 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid CNN and ML Framework for Multi-modal Classification of Movement Disorders Using MRI and Brain Structural Features
Feb 05, 2026Atypical Parkinsonian Disorders (APD), also known as Parkinson-plus syndrome, are a group of neurodegenerative diseases that include progressive supranuclear palsy (PSP) and multiple system atrophy (MSA). In the early stages, overlapping clinical features often lead to misdiagnosis as Parkinson's disease (PD). Identifying reliable imaging biomarkers for early differential diagnosis remains a critical challenge. In this study, we propose a hybrid framework combining convolutional neural networks (CNNs) with machine learning (ML) techniques to classify APD subtypes versus PD and distinguish between the subtypes themselves: PSP vs. PD, MSA vs. PD, and PSP vs. MSA. The model leverages multi-modal input data, including T1-weighted magnetic resonance imaging (MRI), segmentation masks of 12 deep brain structures associated with APD, and their corresponding volumetric measurements. By integrating these complementary modalities, including image data, structural segmentation masks, and quantitative volume features, the hybrid approach achieved promising classification performance with area under the curve (AUC) scores of 0.95 for PSP vs. PD, 0.86 for MSA vs. PD, and 0.92 for PSP vs. MSA. These results highlight the potential of combining spatial and structural information for robust subtype differentiation. In conclusion, this study demonstrates that fusing CNN-based image features with volume-based ML inputs improves classification accuracy for APD subtypes. The proposed approach may contribute to more reliable early-stage diagnosis, facilitating timely and targeted interventions in clinical practice.
TUMTraf EMOT: Event-Based Multi-Object Tracking Dataset and Baseline for Traffic Scenarios
Dec 20, 2025In Intelligent Transportation Systems (ITS), multi-object tracking is primarily based on frame-based cameras. However, these cameras tend to perform poorly under dim lighting and high-speed motion conditions. Event cameras, characterized by low latency, high dynamic range and high temporal resolution, have considerable potential to mitigate these issues. Compared to frame-based vision, there are far fewer studies on event-based vision. To address this research gap, we introduce an initial pilot dataset tailored for event-based ITS, covering vehicle and pedestrian detection and tracking. We establish a tracking-by-detection benchmark with a specialized feature extractor based on this dataset, achieving excellent performance.
A more efficient method for large-sample model-free feature screening via multi-armed bandits
Sep 19, 2025



We consider the model-free feature screening in large-scale ultrahigh-dimensional data analysis. Existing feature screening methods often face substantial computational challenges when dealing with large sample sizes. To alleviate the computational burden, we propose a rank-based model-free sure independence screening method (CR-SIS) and its efficient variant, BanditCR-SIS. The CR-SIS method, based on Chatterjee's rank correlation, is as straightforward to implement as the sure independence screening (SIS) method based on Pearson correlation introduced by Fan and Lv(2008), but it is significantly more powerful in detecting nonlinear relationships between variables. Motivated by the multi-armed bandit (MAB) problem, we reformulate the feature screening procedure to significantly reduce the computational complexity of CR-SIS. For a predictor matrix of size n \times p, the computational cost of CR-SIS is O(nlog(n)p), while BanditCR-SIS reduces this to O(\sqrt(n)log(n)p + nlog(n)). Theoretically, we establish the sure screening property for both CR-SIS and BanditCR-SIS under mild regularity conditions. Furthermore, we demonstrate the effectiveness of our methods through extensive experimental studies on both synthetic and real-world datasets. The results highlight their superior performance compared to classical screening methods, requiring significantly less computational time.
Gaussian Herding across Pens: An Optimal Transport Perspective on Global Gaussian Reduction for 3DGS
Jun 11, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful technique for radiance field rendering, but it typically requires millions of redundant Gaussian primitives, overwhelming memory and rendering budgets. Existing compaction approaches address this by pruning Gaussians based on heuristic importance scores, without global fidelity guarantee. To bridge this gap, we propose a novel optimal transport perspective that casts 3DGS compaction as global Gaussian mixture reduction. Specifically, we first minimize the composite transport divergence over a KD-tree partition to produce a compact geometric representation, and then decouple appearance from geometry by fine-tuning color and opacity attributes with far fewer Gaussian primitives. Experiments on benchmark datasets show that our method (i) yields negligible loss in rendering quality (PSNR, SSIM, LPIPS) compared to vanilla 3DGS with only 10% Gaussians; and (ii) consistently outperforms state-of-the-art 3DGS compaction techniques. Notably, our method is applicable to any stage of vanilla or accelerated 3DGS pipelines, providing an efficient and agnostic pathway to lightweight neural rendering.
Dual-level Mixup for Graph Few-shot Learning with Fewer Tasks
Feb 19, 2025



