 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2P: Automated Paper-to-Poster Generation and Fine-Grained Benchmark
May 21, 2025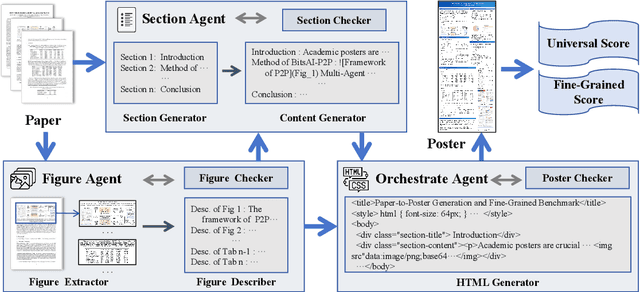
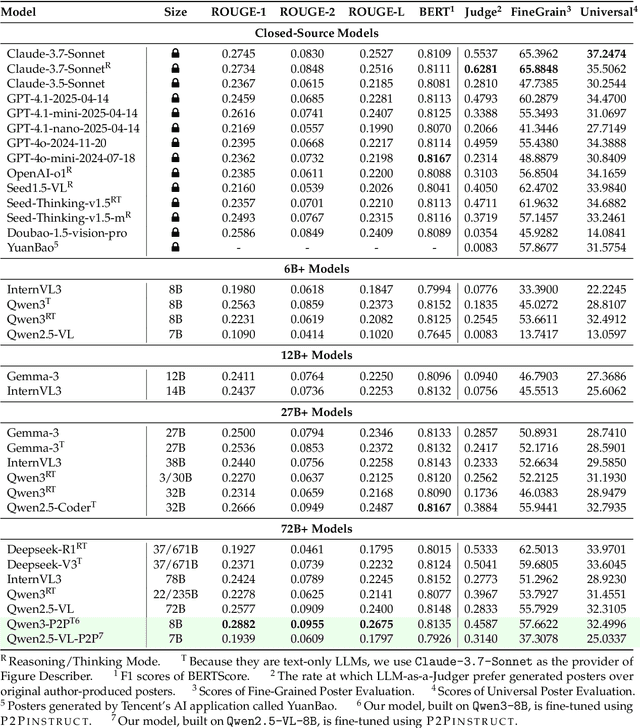


Academic posters are vital for scholarly communication, yet their manual creation is time-consuming. However, automated academic poster generation faces significant challenges in preserving intricate scientific details and achieving effective visual-textual integration. Existing approaches often struggle with semantic richness and structural nuances, and lack standardized benchmarks for evaluating generated academic posters comprehensively. To address these limitations, we introduce P2P, the first flexible, LLM-based multi-agent framework that generates high-quality, HTML-rendered academic posters directly from research papers, demonstrating strong potential for practical applications. P2P employs three specialized agents-for visual element processing, content generation, and final poster assembly-each integrated with dedicated checker modules to enable iterative refinement and ensure output quality. To foster advancements and rigorous evaluation in this domain, we construct and release P2PInstruct, the first large-scale instruction dataset comprising over 30,000 high-quality examples tailored for the academic paper-to-poster generation task. Furthermore, we establish P2PEval, a comprehensive benchmark featuring 121 paper-poster pairs and a dual evaluation methodology (Universal and Fine-Grained) that leverages LLM-as-a-Judge and detailed, human-annotated checklists. Our contributions aim to streamline research dissemination and provide the community with robust tools for developing and evaluating next-generation poster generation systems.
SimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models
Feb 18, 2025



The increasing application of multi-modal large language models (MLLMs) across various sectors have spotlighted the essence of their output reliability and accuracy, particularly their ability to produce content grounded in factual information (e.g. common and domain-specific knowledge). In this work, we introduce SimpleVQA, the first comprehensive multi-modal benchmark to evaluate the factuality ability of MLLMs to answer natural language short questions. SimpleVQA is characterized by six key features: it covers multiple tasks and multiple scenarios, ensures high quality and challenging queries, maintains static and timeless reference answers, and is straightforward to evaluate. Our approach involves categorizing visual question-answering items into 9 different tasks around objective events or common knowledge and situating these within 9 topics. Rigorous quality control processes are implemented to guarantee high-quality, concise, and clear answers, facilitating evaluation with minimal variance via an LLM-as-a-judge scoring system. Using SimpleVQA, we perform a comprehensive assessment of leading 18 MLLMs and 8 text-only LLMs, delving into their image comprehension and text generation abilities by identifying and analyzing error cases.
