 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHVI-FDD: A Hierarchical Decoupling Framework for Low-Light Image Enhancement
Apr 07, 2026Low-light images often suffer from severe noise, detail loss, and color distortion, which hinder downstream multimedia analysis and retrieval tasks. The degradation in low-light images is complex: luminance and chrominance are coupled, while within the chrominance, noise and details are deeply entangled, preventing existing methods from simultaneously correcting color distortion, suppressing noise, and preserving fine details. To tackle the above challenges, we propose a novel hierarchical decoupling framework (RHVI-FDD). At the macro level, we introduce the RHVI transform, which mitigates the estimation bias caused by input noise and enables robust luminance-chrominance decoupling. At the micro level, we design a Frequency-Domain Decoupling (FDD) module with three branches for further feature separation. Using the Discrete Cosine Transform, we decompose chrominance features into low, mid, and high-frequency bands that predominantly represent global tone, local details, and noise components, which are then processed by tailored expert networks in a divide-and-conquer manner and fused via an adaptive gating module for content-aware fusion. Extensive experiments on multiple low-light datasets demonstrate that our method consistently outperforms existing state-of-the-art approaches in both objective metrics and subjective visual quality.
Mamba Meets Scheduling: Learning to Solve Flexible Job Shop Scheduling with Efficient Sequence Modeling
Feb 25, 2026The Flexible Job Shop Problem (FJSP) is a well-studied combinatorial optimization problem with extensive applications for manufacturing and production scheduling. It involves assigning jobs to various machines to optimize criteria, such as minimizing total completion time. Current learning-based methods in this domain often rely on localized feature extraction models, limiting their capacity to capture overarching dependencies spanning operations and machines. This paper introduces an innovative architecture that harnesses Mamba, a state-space model with linear computational complexity, to facilitate comprehensive sequence modeling tailored for FJSP. In contrast to prevalent graph-attention-based frameworks that are computationally intensive for FJSP, we show our model is more efficient. Specifically, the proposed model possesses an encoder and a decoder. The encoder incorporates a dual Mamba block to extract operation and machine features separately. Additionally, we introduce an efficient cross-attention decoder to learn interactive embeddings of operations and machines. Our experimental results demonstrate that our method achieves faster solving speed and surpasses the performance of state-of-the-art learning-based methods for FJSP across various benchmarks.
Bridging the Gap Between Theory and Practice: Benchmarking Transfer Evolutionary Optimization
Apr 20, 2024



In recent years, the field of Transfer Evolutionary Optimization (TrEO) has witnessed substantial growth, fueled by the realization of its profound impact on solving complex problems. Numerous algorithms have emerged to address the challenges posed by transferring knowledge between tasks. However, the recently highlighted ``no free lunch theorem'' in transfer optimization clarifies that no single algorithm reigns supreme across diverse problem types. This paper addresses this conundrum by adopting a benchmarking approach to evaluate the performance of various TrEO algorithms in realistic scenarios. Despite the growing methodological focus on transfer optimization, existing benchmark problems often fall short due to inadequate design, predominantly featuring synthetic problems that lack real-world relevance. This paper pioneers a practical TrEO benchmark suite, integrating problems from the literature categorized based on the three essential aspects of Big Source Task-Instances: volume, variety, and velocity. Our primary objective is to provide a comprehensive analysis of existing TrEO algorithms and pave the way for the development of new approaches to tackle practical challenges. By introducing realistic benchmarks that embody the three dimensions of volume, variety, and velocity, we aim to foster a deeper understanding of algorithmic performance in the face of diverse and complex transfer scenarios. This benchmark suite is poised to serve as a valuable resource for researchers, facilitating the refinement and advancement of TrEO algorithms in the pursuit of solving real-world problems.