Graph neural networks have been demonstrated as a powerful paradigm for effectively learning graph-structured data on the web and mining content from it.Current leading graph models require a large number of labeled samples for training, which unavoidably leads to overfitting in few-shot scenarios. Recent research has sought to alleviate this issue by simultaneously leveraging graph learning and meta-learning paradigms. However, these graph meta-learning models assume the availability of numerous meta-training tasks to learn transferable meta-knowledge. Such assumption may not be feasible in the real world due to the difficulty of constructing tasks and the substantial costs involved. Therefore, we propose a SiMple yet effectIve approach for graph few-shot Learning with fEwer tasks, named SMILE. We introduce a dual-level mixup strategy, encompassing both within-task and across-task mixup, to simultaneously enrich the available nodes and tasks in meta-learning. Moreover, we explicitly leverage the prior information provided by the node degrees in the graph to encode expressive node representations. Theoretically, we demonstrate that SMILE can enhance the model generalization ability. Empirically, SMILE consistently outperforms other competitive models by a large margin across all evaluated datasets with in-domain and cross-domain settings. Our anonymous code can be found here.
Boosting Short Text Classification with Multi-Source Information Exploration and Dual-Level Contrastive Learning
Jan 16, 2025



Short text classification, as a research subtopic in natural language processing, is more challenging due to its semantic sparsity and insufficient labeled samples in practical scenarios. We propose a novel model named MI-DELIGHT for short text classification in this work. Specifically, it first performs multi-source information (i.e., statistical information, linguistic information, and factual information) exploration to alleviate the sparsity issues. Then, the graph learning approach is adopted to learn the representation of short texts, which are presented in graph forms. Moreover, we introduce a dual-level (i.e., instance-level and cluster-level) contrastive learning auxiliary task to effectively capture different-grained contrastive information within massive unlabeled data. Meanwhile, previous models merely perform the main task and auxiliary tasks in parallel, without considering the relationship among tasks. Therefore, we introduce a hierarchical architecture to explicitly model the correlations between tasks. We conduct extensive experiments across various benchmark datasets, demonstrating that MI-DELIGHT significantly surpasses previous competitive models. It even outperforms popular large language models on several datasets.
ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities
Aug 08, 2024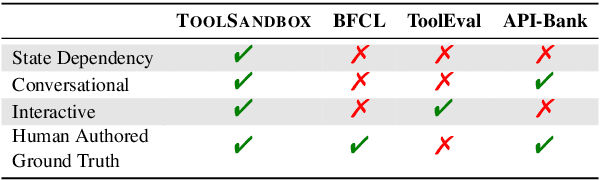
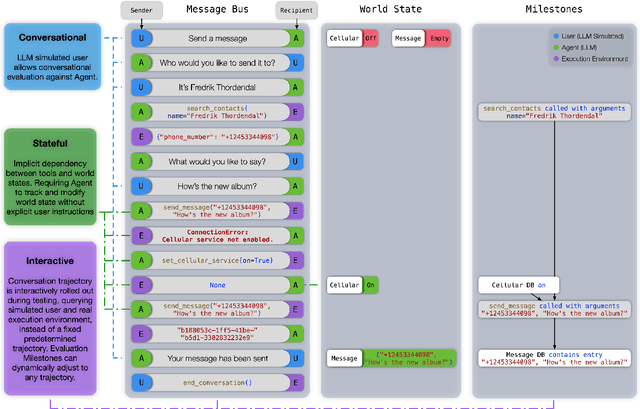
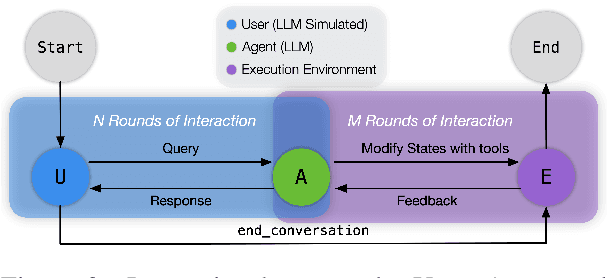
Recent large language models (LLMs) advancements sparked a growing research interest in tool assisted LLMs solving real-world challenges, which calls for comprehensive evaluation of tool-use capabilities. While previous works focused on either evaluating over stateless web services (RESTful API), based on a single turn user prompt, or an off-policy dialog trajectory, ToolSandbox includes stateful tool execution, implicit state dependencies between tools, a built-in user simulator supporting on-policy conversational evaluation and a dynamic evaluation strategy for intermediate and final milestones over an arbitrary trajectory. We show that open source and proprietary models have a significant performance gap, and complex tasks like State Dependency, Canonicalization and Insufficient Information defined in ToolSandbox are challenging even the most capable SOTA LLMs, providing brand-new insights into tool-use LLM capabilities. ToolSandbox evaluation framework is released at https://github.com/apple/ToolSandbox
Meta-GPS++: Enhancing Graph Meta-Learning with Contrastive Learning and Self-Training
Jul 20, 2024



