comprehensive evaluation metric system with a two-phase automatic evaluation approach, enabling LLMs to assess interview performance like experts. We contribute MedQA-Dialog, a high-quality synthetic interview dialogue dataset, and CliniChatGLM, a model specialized for clinical interviews. Experimental results demonstrate that CliniChatGLM's interview capabilities undergo a comprehensive upgrade, particularly in history-taking, achieving state-of-the-art performance.