An Unsupervised Dialogue Topic Segmentation Model Based on Utterance Rewriting
Sep 12, 2024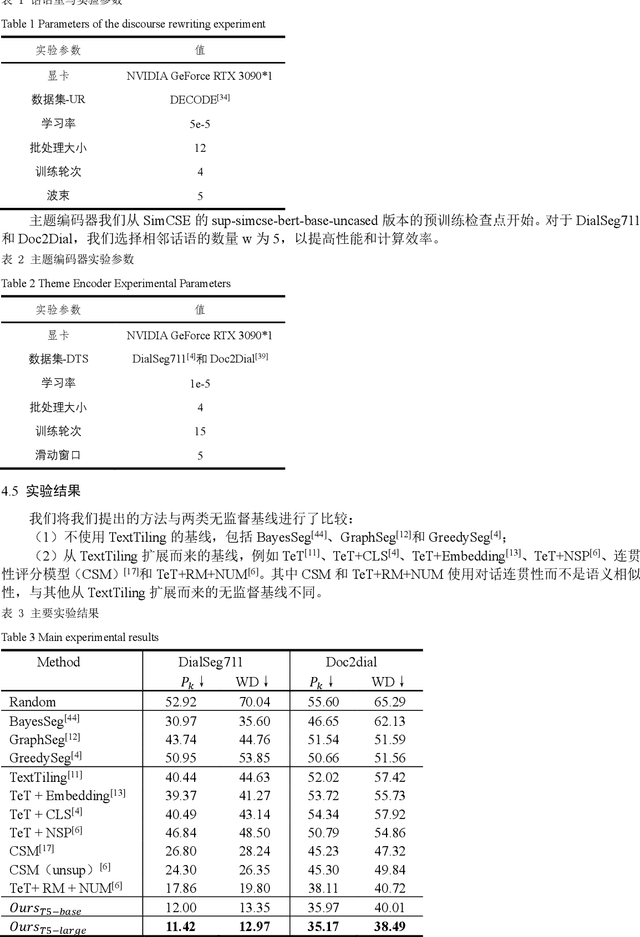
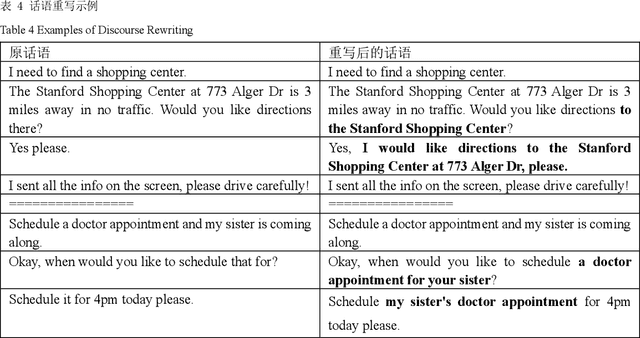
Dialogue topic segmentation plays a crucial role in various types of dialogue modeling tasks. The state-of-the-art unsupervised DTS methods learn topic-aware discourse representations from conversation data through adjacent discourse matching and pseudo segmentation to further mine useful clues in unlabeled conversational relations. However, in multi-round dialogs, discourses often have co-references or omissions, leading to the fact that direct use of these discourses for representation learning may negatively affect the semantic similarity computation in the neighboring discourse matching task. In order to fully utilize the useful cues in conversational relations, this study proposes a novel unsupervised dialog topic segmentation method that combines the Utterance Rewriting (UR) technique with an unsupervised learning algorithm to efficiently utilize the useful cues in unlabeled dialogs by rewriting the dialogs in order to recover the co-referents and omitted words. Compared with existing unsupervised models, the proposed Discourse Rewriting Topic Segmentation Model (UR-DTS) significantly improves the accuracy of topic segmentation. The main finding is that the performance on DialSeg711 improves by about 6% in terms of absolute error score and WD, achieving 11.42% in terms of absolute error score and 12.97% in terms of WD. on Doc2Dial the absolute error score and WD improves by about 3% and 2%, respectively, resulting in SOTA reaching 35.17% in terms of absolute error score and 38.49% in terms of WD. This shows that the model is very effective in capturing the nuances of conversational topics, as well as the usefulness and challenges of utilizing unlabeled conversations.
