 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHVI-FDD: A Hierarchical Decoupling Framework for Low-Light Image Enhancement
Apr 07, 2026Low-light images often suffer from severe noise, detail loss, and color distortion, which hinder downstream multimedia analysis and retrieval tasks. The degradation in low-light images is complex: luminance and chrominance are coupled, while within the chrominance, noise and details are deeply entangled, preventing existing methods from simultaneously correcting color distortion, suppressing noise, and preserving fine details. To tackle the above challenges, we propose a novel hierarchical decoupling framework (RHVI-FDD). At the macro level, we introduce the RHVI transform, which mitigates the estimation bias caused by input noise and enables robust luminance-chrominance decoupling. At the micro level, we design a Frequency-Domain Decoupling (FDD) module with three branches for further feature separation. Using the Discrete Cosine Transform, we decompose chrominance features into low, mid, and high-frequency bands that predominantly represent global tone, local details, and noise components, which are then processed by tailored expert networks in a divide-and-conquer manner and fused via an adaptive gating module for content-aware fusion. Extensive experiments on multiple low-light datasets demonstrate that our method consistently outperforms existing state-of-the-art approaches in both objective metrics and subjective visual quality.
Meta-GPS++: Enhancing Graph Meta-Learning with Contrastive Learning and Self-Training
Jul 20, 2024



Node classification is an essential problem in graph learning. However, many models typically obtain unsatisfactory performance when applied to few-shot scenarios. Some studies have attempted to combine meta-learning with graph neural networks to solve few-shot node classification on graphs. Despite their promising performance, some limitations remain. First, they employ the node encoding mechanism of homophilic graphs to learn node embeddings, even in heterophilic graphs. Second, existing models based on meta-learning ignore the interference of randomness in the learning process. Third, they are trained using only limited labeled nodes within the specific task, without explicitly utilizing numerous unlabeled nodes. Finally, they treat almost all sampled tasks equally without customizing them for their uniqueness. To address these issues, we propose a novel framework for few-shot node classification called Meta-GPS++. Specifically, we first adopt an efficient method to learn discriminative node representations on homophilic and heterophilic graphs. Then, we leverage a prototype-based approach to initialize parameters and contrastive learning for regularizing the distribution of node embeddings. Moreover, we apply self-training to extract valuable information from unlabeled nodes. Additionally, we adopt S$^2$ (scaling & shifting) transformation to learn transferable knowledge from diverse tasks. The results on real-world datasets show the superiority of Meta-GPS++. Our code is available here.
Troublemaker Learning for Low-Light Image Enhancement
Feb 07, 2024



Low-light image enhancement (LLIE) restores the color and brightness of underexposed images. Supervised methods suffer from high costs in collecting low/normal-light image pairs. Unsupervised methods invest substantial effort in crafting complex loss functions. We address these two challenges through the proposed TroubleMaker Learning (TML) strategy, which employs normal-light images as inputs for training. TML is simple: we first dim the input and then increase its brightness. TML is based on two core components. First, the troublemaker model (TM) constructs pseudo low-light images from normal images to relieve the cost of pairwise data. Second, the predicting model (PM) enhances the brightness of pseudo low-light images. Additionally, we incorporate an enhancing model (EM) to further improve the visual performance of PM outputs. Moreover, in LLIE tasks, characterizing global element correlations is important because more information on the same object can be captured. CNN cannot achieve this well, and self-attention has high time complexity. Accordingly, we propose Global Dynamic Convolution (GDC) with O(n) time complexity, which essentially imitates the partial calculation process of self-attention to formulate elementwise correlations. Based on the GDC module, we build the UGDC model. Extensive quantitative and qualitative experiments demonstrate that UGDC trained with TML can achieve competitive performance against state-of-the-art approaches on public datasets. The code is available at https://github.com/Rainbowman0/TML_LLIE.
