 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCM: Unifying Camera Control and Memory with Time-aware Positional Encoding Warping for World Models
Feb 26, 2026World models based on video generation demonstrate remarkable potential for simulating interactive environments but face persistent difficulties in two key areas: maintaining long-term content consistency when scenes are revisited and enabling precise camera control from user-provided inputs. Existing methods based on explicit 3D reconstruction often compromise flexibility in unbounded scenarios and fine-grained structures. Alternative methods rely directly on previously generated frames without establishing explicit spatial correspondence, thereby constraining controllability and consistency. To address these limitations, we present UCM, a novel framework that unifies long-term memory and precise camera control via a time-aware positional encoding warping mechanism. To reduce computational overhead, we design an efficient dual-stream diffusion transformer for high-fidelity generation. Moreover, we introduce a scalable data curation strategy utilizing point-cloud-based rendering to simulate scene revisiting, facilitating training on over 500K monocular videos. Extensive experiments on real-world and synthetic benchmarks demonstrate that UCM significantly outperforms state-of-the-art methods in long-term scene consistency, while also achieving precise camera controllability in high-fidelity video generation.
Cross-modal Retrieval Models for Stripped Binary Analysis
Dec 11, 2025
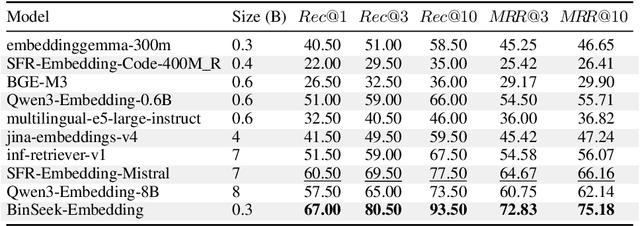
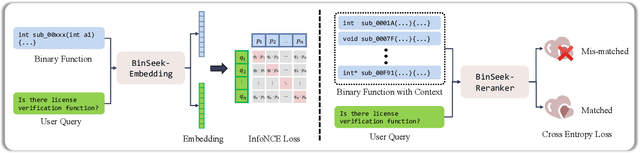
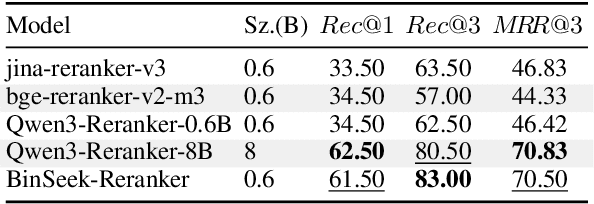
LLM-agent based binary code analysis has demonstrated significant potential across a wide range of software security scenarios, including vulnerability detection, malware analysis, etc. In agent workflow, however, retrieving the positive from thousands of stripped binary functions based on user query remains under-studied and challenging, as the absence of symbolic information distinguishes it from source code retrieval. In this paper, we introduce, BinSeek, the first two-stage cross-modal retrieval framework for stripped binary code analysis. It consists of two models: BinSeekEmbedding is trained on large-scale dataset to learn the semantic relevance of the binary code and the natural language description, furthermore, BinSeek-Reranker learns to carefully judge the relevance of the candidate code to the description with context augmentation. To this end, we built an LLM-based data synthesis pipeline to automate training construction, also deriving a domain benchmark for future research. Our evaluation results show that BinSeek achieved the state-of-the-art performance, surpassing the the same scale models by 31.42% in Rec@3 and 27.17% in MRR@3, as well as leading the advanced general-purpose models that have 16 times larger parameters.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

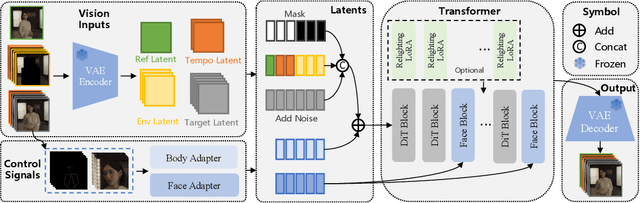
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Reminiscence Attack on Residuals: Exploiting Approximate Machine Unlearning for Privacy
Jul 28, 2025Machine unlearning enables the removal of specific data from ML models to uphold the right to be forgotten. While approximate unlearning algorithms offer efficient alternatives to full retraining, this work reveals that they fail to adequately protect the privacy of unlearned data. In particular, these algorithms introduce implicit residuals which facilitate privacy attacks targeting at unlearned data. We observe that these residuals persist regardless of model architectures, parameters, and unlearning algorithms, exposing a new attack surface beyond conventional output-based leakage. Based on this insight, we propose the Reminiscence Attack (ReA), which amplifies the correlation between residuals and membership privacy through targeted fine-tuning processes. ReA achieves up to 1.90x and 1.12x higher accuracy than prior attacks when inferring class-wise and sample-wise membership, respectively. To mitigate such residual-induced privacy risk, we develop a dual-phase approximate unlearning framework that first eliminates deep-layer unlearned data traces and then enforces convergence stability to prevent models from "pseudo-convergence", where their outputs are similar to retrained models but still preserve unlearned residuals. Our framework works for both classification and generation tasks. Experimental evaluations confirm that our approach maintains high unlearning efficacy, while reducing the adaptive privacy attack accuracy to nearly random guess, at the computational cost of 2-12% of full retraining from scratch.