TableBench: A Comprehensive and Complex Benchmark for Table Question Answering
Aug 17, 2024
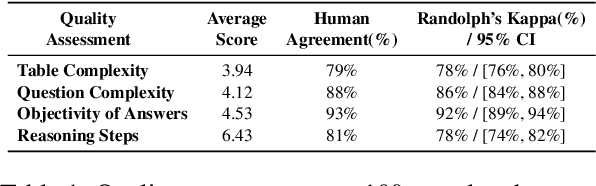
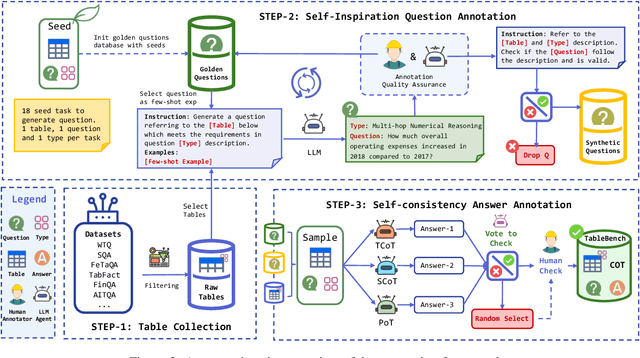
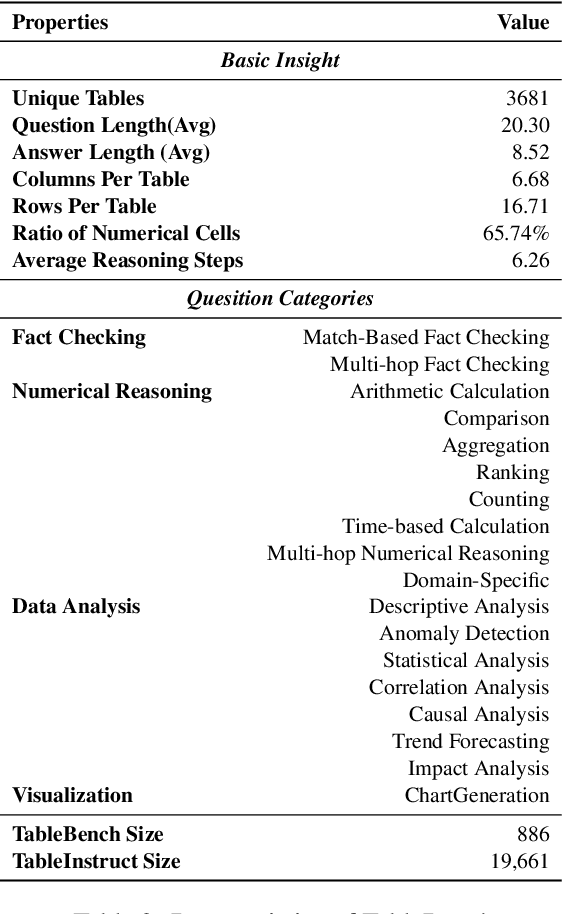
Recent advancements in Large Language Models (LLMs) have markedly enhanced the interpretation and processing of tabular data, introducing previously unimaginable capabilities. Despite these achievements, LLMs still encounter significant challenges when applied in industrial scenarios, particularly due to the increased complexity of reasoning required with real-world tabular data, underscoring a notable disparity between academic benchmarks and practical applications. To address this discrepancy, we conduct a detailed investigation into the application of tabular data in industrial scenarios and propose a comprehensive and complex benchmark TableBench, including 18 fields within four major categories of table question answering (TableQA) capabilities. Furthermore, we introduce TableLLM, trained on our meticulously constructed training set TableInstruct, achieving comparable performance with GPT-3.5. Massive experiments conducted on TableBench indicate that both open-source and proprietary LLMs still have significant room for improvement to meet real-world demands, where the most advanced model, GPT-4, achieves only a modest score compared to humans.