Reinforcement Learning-based Non-Autoregressive Solver for Traveling Salesman Problems
Aug 01, 2023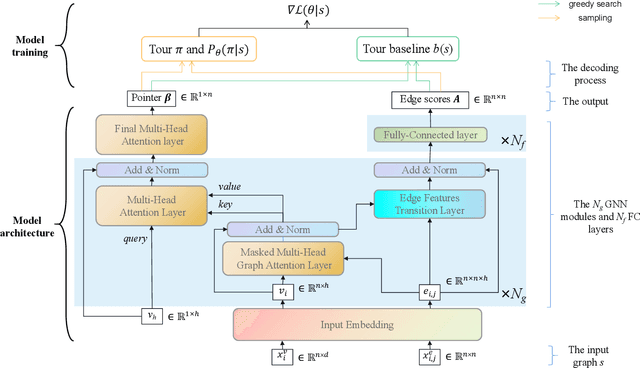

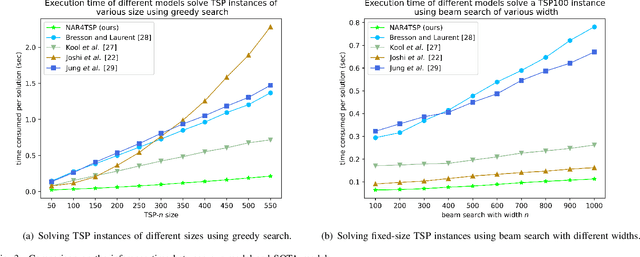
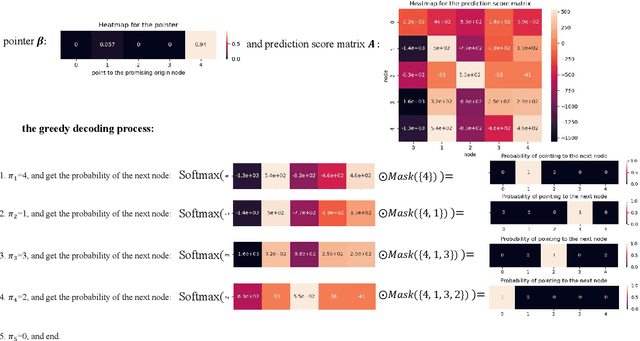
The Traveling Salesman Problem (TSP) is a well-known problem in combinatorial optimization with applications in various domains. However, existing TSP solvers face challenges in producing high-quality solutions with low latency. To address this issue, we propose NAR4TSP, which produces TSP solutions in a Non-Autoregressive (NAR) manner using a specially designed Graph Neural Network (GNN), achieving faster inference speed. Moreover, NAR4TSP is trained using an enhanced Reinforcement Learning (RL) strategy, eliminating the dependency on costly labels used to train conventional supervised learning-based NAR models. To the best of our knowledge, NAR4TSP is the first TSP solver that successfully combines RL and NAR decoding. The experimental results on both synthetic and real-world TSP instances demonstrate that NAR4TSP outperforms four state-of-the-art models in terms of solution quality, inference latency, and generalization ability. Lastly, we present visualizations of NAR4TSP's decoding process and its overall path planning to showcase the feasibility of implementing NAR4TSP in an end-to-end manner and its effectiveness, respectively.
Surprisingly Popular Algorithm-based Adaptive Euclidean Distance Topology Learning PSO
Aug 25, 2021



The surprisingly popular algorithm (SPA) is a powerful crowd decision model proposed in social science, which can identify the knowledge possessed in of the minority. We have modelled the SPA to select the exemplars in PSO scenarios and proposed the Surprisingly Popular Algorithm-based Comprehensive Adaptive Topology Learning Particle Swarm Optimization. Due to the significant influence of the communication topology on exemplar selection, we propose an adaptive euclidean distance dynamic topology maintenance. And then we propose the Surprisingly Popular Algorithm-based Adaptive Euclidean Distance Topology Learning Particle Swarm Optimization (SpadePSO), which use SPA to guide the direction of the exploitation sub-population. We analyze the influence of different topologies on the SPA. We evaluate the proposed SpadePSO on the full CEC2014 benchmark suite, the spread spectrum radar polyphase coding design and the ordinary differential equations models inference. The experimental results on the full CEC2014 benchmark suite show that the SpadePSO is competitive with PSO, OLPSO, HCLPSO, GL-PSO, TSLPSO and XPSO. The mean and standard deviation of SpadePSO are lower than the other PSO variants on the spread spectrum radar polyphase coding design. Finally, the ordinary differential equations models' inference results show that SpadePSO performs better than LatinPSO, specially designed for this problem. SpadePSO has lower requirements for population number than LatinPSO.