Troublemaker Learning for Low-Light Image Enhancement
Feb 07, 2024



Low-light image enhancement (LLIE) restores the color and brightness of underexposed images. Supervised methods suffer from high costs in collecting low/normal-light image pairs. Unsupervised methods invest substantial effort in crafting complex loss functions. We address these two challenges through the proposed TroubleMaker Learning (TML) strategy, which employs normal-light images as inputs for training. TML is simple: we first dim the input and then increase its brightness. TML is based on two core components. First, the troublemaker model (TM) constructs pseudo low-light images from normal images to relieve the cost of pairwise data. Second, the predicting model (PM) enhances the brightness of pseudo low-light images. Additionally, we incorporate an enhancing model (EM) to further improve the visual performance of PM outputs. Moreover, in LLIE tasks, characterizing global element correlations is important because more information on the same object can be captured. CNN cannot achieve this well, and self-attention has high time complexity. Accordingly, we propose Global Dynamic Convolution (GDC) with O(n) time complexity, which essentially imitates the partial calculation process of self-attention to formulate elementwise correlations. Based on the GDC module, we build the UGDC model. Extensive quantitative and qualitative experiments demonstrate that UGDC trained with TML can achieve competitive performance against state-of-the-art approaches on public datasets. The code is available at https://github.com/Rainbowman0/TML_LLIE.
Multiform Evolution for High-Dimensional Problems with Low Effective Dimensionality
Dec 30, 2023In this paper, we scale evolutionary algorithms to high-dimensional optimization problems that deceptively possess a low effective dimensionality (certain dimensions do not significantly affect the objective function). To this end, an instantiation of the multiform optimization paradigm is presented, where multiple low-dimensional counterparts of a target high-dimensional task are generated via random embeddings. Since the exact relationship between the auxiliary (low-dimensional) tasks and the target is a priori unknown, a multiform evolutionary algorithm is developed for unifying all formulations into a single multi-task setting. The resultant joint optimization enables the target task to efficiently reuse solutions evolved across various low-dimensional searches via cross-form genetic transfers, hence speeding up overall convergence characteristics. To validate the overall efficacy of our proposed algorithmic framework, comprehensive experimental studies are carried out on well-known continuous benchmark functions as well as a set of practical problems in the hyper-parameter tuning of machine learning models and deep learning models in classification tasks and Predator-Prey games, respectively.
Exploring Overall Contextual Information for Image Captioning in Human-Like Cognitive Style
Oct 15, 2019
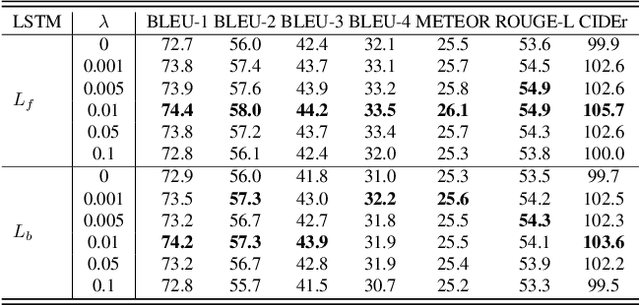
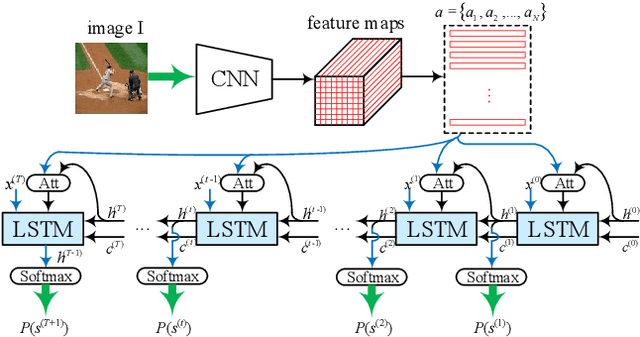
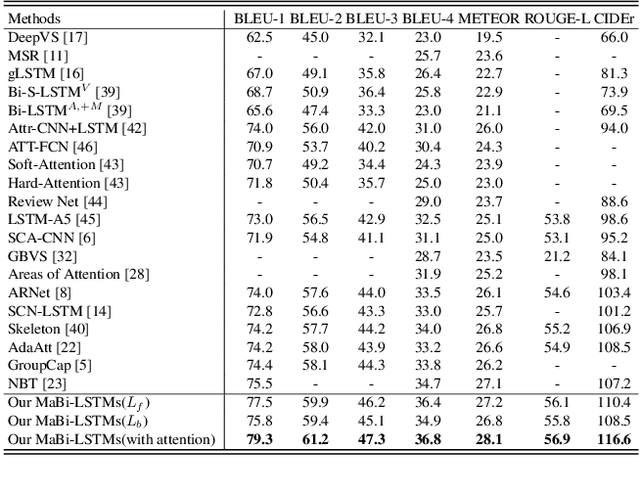
Image captioning is a research hotspot where encoder-decoder models combining convolutional neural network (CNN) and long short-term memory (LSTM) achieve promising results. Despite significant progress, these models generate sentences differently from human cognitive styles. Existing models often generate a complete sentence from the first word to the end, without considering the influence of the following words on the whole sentence generation. In this paper, we explore the utilization of a human-like cognitive style, i.e., building overall cognition for the image to be described and the sentence to be constructed, for enhancing computer image understanding. This paper first proposes a Mutual-aid network structure with Bidirectional LSTMs (MaBi-LSTMs) for acquiring overall contextual information. In the training process, the forward and backward LSTMs encode the succeeding and preceding words into their respective hidden states by simultaneously constructing the whole sentence in a complementary manner. In the captioning process, the LSTM implicitly utilizes the subsequent semantic information contained in its hidden states. In fact, MaBi-LSTMs can generate two sentences in forward and backward directions. To bridge the gap between cross-domain models and generate a sentence with higher quality, we further develop a cross-modal attention mechanism to retouch the two sentences by fusing their salient parts as well as the salient areas of the image. Experimental results on the Microsoft COCO dataset show that the proposed model improves the performance of encoder-decoder models and achieves state-of-the-art results.