Raw Text is All you Need: Knowledge-intensive Multi-turn Instruction Tuning for Large Language Model
Jul 03, 2024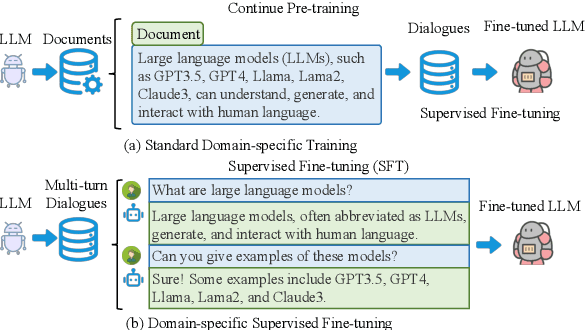



Instruction tuning as an effective technique aligns the outputs of large language models (LLMs) with human preference. But how to generate the seasonal multi-turn dialogues from raw documents for instruction tuning still requires further exploration. In this paper, we present a novel framework named R2S that leverages the CoD-Chain of Dialogue logic to guide large language models (LLMs) in generating knowledge-intensive multi-turn dialogues for instruction tuning. By integrating raw documents from both open-source datasets and domain-specific web-crawled documents into a benchmark K-BENCH, we cover diverse areas such as Wikipedia (English), Science (Chinese), and Artifacts (Chinese). Our approach first decides the logic flow of the current dialogue and then prompts LLMs to produce key phrases for sourcing relevant response content. This methodology enables the creation of the G I NSTRUCT instruction dataset, retaining raw document knowledge within dialoguestyle interactions. Utilizing this dataset, we fine-tune GLLM, a model designed to transform raw documents into structured multi-turn dialogues, thereby injecting comprehensive domain knowledge into the SFT model for enhanced instruction tuning. This work signifies a stride towards refining the adaptability and effectiveness of LLMs in processing and generating more accurate, contextually nuanced responses across various fields.
Towards Real-world Scenario: Imbalanced New Intent Discovery
Jun 05, 2024



New Intent Discovery (NID) aims at detecting known and previously undefined categories of user intent by utilizing limited labeled and massive unlabeled data. Most prior works often operate under the unrealistic assumption that the distribution of both familiar and new intent classes is uniform, overlooking the skewed and long-tailed distributions frequently encountered in real-world scenarios. To bridge the gap, our work introduces the imbalanced new intent discovery (i-NID) task, which seeks to identify familiar and novel intent categories within long-tailed distributions. A new benchmark (ImbaNID-Bench) comprised of three datasets is created to simulate the real-world long-tail distributions. ImbaNID-Bench ranges from broad cross-domain to specific single-domain intent categories, providing a thorough representation of practical use cases. Besides, a robust baseline model ImbaNID is proposed to achieve cluster-friendly intent representations. It includes three stages: model pre-training, generation of reliable pseudo-labels, and robust representation learning that strengthens the model performance to handle the intricacies of real-world data distributions. Our extensive experiments on previous benchmarks and the newly established benchmark demonstrate the superior performance of ImbaNID in addressing the i-NID task, highlighting its potential as a powerful baseline for uncovering and categorizing user intents in imbalanced and long-tailed distributions\footnote{\url{https://github.com/Zkdc/i-NID}}.
XFormParser: A Simple and Effective Multimodal Multilingual Semi-structured Form Parser
May 27, 2024



In the domain of document AI, semi-structured form parsing plays a crucial role. This task leverages techniques from key information extraction (KIE), dealing with inputs that range from plain text to intricate modal data comprising images and structural layouts. The advent of pre-trained multimodal models has driven the extraction of key information from form documents in different formats such as PDFs and images. Nonetheless, the endeavor of form parsing is still encumbered by notable challenges like subpar capabilities in multi-lingual parsing and diminished recall in contexts rich in text and visuals. In this work, we introduce a simple but effective \textbf{M}ultimodal and \textbf{M}ultilingual semi-structured \textbf{FORM} \textbf{PARSER} (\textbf{XFormParser}), which is anchored on a comprehensive pre-trained language model and innovatively amalgamates semantic entity recognition (SER) and relation extraction (RE) into a unified framework, enhanced by a novel staged warm-up training approach that employs soft labels to significantly refine form parsing accuracy without amplifying inference overhead. Furthermore, we have developed a groundbreaking benchmark dataset, named InDFormBench, catering specifically to the parsing requirements of multilingual forms in various industrial contexts. Through rigorous testing on established multilingual benchmarks and InDFormBench, XFormParser has demonstrated its unparalleled efficacy, notably surpassing the state-of-the-art (SOTA) models in RE tasks within language-specific setups by achieving an F1 score improvement of up to 1.79\%. Our framework exhibits exceptionally improved performance across tasks in both multi-language and zero-shot contexts when compared to existing SOTA benchmarks. The code is publicly available at https://github.com/zhbuaa0/layoutlmft.