Neural Architecture Search based on Cartesian Genetic Programming Coding Method
Mar 12, 2021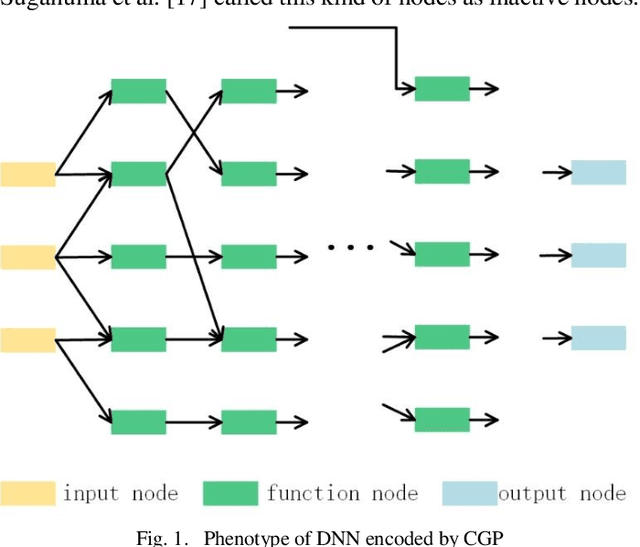
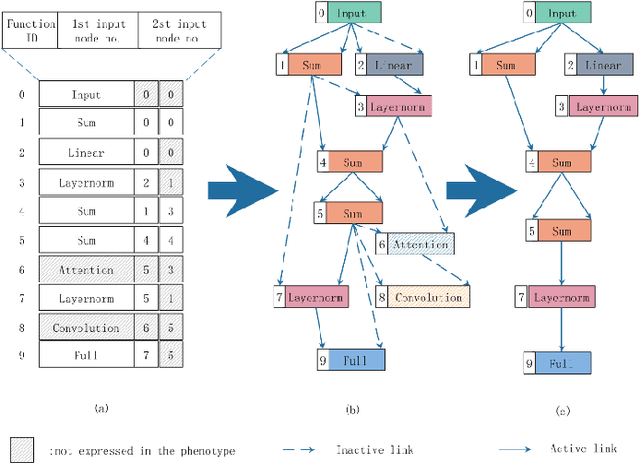
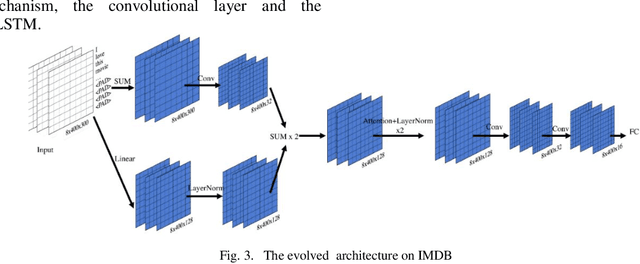
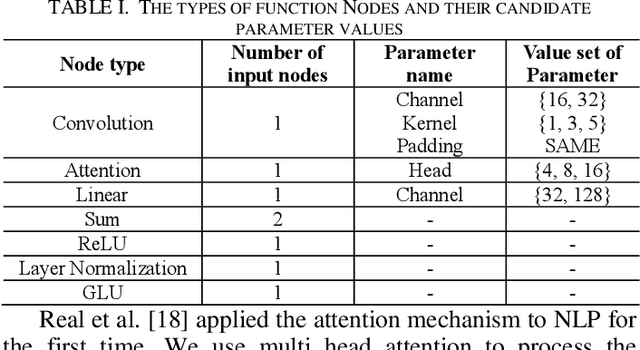
Neural architecture search (NAS) is a hot topic in the field of AutoML, and has begun to outperform human-designed architectures on many machine learning tasks. Motivated by the natural representation form of neural networks by the Cartesian genetic programming (CGP), we propose an evolutionary approach of NAS based on CGP, called CPGNAS, for CNN architectures solving sentence classification task. To evolve the CNN architectures under the framework of CGP, the existing key operations are identified as the types of function nodes of CGP and the evolutionary operations are designed based on evolutionary strategy (ES). The experimental results show that the searched architecture can reach the accuracy of human-designed architectures. The ablation tests identify the Attention function as the single key function node and the Convolution and Attention as the joint key function nodes. However, the linear transformations along could keep the accuracy of evolved architectures over 70%, which is worth of investigating in the future.