A Reference Vector based Many-Objective Evolutionary Algorithm with Feasibility-aware Adaptation
Apr 12, 2019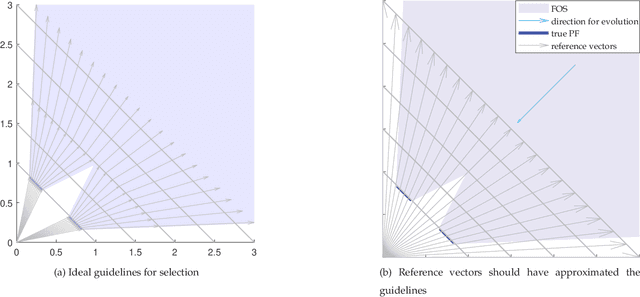


The infeasible parts of the objective space in difficult many-objective optimization problems cause trouble for evolutionary algorithms. This paper proposes a reference vector based algorithm which uses two interacting engines to adapt the reference vectors and to evolve the population towards the true Pareto Front (PF) s.t. the reference vectors are always evenly distributed within the current PF to provide appropriate guidance for selection. The current PF is tracked by maintaining an archive of undominated individuals, and adaptation of reference vectors is conducted with the help of another archive that contains layers of reference vectors corresponding to different density. Experimental results show the expected characteristics and competitive performance of the proposed algorithm TEEA.
Online Decisioning Meta-Heuristic Framework for Large Scale Black-Box Optimization
Dec 17, 2018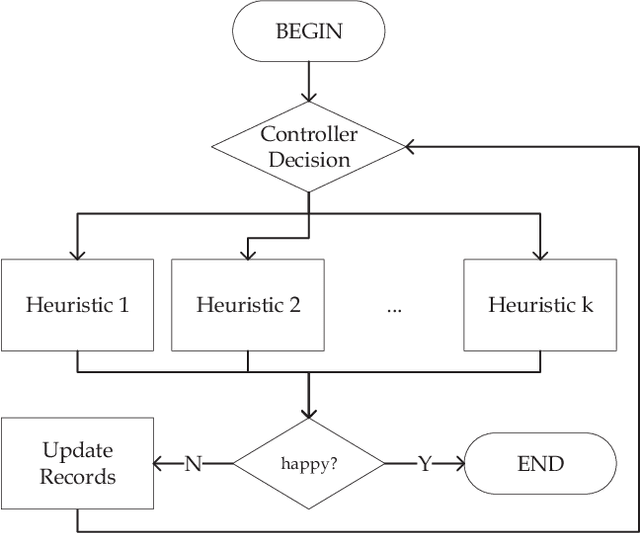
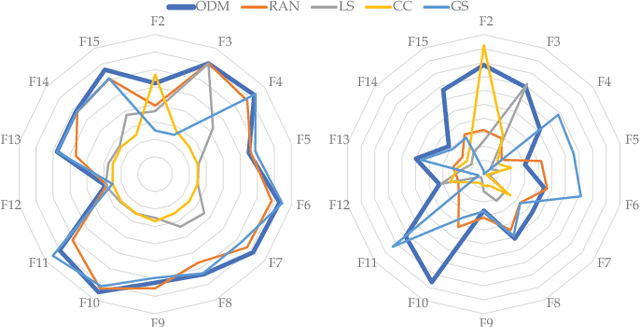
Out of practical concerns and with the expectation to achieve high overall efficiency of the resource utilization, this paper transforms the large scale black-box optimization problems with limited resources into online decision problems from the perspective of dynamic multi-armed bandits, a simplified view of Markov decision processes. The proposed Online Decisioning Meta-heuristic framework (ODM) is particularly well suited for real-world applications, with flexible compatibility for various kinds of costs, interfaces for easy heuristic articulation as well as fewer hyper-parameters for less variance in performance. Experimental results on benchmark functions suggest that ODM has demonstrated significant capabilities for online decisioning. Furthermore, when ODM is articulated with three heuristics, competitive performance can be achieved on benchmark problems with search dimensions up to 10000.