dots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
Feb 10, 2025



Recent character image animation methods based on diffusion models, such as Animate Anyone, have made significant progress in generating consistent and generalizable character animations. However, these approaches fail to produce reasonable associations between characters and their environments. To address this limitation, we introduce Animate Anyone 2, aiming to animate characters with environment affordance. Beyond extracting motion signals from source video, we additionally capture environmental representations as conditional inputs. The environment is formulated as the region with the exclusion of characters and our model generates characters to populate these regions while maintaining coherence with the environmental context. We propose a shape-agnostic mask strategy that more effectively characterizes the relationship between character and environment. Furthermore, to enhance the fidelity of object interactions, we leverage an object guider to extract features of interacting objects and employ spatial blending for feature injection. We also introduce a pose modulation strategy that enables the model to handle more diverse motion patterns. Experimental results demonstrate the superior performance of the proposed method.
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Dec 07, 2023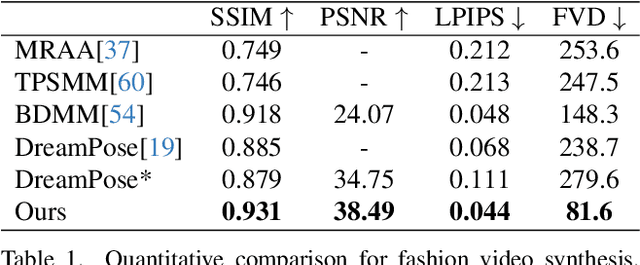
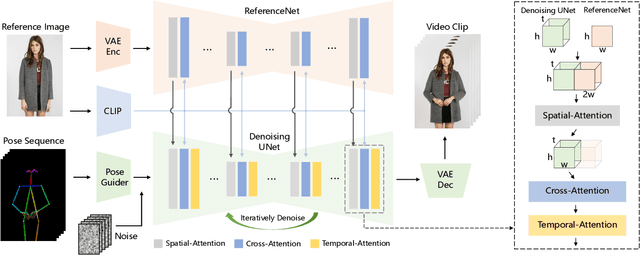
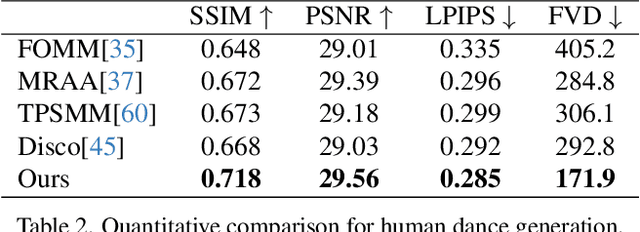

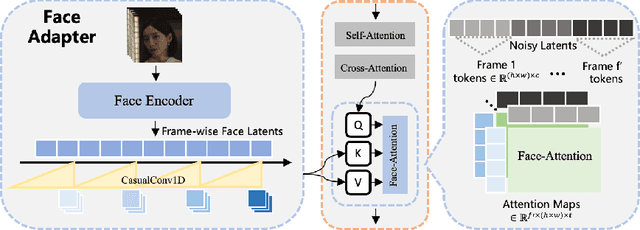
Character Animation aims to generating character videos from still images through driving signals. Currently, diffusion models have become the mainstream in visual generation research, owing to their robust generative capabilities. However, challenges persist in the realm of image-to-video, especially in character animation, where temporally maintaining consistency with detailed information from character remains a formidable problem. In this paper, we leverage the power of diffusion models and propose a novel framework