RoNID: New Intent Discovery with Generated-Reliable Labels and Cluster-friendly Representations
Apr 13, 2024



New Intent Discovery (NID) strives to identify known and reasonably deduce novel intent groups in the open-world scenario. But current methods face issues with inaccurate pseudo-labels and poor representation learning, creating a negative feedback loop that degrades overall model performance, including accuracy and the adjusted rand index. To address the aforementioned challenges, we propose a Robust New Intent Discovery (RoNID) framework optimized by an EM-style method, which focuses on constructing reliable pseudo-labels and obtaining cluster-friendly discriminative representations. RoNID comprises two main modules: reliable pseudo-label generation module and cluster-friendly representation learning module. Specifically, the pseudo-label generation module assigns reliable synthetic labels by solving an optimal transport problem in the E-step, which effectively provides high-quality supervised signals for the input of the cluster-friendly representation learning module. To learn cluster-friendly representation with strong intra-cluster compactness and large inter-cluster separation, the representation learning module combines intra-cluster and inter-cluster contrastive learning in the M-step to feed more discriminative features into the generation module. RoNID can be performed iteratively to ultimately yield a robust model with reliable pseudo-labels and cluster-friendly representations. Experimental results on multiple benchmarks demonstrate our method brings substantial improvements over previous state-of-the-art methods by a large margin of +1~+4 points.
New Intent Discovery with Attracting and Dispersing Prototype
Mar 25, 2024
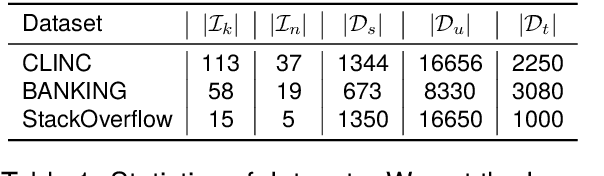

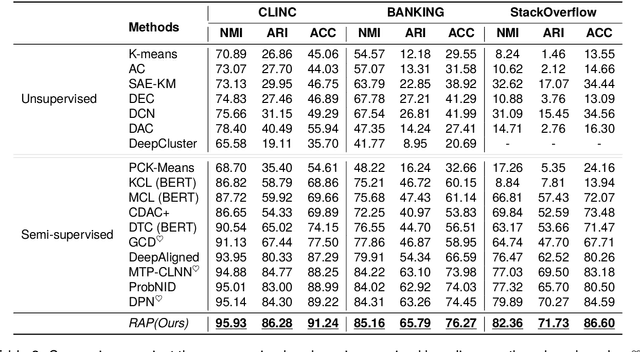
New Intent Discovery (NID) aims to recognize known and infer new intent categories with the help of limited labeled and large-scale unlabeled data. The task is addressed as a feature-clustering problem and recent studies augment instance representation. However, existing methods fail to capture cluster-friendly representations, since they show less capability to effectively control and coordinate within-cluster and between-cluster distances. Tailored to the NID problem, we propose a Robust and Adaptive Prototypical learning (RAP) framework for globally distinct decision boundaries for both known and new intent categories. Specifically, a robust prototypical attracting learning (RPAL) method is designed to compel instances to gravitate toward their corresponding prototype, achieving greater within-cluster compactness. To attain larger between-cluster separation, another adaptive prototypical dispersing learning (APDL) method is devised to maximize the between-cluster distance from the prototype-to-prototype perspective. Experimental results evaluated on three challenging benchmarks (CLINC, BANKING, and StackOverflow) of our method with better cluster-friendly representation demonstrate that RAP brings in substantial improvements over the current state-of-the-art methods (even large language model) by a large margin (average +5.5% improvement).