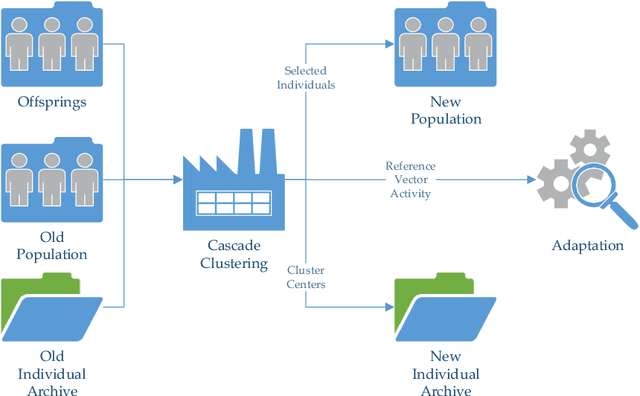
A Many-Objective Evolutionary Algorithm with Two Interacting Processes: Cascade Clustering and Reference Point Incremental Learning
Oct 04, 2018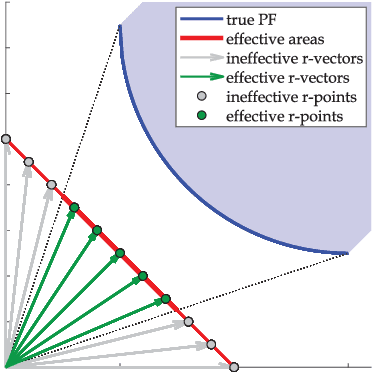
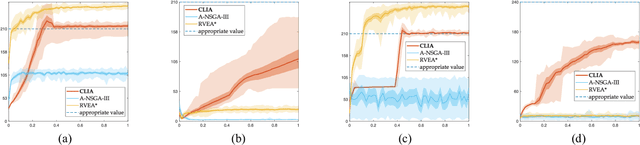
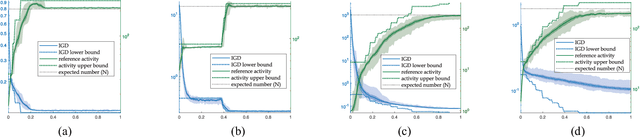
Researches have shown difficulties in obtaining proximity while maintaining diversity for solving many-objective optimization problems (MaOPs). The complexities of the true Pareto Front (PF) pose serious challenges for the reference vector based algorithms for their insufficient adaptability to the characteristics of the true PF with no priori. This paper proposes a many-objective optimization Algorithm with two Interacting processes: cascade Clustering and reference point incremental Learning (CLIA). In the population selection process based on cascade clustering, using the reference vectors provided by the incremental learning process, the non-dominated and the dominated individuals are clustered and sorted with different manners in a cascade style and are selected by round-robin for better proximity and diversity. In the reference vector adaptation process based on reference point incremental learning, using the feedbacks from the clustering process, the proper distribution of reference points is gradually obtained by incremental learning and the reference vectors are accordingly repositioned. The advantages of CLIA lie not only in its effective and efficient performance, but also in the versatility to deal with diverse characteristics of the true PF, only using the interactions between the two processes without incurring extra evaluations. The experimental studies on many benchmark problems show that CLIA is competitive, efficient and versatile compared with the state-of-the-art algorithms.
* 15 pages