 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGRouter-Bench: A Dataset and Benchmark for Adaptive RAG Routing
Jan 30, 2026Retrieval-Augmented Generation (RAG) has become a core paradigm for grounding large language models with external knowledge. Despite extensive efforts exploring diverse retrieval strategies, existing studies predominantly focus on query-side complexity or isolated method improvements, lacking a systematic understanding of how RAG paradigms behave across different query-corpus contexts and effectiveness-efficiency trade-offs. In this work, we introduce RAGRouter-Bench, the first dataset and benchmark designed for adaptive RAG routing. RAGRouter-Bench revisits retrieval from a query-corpus compatibility perspective and standardizes five representative RAG paradigms for systematic evaluation across 7,727 queries and 21,460 documents spanning diverse domains. The benchmark incorporates three canonical query types together with fine-grained semantic and structural corpus metrics, as well as a unified evaluation for both generation quality and resource consumption. Experiments with DeepSeek-V3 and LLaMA-3.1-8B demonstrate that no single RAG paradigm is universally optimal, that paradigm applicability is strongly shaped by query-corpus interactions, and that increased advanced mechanism does not necessarily yield better effectiveness-efficiency trade-offs. These findings underscore the necessity of routing-aware evaluation and establish a foundation for adaptive, interpretable, and generalizable next-generation RAG systems.
Token-level Collaborative Alignment for LLM-based Generative Recommendation
Jan 26, 2026Large Language Models (LLMs) have demonstrated strong potential for generative recommendation by leveraging rich semantic knowledge. However, existing LLM-based recommender systems struggle to effectively incorporate collaborative filtering (CF) signals, due to a fundamental mismatch between item-level preference modeling in CF and token-level next-token prediction (NTP) optimization in LLMs. Prior approaches typically treat CF as contextual hints or representation bias, and resort to multi-stage training to reduce behavioral semantic space discrepancies, leaving CF unable to explicitly regulate LLM generation. In this work, we propose Token-level Collaborative Alignment for Recommendation (TCA4Rec), a model-agnostic and plug-and-play framework that establishes an explicit optimization-level interface between CF supervision and LLM generation. TCA4Rec consists of (i) Collaborative Tokenizer, which projects raw item-level CF logits into token-level distributions aligned with the LLM token space, and (ii) Soft Label Alignment, which integrates these CF-informed distributions with one-hot supervision to optimize a soft NTP objective. This design preserves the generative nature of LLM training while enabling collaborative alignment with essential user preference of CF models. We highlight TCA4Rec is compatible with arbitrary traditional CF models and generalizes across a wide range of decoder-based LLM recommender architectures. Moreover, it provides an explicit mechanism to balance behavioral alignment and semantic fluency, yielding generative recommendations that are both accurate and controllable. Extensive experiments demonstrate that TCA4Rec consistently improves recommendation performance across a broad spectrum of CF models and LLM-based recommender systems.
BrainSegNet: A Novel Framework for Whole-Brain MRI Parcellation Enhanced by Large Models
Jan 14, 2026Whole-brain parcellation from MRI is a critical yet challenging task due to the complexity of subdividing the brain into numerous small, irregular shaped regions. Traditionally, template-registration methods were used, but recent advances have shifted to deep learning for faster workflows. While large models like the Segment Anything Model (SAM) offer transferable feature representations, they are not tailored for the high precision required in brain parcellation. To address this, we propose BrainSegNet, a novel framework that adapts SAM for accurate whole-brain parcellation into 95 regions. We enhance SAM by integrating U-Net skip connections and specialized modules into its encoder and decoder, enabling fine-grained anatomical precision. Key components include a hybrid encoder combining U-Net skip connections with SAM's transformer blocks, a multi-scale attention decoder with pyramid pooling for varying-sized structures, and a boundary refinement module to sharpen edges. Experimental results on the Human Connectome Project (HCP) dataset demonstrate that BrainSegNet outperforms several state-of-the-art methods, achieving higher accuracy and robustness in complex, multi-label parcellation.
Coarse-to-Fine Joint Registration of MR and Ultrasound Images via Imaging Style Transfer
Aug 07, 2025We developed a pipeline for registering pre-surgery Magnetic Resonance (MR) images and post-resection Ultrasound (US) images. Our approach leverages unpaired style transfer using 3D CycleGAN to generate synthetic T1 images, thereby enhancing registration performance. Additionally, our registration process employs both affine and local deformable transformations for a coarse-to-fine registration. The results demonstrate that our approach improves the consistency between MR and US image pairs in most cases.