Node classification is an essential problem in graph learning. However, many models typically obtain unsatisfactory performance when applied to few-shot scenarios. Some studies have attempted to combine meta-learning with graph neural networks to solve few-shot node classification on graphs. Despite their promising performance, some limitations remain. First, they employ the node encoding mechanism of homophilic graphs to learn node embeddings, even in heterophilic graphs. Second, existing models based on meta-learning ignore the interference of randomness in the learning process. Third, they are trained using only limited labeled nodes within the specific task, without explicitly utilizing numerous unlabeled nodes. Finally, they treat almost all sampled tasks equally without customizing them for their uniqueness. To address these issues, we propose a novel framework for few-shot node classification called Meta-GPS++. Specifically, we first adopt an efficient method to learn discriminative node representations on homophilic and heterophilic graphs. Then, we leverage a prototype-based approach to initialize parameters and contrastive learning for regularizing the distribution of node embeddings. Moreover, we apply self-training to extract valuable information from unlabeled nodes. Additionally, we adopt S$^2$ (scaling & shifting) transformation to learn transferable knowledge from diverse tasks. The results on real-world datasets show the superiority of Meta-GPS++. Our code is available here.
Magnetic Resonance Image Processing Transformer for General Reconstruction
May 23, 2024



Purpose: To develop and evaluate a deep learning model for general accelerated MRI reconstruction. Materials and Methods: This retrospective study built a magnetic resonance image processing transformer (MR-IPT) which includes multi-head-tails and a single shared window transformer main body. Three mutations of MR-IPT with different transformer structures were implemented to guide the design of our MR-IPT model. Pre-trained on the MRI set of RadImageNet including 672675 images with multiple anatomy categories, the model was further migrated and evaluated on fastMRI knee dataset with 25012 images for downstream reconstruction tasks. We performed comparison studies with three CNN-based conventional networks in zero- and few-shot learning scenarios. Transfer learning process was conducted on both MR-IPT and CNN networks to further validate the generalizability of MR-IPT. To study the model performance stability, we evaluated our model with various downstream dataset sizes ranging from 10 to 2500 images. Result: The MR-IPT model provided superior performance in multiple downstream tasks compared to conventional CNN networks. MR-IPT achieved a PSNR/SSIM of 26.521/0.6102 (4-fold) and 24.861/0.4996 (8-fold) in 10-epoch learning, surpassing UNet128 at 25.056/0.5832 (4-fold) and 22.984/0.4637 (8-fold). With the same large-scale pre-training, MR-IPT provided a 5% performance boost compared to UNet128 in zero-shot learning in 8-fold and 3% in 4-fold. Conclusion: MR-IPT framework benefits from its transformer-based structure and large-scale pre-training and can serve as a solid backbone in other downstream tasks with zero- and few-shot learning.
Resolving Word Vagueness with Scenario-guided Adapter for Natural Language Inference
May 21, 2024


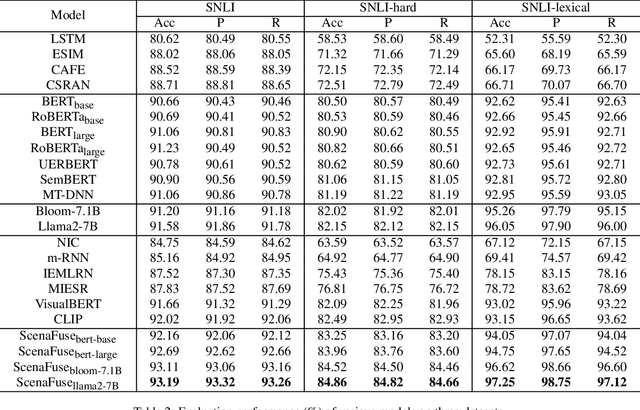
Natural Language Inference (NLI) is a crucial task in natural language processing that involves determining the relationship between two sentences, typically referred to as the premise and the hypothesis. However, traditional NLI models solely rely on the semantic information inherent in independent sentences and lack relevant situational visual information, which can hinder a complete understanding of the intended meaning of the sentences due to the ambiguity and vagueness of language. To address this challenge, we propose an innovative ScenaFuse adapter that simultaneously integrates large-scale pre-trained linguistic knowledge and relevant visual information for NLI tasks. Specifically, we first design an image-sentence interaction module to incorporate visuals into the attention mechanism of the pre-trained model, allowing the two modalities to interact comprehensively. Furthermore, we introduce an image-sentence fusion module that can adaptively integrate visual information from images and semantic information from sentences. By incorporating relevant visual information and leveraging linguistic knowledge, our approach bridges the gap between language and vision, leading to improved understanding and inference capabilities in NLI tasks. Extensive benchmark experiments demonstrate that our proposed ScenaFuse, a scenario-guided approach, consistently boosts NLI performance.