 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMERGE: Integrating RAG for Improved Multimodal EHR Predictive Modeling
May 27, 2024



The integration of multimodal Electronic Health Records (EHR) data has notably advanced clinical predictive capabilities. However, current models that utilize clinical notes and multivariate time-series EHR data often lack the necessary medical context for precise clinical tasks. Previous methods using knowledge graphs (KGs) primarily focus on structured knowledge extraction. To address this, we propose EMERGE, a Retrieval-Augmented Generation (RAG) driven framework aimed at enhancing multimodal EHR predictive modeling. Our approach extracts entities from both time-series data and clinical notes by prompting Large Language Models (LLMs) and aligns them with professional PrimeKG to ensure consistency. Beyond triplet relationships, we include entities' definitions and descriptions to provide richer semantics. The extracted knowledge is then used to generate task-relevant summaries of patients' health statuses. These summaries are fused with other modalities utilizing an adaptive multimodal fusion network with cross-attention. Extensive experiments on the MIMIC-III and MIMIC-IV datasets for in-hospital mortality and 30-day readmission tasks demonstrate the superior performance of the EMERGE framework compared to baseline models. Comprehensive ablation studies and analyses underscore the efficacy of each designed module and the framework's robustness to data sparsity. EMERGE significantly enhances the use of multimodal EHR data in healthcare, bridging the gap with nuanced medical contexts crucial for informed clinical predictions.
RoNID: New Intent Discovery with Generated-Reliable Labels and Cluster-friendly Representations
Apr 13, 2024New Intent Discovery (NID) strives to identify known and reasonably deduce novel intent groups in the open-world scenario. But current methods face issues with inaccurate pseudo-labels and poor representation learning, creating a negative feedback loop that degrades overall model performance, including accuracy and the adjusted rand index. To address the aforementioned challenges, we propose a Robust New Intent Discovery (RoNID) framework optimized by an EM-style method, which focuses on constructing reliable pseudo-labels and obtaining cluster-friendly discriminative representations. RoNID comprises two main modules: reliable pseudo-label generation module and cluster-friendly representation learning module. Specifically, the pseudo-label generation module assigns reliable synthetic labels by solving an optimal transport problem in the E-step, which effectively provides high-quality supervised signals for the input of the cluster-friendly representation learning module. To learn cluster-friendly representation with strong intra-cluster compactness and large inter-cluster separation, the representation learning module combines intra-cluster and inter-cluster contrastive learning in the M-step to feed more discriminative features into the generation module. RoNID can be performed iteratively to ultimately yield a robust model with reliable pseudo-labels and cluster-friendly representations. Experimental results on multiple benchmarks demonstrate our method brings substantial improvements over previous state-of-the-art methods by a large margin of +1~+4 points.
REALM: RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Language Models
Feb 10, 2024The integration of multimodal Electronic Health Records (EHR) data has significantly improved clinical predictive capabilities. Leveraging clinical notes and multivariate time-series EHR, existing models often lack the medical context relevent to clinical tasks, prompting the incorporation of external knowledge, particularly from the knowledge graph (KG). Previous approaches with KG knowledge have primarily focused on structured knowledge extraction, neglecting unstructured data modalities and semantic high dimensional medical knowledge. In response, we propose REALM, a Retrieval-Augmented Generation (RAG) driven framework to enhance multimodal EHR representations that address these limitations. Firstly, we apply Large Language Model (LLM) to encode long context clinical notes and GRU model to encode time-series EHR data. Secondly, we prompt LLM to extract task-relevant medical entities and match entities in professionally labeled external knowledge graph (PrimeKG) with corresponding medical knowledge. By matching and aligning with clinical standards, our framework eliminates hallucinations and ensures consistency. Lastly, we propose an adaptive multimodal fusion network to integrate extracted knowledge with multimodal EHR data. Our extensive experiments on MIMIC-III mortality and readmission tasks showcase the superior performance of our REALM framework over baselines, emphasizing the effectiveness of each module. REALM framework contributes to refining the use of multimodal EHR data in healthcare and bridging the gap with nuanced medical context essential for informed clinical predictions.
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Dec 26, 2023
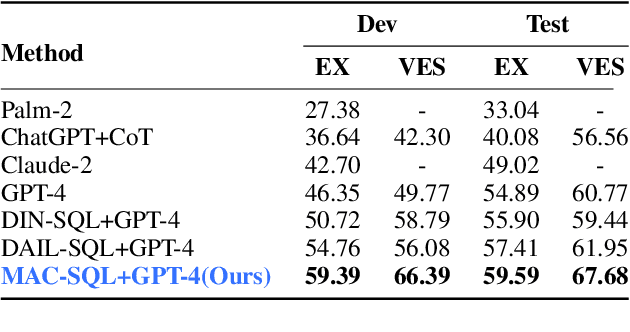
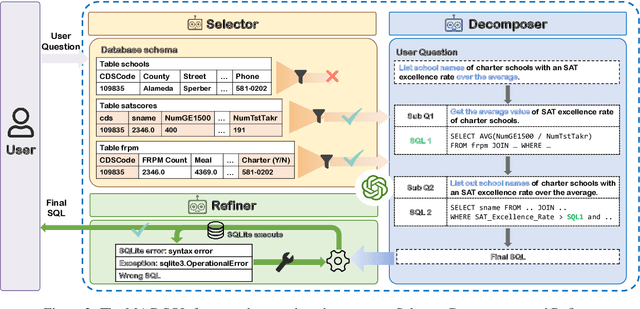

Recent advancements in Text-to-SQL methods employing Large Language Models (LLMs) have demonstrated remarkable performance. Nonetheless, these approaches continue to encounter difficulties when handling extensive databases, intricate user queries, and erroneous SQL results. To tackle these challenges, we present \textsc{MAC-SQL}, a novel LLM-based multi-agent collaborative framework designed for the Text-to-SQL task. Our framework comprises three agents: the \textit{Selector}, accountable for condensing voluminous databases and preserving relevant table schemas for user questions; the \textit{Decomposer}, which disassembles complex user questions into more straightforward sub-problems and resolves them progressively; and the \textit{Refiner}, tasked with validating and refining defective SQL queries. We perform comprehensive experiments on two Text-to-SQL datasets, BIRD and Spider, achieving a state-of-the-art execution accuracy of 59.59\% on the BIRD test set. Moreover, we have open-sourced an instruction fine-tuning model, SQL-Llama, based on Code Llama 7B, in addition to an agent instruction dataset derived from training data based on BIRD and Spider. The SQL-Llama model has demonstrated encouraging results on the development sets of both BIRD and Spider. However, when compared to GPT-4, there remains a notable potential for enhancement. Our code and data are publicly available at https://github.com/wbbeyourself/MAC-SQL.