 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Dialogue Topic Segmentation Model Based on Utterance Rewriting
Sep 12, 2024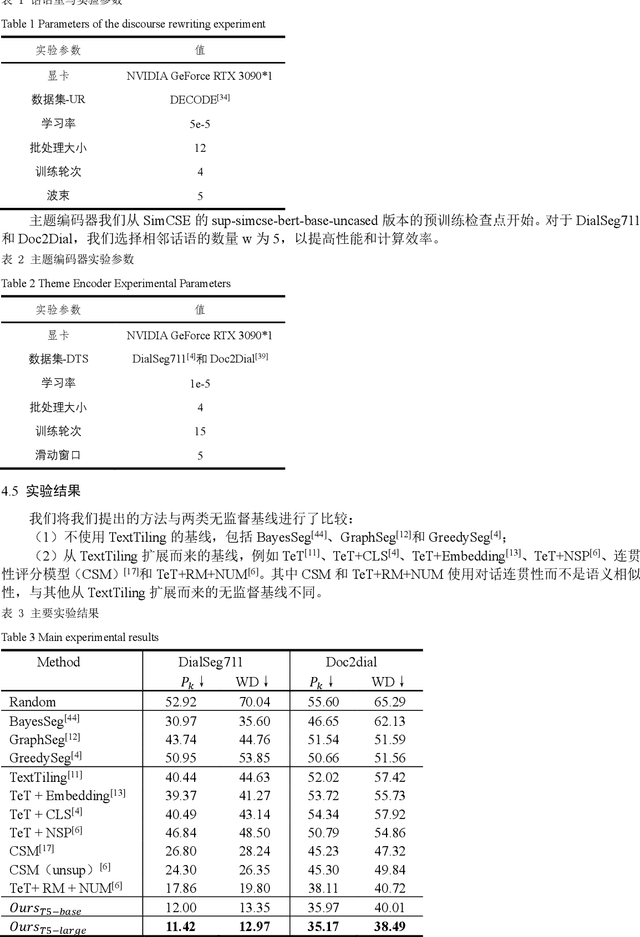
Dialogue topic segmentation plays a crucial role in various types of dialogue modeling tasks. The state-of-the-art unsupervised DTS methods learn topic-aware discourse representations from conversation data through adjacent discourse matching and pseudo segmentation to further mine useful clues in unlabeled conversational relations. However, in multi-round dialogs, discourses often have co-references or omissions, leading to the fact that direct use of these discourses for representation learning may negatively affect the semantic similarity computation in the neighboring discourse matching task. In order to fully utilize the useful cues in conversational relations, this study proposes a novel unsupervised dialog topic segmentation method that combines the Utterance Rewriting (UR) technique with an unsupervised learning algorithm to efficiently utilize the useful cues in unlabeled dialogs by rewriting the dialogs in order to recover the co-referents and omitted words. Compared with existing unsupervised models, the proposed Discourse Rewriting Topic Segmentation Model (UR-DTS) significantly improves the accuracy of topic segmentation. The main finding is that the performance on DialSeg711 improves by about 6% in terms of absolute error score and WD, achieving 11.42% in terms of absolute error score and 12.97% in terms of WD. on Doc2Dial the absolute error score and WD improves by about 3% and 2%, respectively, resulting in SOTA reaching 35.17% in terms of absolute error score and 38.49% in terms of WD. This shows that the model is very effective in capturing the nuances of conversational topics, as well as the usefulness and challenges of utilizing unlabeled conversations.
Raw Text is All you Need: Knowledge-intensive Multi-turn Instruction Tuning for Large Language Model
Jul 03, 2024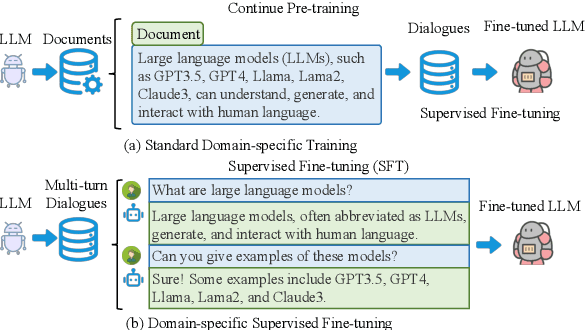



Instruction tuning as an effective technique aligns the outputs of large language models (LLMs) with human preference. But how to generate the seasonal multi-turn dialogues from raw documents for instruction tuning still requires further exploration. In this paper, we present a novel framework named R2S that leverages the CoD-Chain of Dialogue logic to guide large language models (LLMs) in generating knowledge-intensive multi-turn dialogues for instruction tuning. By integrating raw documents from both open-source datasets and domain-specific web-crawled documents into a benchmark K-BENCH, we cover diverse areas such as Wikipedia (English), Science (Chinese), and Artifacts (Chinese). Our approach first decides the logic flow of the current dialogue and then prompts LLMs to produce key phrases for sourcing relevant response content. This methodology enables the creation of the G I NSTRUCT instruction dataset, retaining raw document knowledge within dialoguestyle interactions. Utilizing this dataset, we fine-tune GLLM, a model designed to transform raw documents into structured multi-turn dialogues, thereby injecting comprehensive domain knowledge into the SFT model for enhanced instruction tuning. This work signifies a stride towards refining the adaptability and effectiveness of LLMs in processing and generating more accurate, contextually nuanced responses across various fields.