Deep Learning Analysis and Age Prediction from Shoeprints
Nov 07, 2020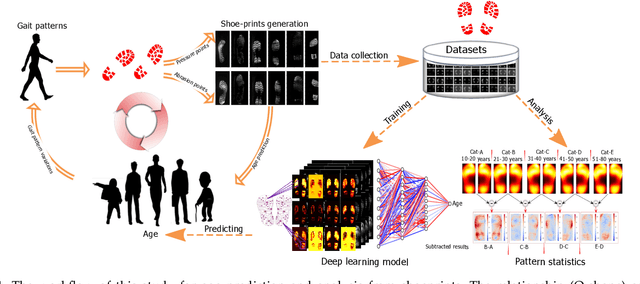
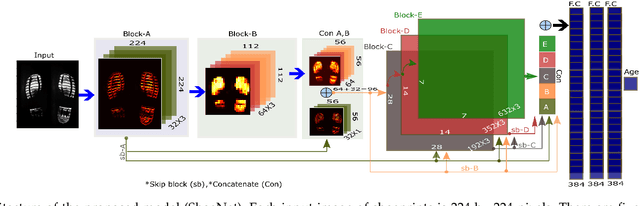
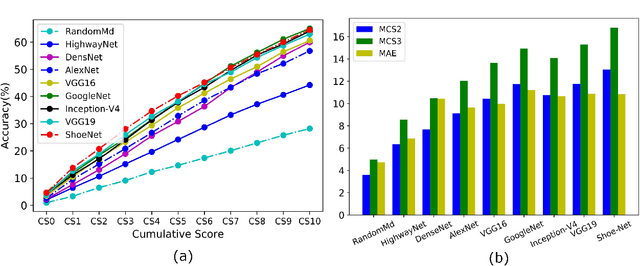
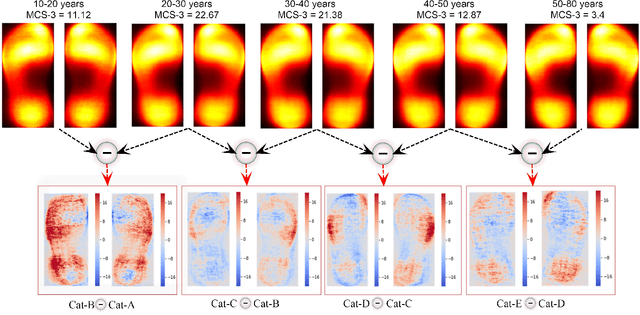
Human walking and gaits involve several complex body parts and are influenced by personality, mood, social and cultural traits, and aging. These factors are reflected in shoeprints, which in turn can be used to predict age, a problem not systematically addressed using any computational approach. We collected 100,000 shoeprints of subjects ranging from 7 to 80 years old and used the data to develop a deep learning end-to-end model ShoeNet to analyze age-related patterns and predict age. The model integrates various convolutional neural network models together using a skip mechanism to extract age-related features, especially in pressure and abrasion regions from pair-wise shoeprints. The results show that 40.23% of the subjects had prediction errors within 5-years of age and the prediction accuracy for gender classification reached 86.07%. Interestingly, the age-related features mostly reside in the asymmetric differences between left and right shoeprints. The analysis also reveals interesting age-related and gender-related patterns in the pressure distributions on shoeprints; in particular, the pressure forces spread from the middle of the toe toward outside regions over age with gender-specific variations on heel regions. Such statistics provide insight into new methods for forensic investigations, medical studies of gait-pattern disorders, biometrics, and sport studies.