DDTracking: A Deep Generative Framework for Diffusion MRI Tractography with Streamline Local-Global Spatiotemporal Modeling
Aug 06, 2025This paper presents DDTracking, a novel deep generative framework for diffusion MRI tractography that formulates streamline propagation as a conditional denoising diffusion process. In DDTracking, we introduce a dual-pathway encoding network that jointly models local spatial encoding (capturing fine-scale structural details at each streamline point) and global temporal dependencies (ensuring long-range consistency across the entire streamline). Furthermore, we design a conditional diffusion model module, which leverages the learned local and global embeddings to predict streamline propagation orientations for tractography in an end-to-end trainable manner. We conduct a comprehensive evaluation across diverse, independently acquired dMRI datasets, including both synthetic and clinical data. Experiments on two well-established benchmarks with ground truth (ISMRM Challenge and TractoInferno) demonstrate that DDTracking largely outperforms current state-of-the-art tractography methods. Furthermore, our results highlight DDTracking's strong generalizability across heterogeneous datasets, spanning varying health conditions, age groups, imaging protocols, and scanner types. Collectively, DDTracking offers anatomically plausible and robust tractography, presenting a scalable, adaptable, and end-to-end learnable solution for broad dMRI applications. Code is available at: https://github.com/yishengpoxiao/DDtracking.git
DeSocial: Blockchain-based Decentralized Social Networks
May 28, 2025Web 2.0 social platforms are inherently centralized, with user data and algorithmic decisions controlled by the platform. However, users can only passively receive social predictions without being able to choose the underlying algorithm, which limits personalization. Fortunately, with the emergence of blockchain, users are allowed to choose algorithms that are tailored to their local situation, improving prediction results in a personalized way. In a blockchain environment, each user possesses its own model to perform the social prediction, capturing different perspectives on social interactions. In our work, we propose DeSocial, a decentralized social network learning framework deployed on an Ethereum (ETH) local development chain that integrates distributed data storage, node-level consensus, and user-driven model selection through Ganache. In the first stage, each user leverages DeSocial to evaluate multiple backbone models on their local subgraph. DeSocial coordinates the execution and returns model-wise prediction results, enabling the user to select the most suitable backbone for personalized social prediction. Then, DeSocial uniformly selects several validation nodes that possess the algorithm specified by each user, and aggregates the prediction results by majority voting, to prevent errors caused by any single model's misjudgment. Extensive experiments show that DeSocial has an evident improvement compared to the five classical centralized social network learning models, promoting user empowerment in blockchain-based decentralized social networks, showing the importance of multi-node validation and personalized algorithm selection based on blockchain. Our implementation is available at: https://github.com/agiresearch/DeSocial.
LiteCUA: Computer as MCP Server for Computer-Use Agent on AIOS
May 24, 2025We present AIOS 1.0, a novel platform designed to advance computer-use agent (CUA) capabilities through environmental contextualization. While existing approaches primarily focus on building more powerful agent frameworks or enhancing agent models, we identify a fundamental limitation: the semantic disconnect between how language models understand the world and how computer interfaces are structured. AIOS 1.0 addresses this challenge by transforming computers into contextual environments that language models can natively comprehend, implementing a Model Context Protocol (MCP) server architecture to abstract computer states and actions. This approach effectively decouples interface complexity from decision complexity, enabling agents to reason more effectively about computing environments. To demonstrate our platform's effectiveness, we introduce LiteCUA, a lightweight computer-use agent built on AIOS 1.0 that achieves a 14.66% success rate on the OSWorld benchmark, outperforming several specialized agent frameworks despite its simple architecture. Our results suggest that contextualizing computer environments for language models represents a promising direction for developing more capable computer-use agents and advancing toward AI that can interact with digital systems. The source code of LiteCUA is available at https://github.com/agiresearch/LiteCUA, and it is also integrated into the AIOS main branch as part of AIOS at https://github.com/agiresearch/AIOS.