tailored for character animation. To preserve consistency of intricate appearance features from reference image, we design ReferenceNet to merge detail features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guider to direct character's movements and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames. By expanding the training data, our approach can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. Furthermore, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
Recurrent Dynamic Embedding for Video Object Segmentation
May 08, 2022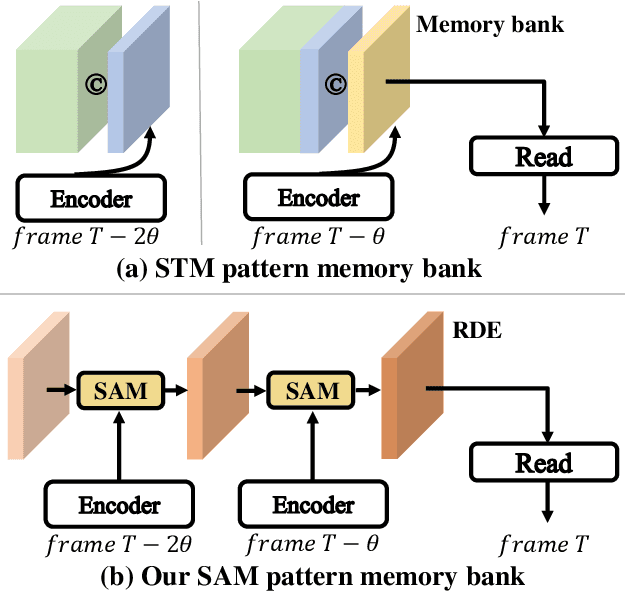
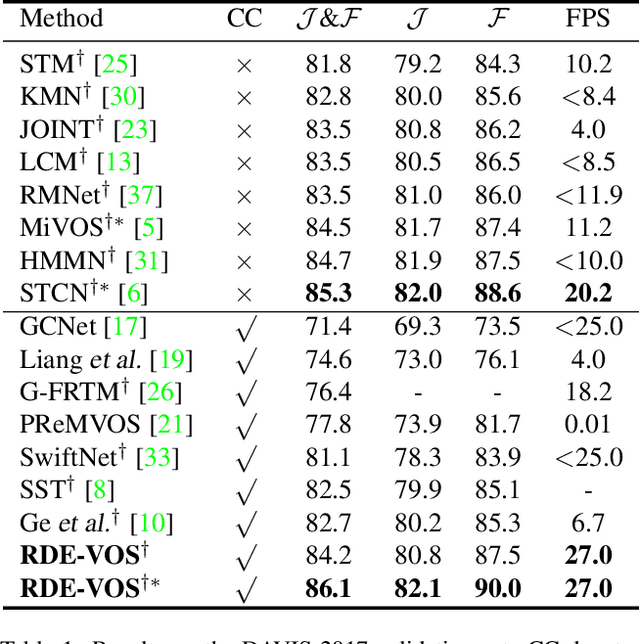
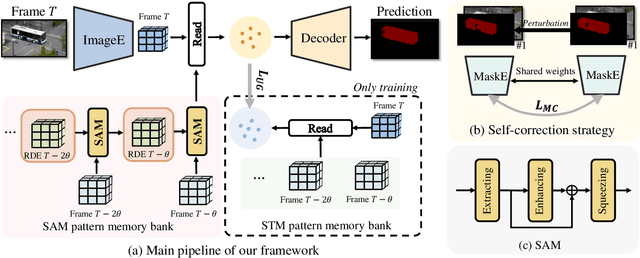
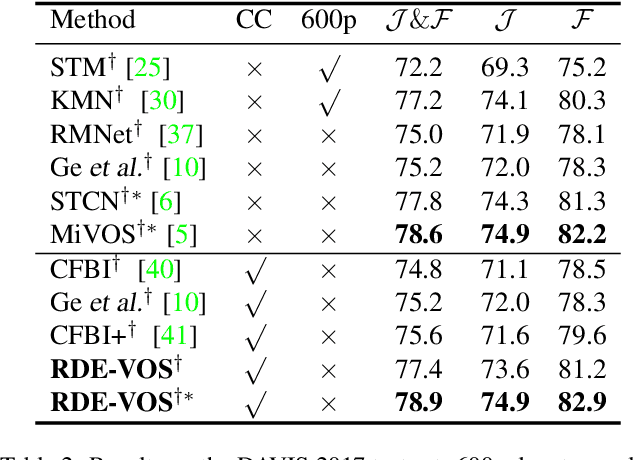
Space-time memory (STM) based video object segmentation (VOS) networks usually keep increasing memory bank every several frames, which shows excellent performance. However, 1) the hardware cannot withstand the ever-increasing memory requirements as the video length increases. 2) Storing lots of information inevitably introduces lots of noise, which is not conducive to reading the most important information from the memory bank. In this paper, we propose a Recurrent Dynamic Embedding (RDE) to build a memory bank of constant size. Specifically, we explicitly generate and update RDE by the proposed Spatio-temporal Aggregation Module (SAM), which exploits the cue of historical information. To avoid error accumulation owing to the recurrent usage of SAM, we propose an unbiased guidance loss during the training stage, which makes SAM more robust in long videos. Moreover, the predicted masks in the memory bank are inaccurate due to the inaccurate network inference, which affects the segmentation of the query frame. To address this problem, we design a novel self-correction strategy so that the network can repair the embeddings of masks with different qualities in the memory bank. Extensive experiments show our method achieves the best tradeoff between performance and speed. Code is available at https://github.com/Limingxing00/RDE-VOS-CVPR2022.