Compositional Learning of Relation Path Embedding for Knowledge Base Completion
Feb 24, 2017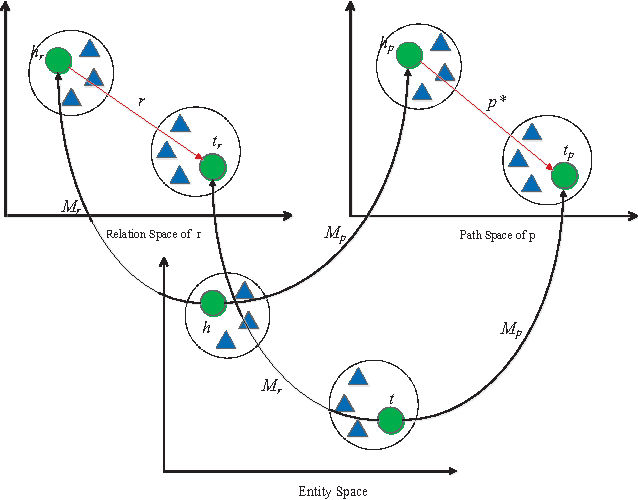
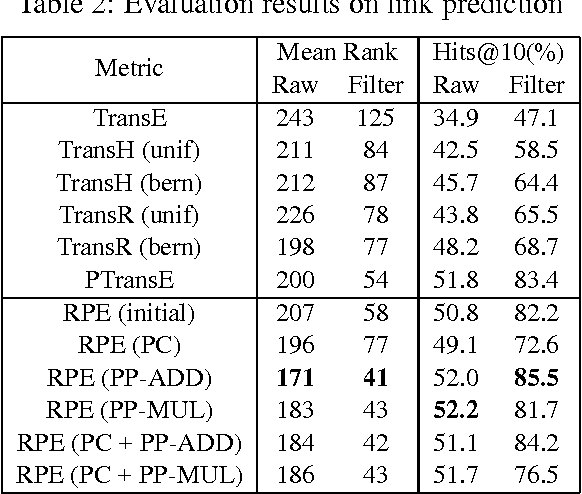
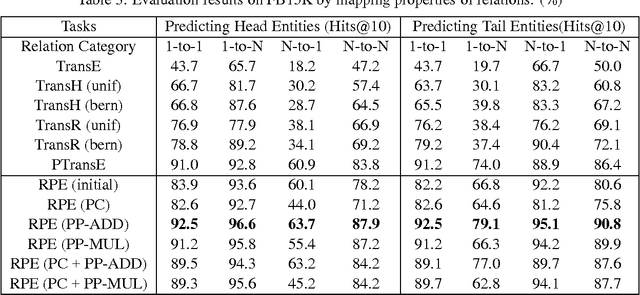
Large-scale knowledge bases have currently reached impressive sizes; however, these knowledge bases are still far from complete. In addition, most of the existing methods for knowledge base completion only consider the direct links between entities, ignoring the vital impact of the consistent semantics of relation paths. In this paper, we study the problem of how to better embed entities and relations of knowledge bases into different low-dimensional spaces by taking full advantage of the additional semantics of relation paths, and we propose a compositional learning model of relation path embedding (RPE). Specifically, with the corresponding relation and path projections, RPE can simultaneously embed each entity into two types of latent spaces. It is also proposed that type constraints could be extended from traditional relation-specific constraints to the new proposed path-specific constraints. The results of experiments show that the proposed model achieves significant and consistent improvements compared with the state-of-the-art algorithms.