VIPTR: A Vision Permutable Extractor for Fast and Efficient Scene Text Recognition
Jan 24, 2024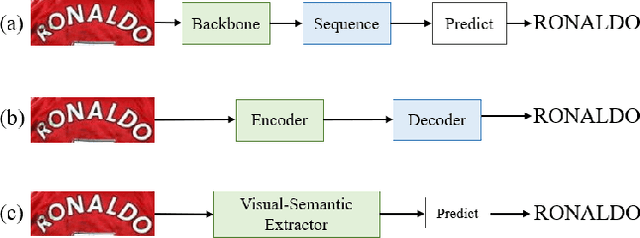
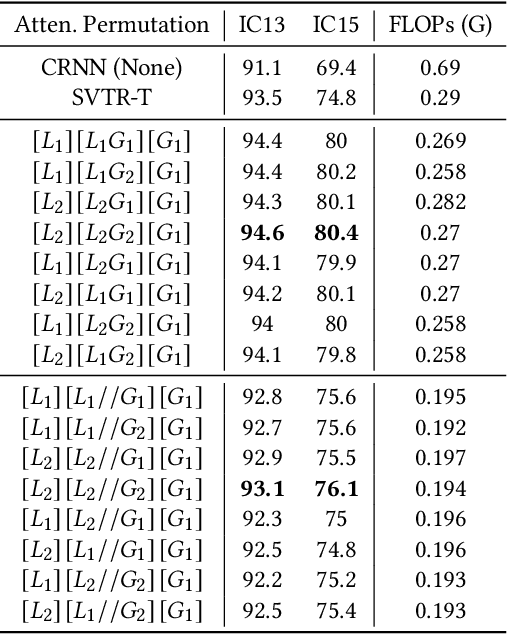
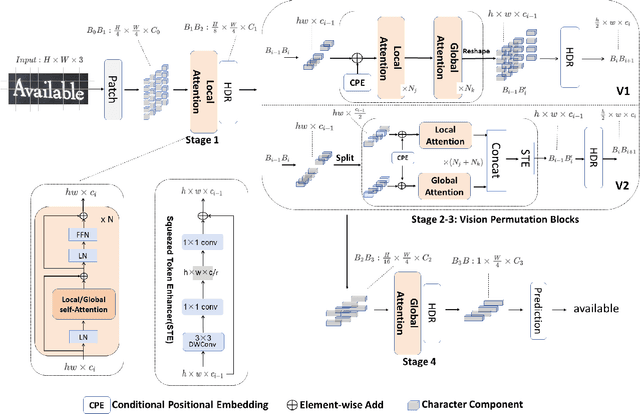
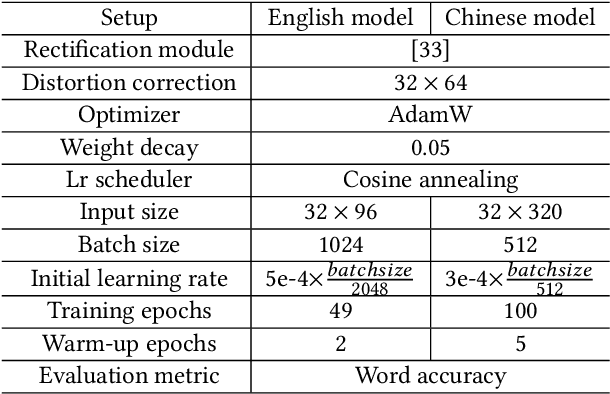
Scene Text Recognition (STR) is a challenging task that involves recognizing text within images of natural scenes. Although current state-of-the-art models for STR exhibit high performance, they typically suffer from low inference efficiency due to their reliance on hybrid architectures comprised of visual encoders and sequence decoders. In this work, we propose the VIsion Permutable extractor for fast and efficient scene Text Recognition (VIPTR), which achieves an impressive balance between high performance and rapid inference speeds in the domain of STR. Specifically, VIPTR leverages a visual-semantic extractor with a pyramid structure, characterized by multiple self-attention layers, while eschewing the traditional sequence decoder. This design choice results in a lightweight and efficient model capable of handling inputs of varying sizes. Extensive experimental results on various standard datasets for both Chinese and English scene text recognition validate the superiority of VIPTR. Notably, the VIPTR-T (Tiny) variant delivers highly competitive accuracy on par with other lightweight models and achieves SOTA inference speeds. Meanwhile, the VIPTR-L (Large) variant attains greater recognition accuracy, while maintaining a low parameter count and favorable inference speed. Our proposed method provides a compelling solution for the STR challenge, which blends high accuracy with efficiency and greatly benefits real-world applications requiring fast and reliable text recognition. The code is publicly available at https://github.com/cxfyxl/VIPTR.