Learning Position and Target Consistency for Memory-based Video Object Segmentation
Apr 09, 2021
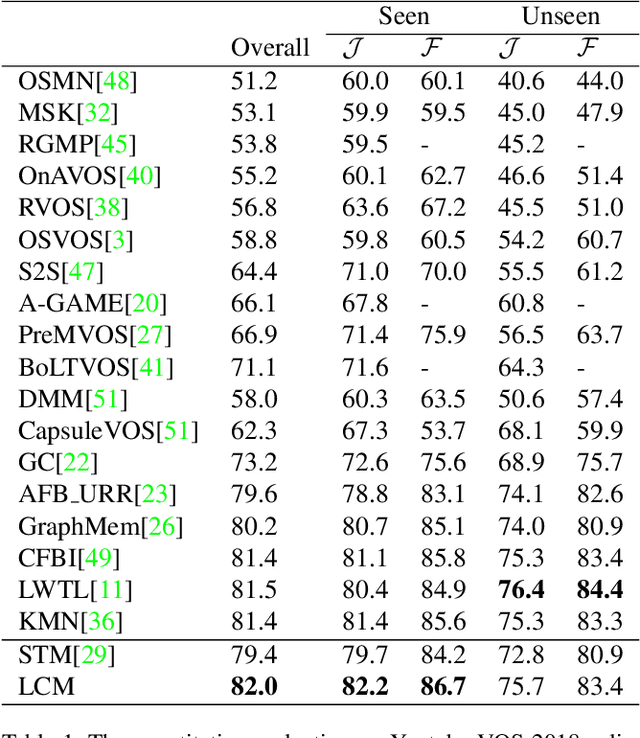
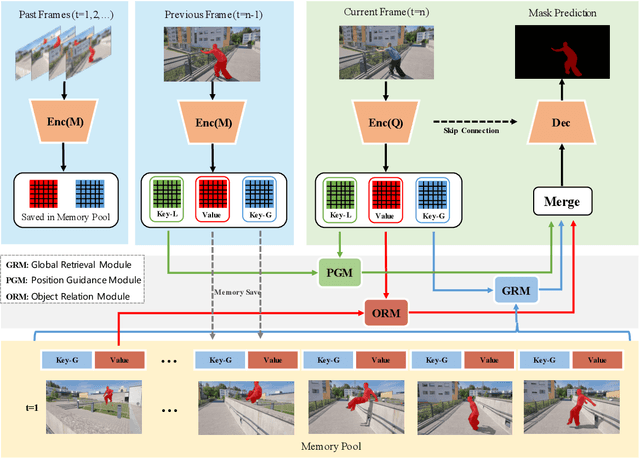
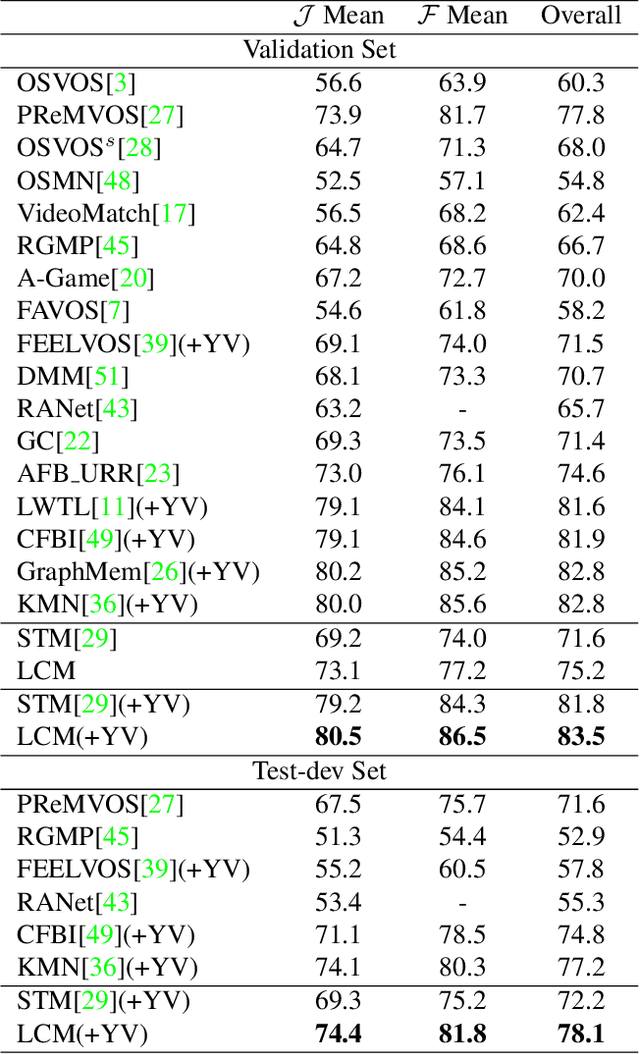
This paper studies the problem of semi-supervised video object segmentation(VOS). Multiple works have shown that memory-based approaches can be effective for video object segmentation. They are mostly based on pixel-level matching, both spatially and temporally. The main shortcoming of memory-based approaches is that they do not take into account the sequential order among frames and do not exploit object-level knowledge from the target. To address this limitation, we propose to Learn position and target Consistency framework for Memory-based video object segmentation, termed as LCM. It applies the memory mechanism to retrieve pixels globally, and meanwhile learns position consistency for more reliable segmentation. The learned location response promotes a better discrimination between target and distractors. Besides, LCM introduces an object-level relationship from the target to maintain target consistency, making LCM more robust to error drifting. Experiments show that our LCM achieves state-of-the-art performance on both DAVIS and Youtube-VOS benchmark. And we rank the 1st in the DAVIS 2020 challenge semi-supervised VOS task.
Machine Learning-based Signal Detection for PMH Signals in Load-modulated MIMO System
Nov 24, 2019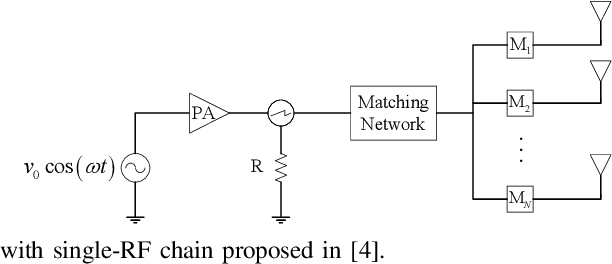
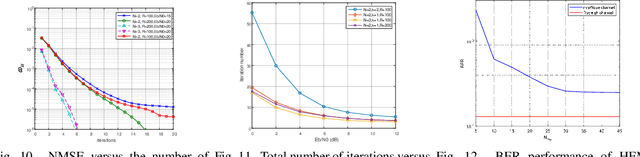

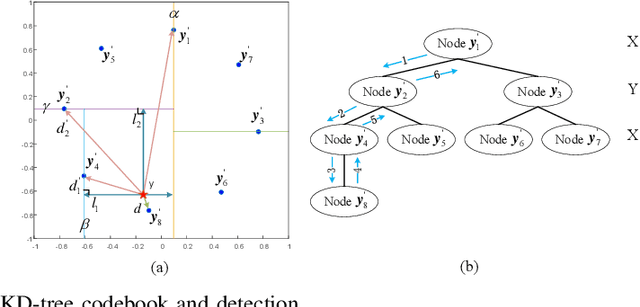