ANNs-SaDE: A Machine-Learning-Based Design Automation Framework for Microwave Branch-Line Couplers
Mar 31, 2025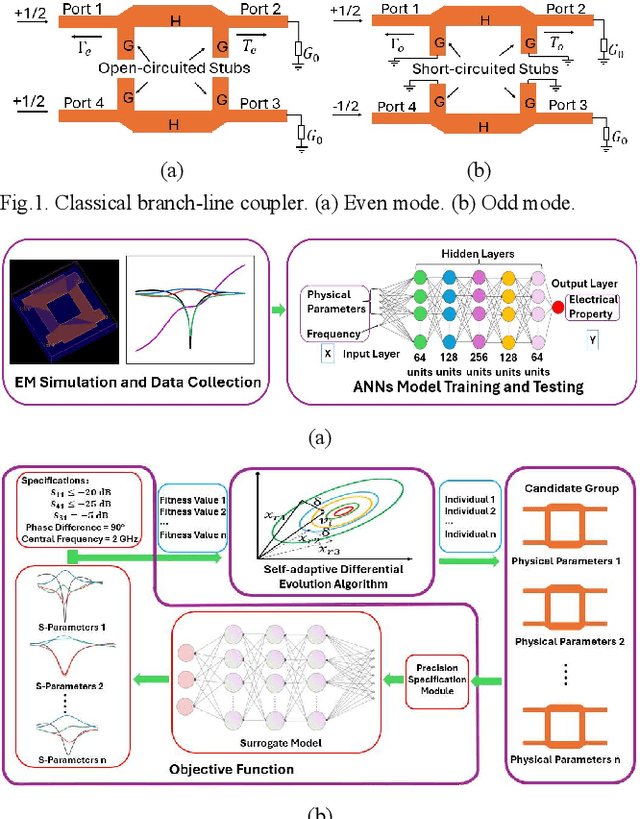
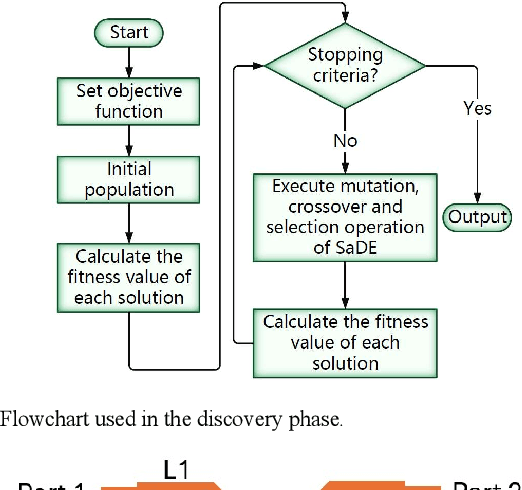
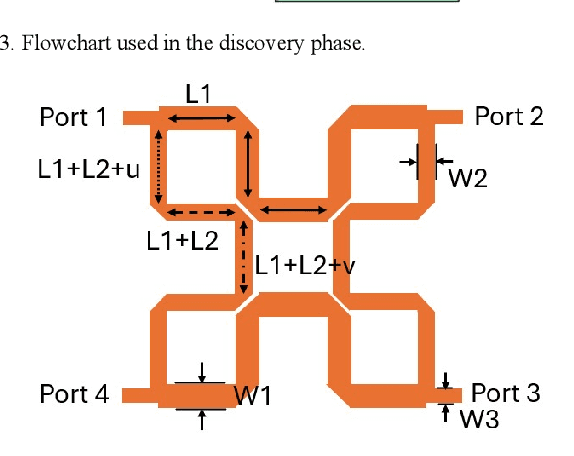
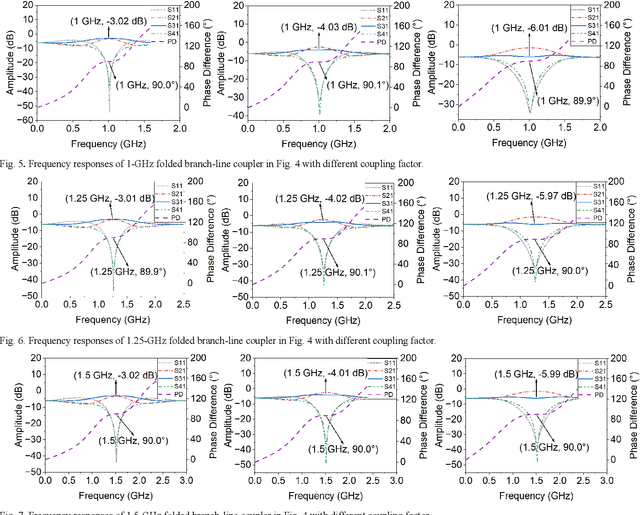
The traditional method for designing branch-line couplers involves a trial-and-error optimization process that requires multiple design iterations through electromagnetic (EM) simulations. Thus, it is extremely time consuming and labor intensive. In this paper, a novel machine-learning-based framework is proposed to tackle this issue. It integrates artificial neural networks with a self-adaptive differential evolution algorithm (ANNs-SaDE). This framework enables the self-adaptive design of various types of microwave branch-line couplers by precisely optimizing essential electrical properties, such as coupling factor, isolation, and phase difference between output ports. The effectiveness of the ANNs-SaDE framework is demonstrated by the designs of folded single-stage branch-line couplers and multi-stage wideband branch-line couplers.
LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
Mar 05, 2025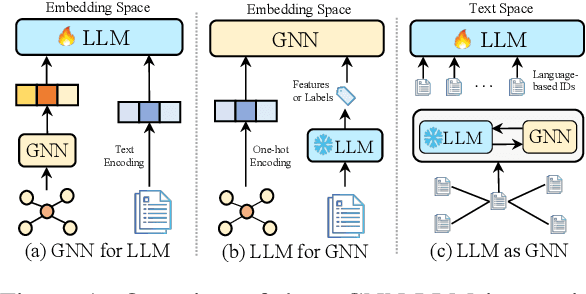
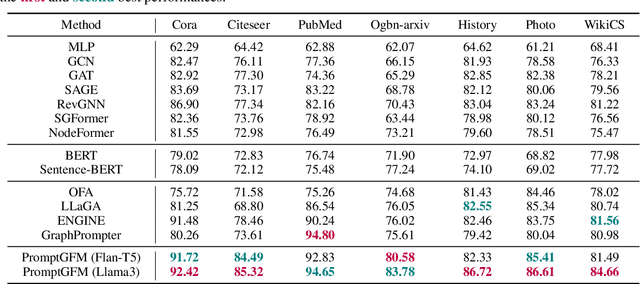
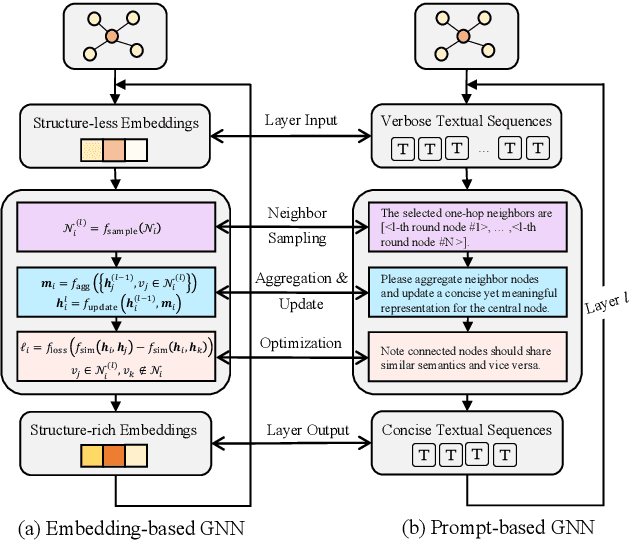
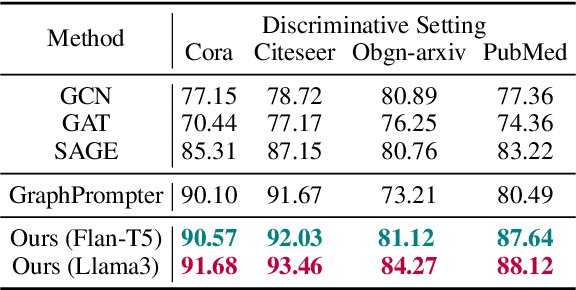
Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: https://github.com/agiresearch/PromptGFM.
InstructAgent: Building User Controllable Recommender via LLM Agent
Feb 20, 2025Traditional recommender systems usually take the user-platform paradigm, where users are directly exposed under the control of the platform's recommendation algorithms. However, the defect of recommendation algorithms may put users in very vulnerable positions under this paradigm. First, many sophisticated models are often designed with commercial objectives in mind, focusing on the platform's benefits, which may hinder their ability to protect and capture users' true interests. Second, these models are typically optimized using data from all users, which may overlook individual user's preferences. Due to these shortcomings, users may experience several disadvantages under the traditional user-platform direct exposure paradigm, such as lack of control over the recommender system, potential manipulation by the platform, echo chamber effects, or lack of personalization for less active users due to the dominance of active users during collaborative learning. Therefore, there is an urgent need to develop a new paradigm to protect user interests and alleviate these issues. Recently, some researchers have introduced LLM agents to simulate user behaviors, these approaches primarily aim to optimize platform-side performance, leaving core issues in recommender systems unresolved. To address these limitations, we propose a new user-agent-platform paradigm, where agent serves as the protective shield between user and recommender system that enables indirect exposure. To this end, we first construct four recommendation datasets, denoted as $\dataset$, along with user instructions for each record.