Phase Modulation on the Hypersphere (PMH) is a power efficient modulation scheme for the \textit{load-modulated} multiple-input multiple-output (MIMO) transmitters with central power amplifiers (CPA). However, it is difficult to obtain the precise channel state information (CSI), and the traditional optimal maximum likelihood (ML) detection scheme incurs high complexity which increases exponentially with the number of antennas and the number of bits carried per antenna in the PMH modulation. To detect the PMH signals without knowing the prior CSI, we first propose a signal detection scheme, termed as the hypersphere clustering scheme based on the expectation maximization (EM) algorithm with maximum likelihood detection (HEM-ML). By leveraging machine learning, the proposed detection scheme can accurately obtain information of the channel from a few of the received symbols with little resource cost and achieve comparable detection results as that of the optimal ML detector. To further reduce the computational complexity in the ML detection in HEM-ML, we also propose the second signal detection scheme, termed as the hypersphere clustering scheme based on the EM algorithm with KD-tree detection (HEM-KD). The CSI obtained from the EM algorithm is used to build a spatial KD-tree receiver codebook and the signal detection problem can be transformed into a nearest neighbor search (NNS) problem. The detection complexity of HEM-KD is significantly reduced without any detection performance loss as compared to HEM-ML. Extensive simulation results verify the effectiveness of our proposed detection schemes.