 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

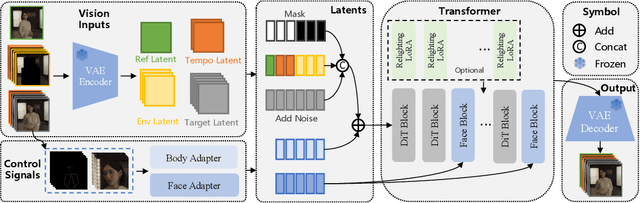
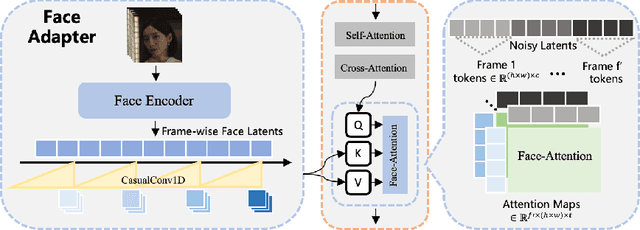
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Exploring Timeline Control for Facial Motion Generation
May 27, 2025This paper introduces a new control signal for facial motion generation: timeline control. Compared to audio and text signals, timelines provide more fine-grained control, such as generating specific facial motions with precise timing. Users can specify a multi-track timeline of facial actions arranged in temporal intervals, allowing precise control over the timing of each action. To model the timeline control capability, We first annotate the time intervals of facial actions in natural facial motion sequences at a frame-level granularity. This process is facilitated by Toeplitz Inverse Covariance-based Clustering to minimize human labor. Based on the annotations, we propose a diffusion-based generation model capable of generating facial motions that are natural and accurately aligned with input timelines. Our method supports text-guided motion generation by using ChatGPT to convert text into timelines. Experimental results show that our method can annotate facial action intervals with satisfactory accuracy, and produces natural facial motions accurately aligned with timelines.
OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication
Apr 03, 2025Recent years have witnessed remarkable advances in talking head generation, owing to its potential to revolutionize the human-AI interaction from text interfaces into realistic video chats. However, research on text-driven talking heads remains underexplored, with existing methods predominantly adopting a cascaded pipeline that combines TTS systems with audio-driven talking head models. This conventional pipeline not only introduces system complexity and latency overhead but also fundamentally suffers from asynchronous audiovisual output and stylistic discrepancies between generated speech and visual expressions. To address these limitations, we introduce OmniTalker, an end-to-end unified framework that simultaneously generates synchronized speech and talking head videos from text and reference video in real-time zero-shot scenarios, while preserving both speech style and facial styles. The framework employs a dual-branch diffusion transformer architecture: the audio branch synthesizes mel-spectrograms from text, while the visual branch predicts fine-grained head poses and facial dynamics. To bridge modalities, we introduce a novel audio-visual fusion module that integrates cross-modal information to ensure temporal synchronization and stylistic coherence between audio and visual outputs. Furthermore, our in-context reference learning module effectively captures both speech and facial style characteristics from a single reference video without introducing an extra style extracting module. To the best of our knowledge, OmniTalker presents the first unified framework that jointly models speech style and facial style in a zero-shot setting, achieving real-time inference speed of 25 FPS. Extensive experiments demonstrate that our method surpasses existing approaches in generation quality, particularly excelling in style preservation and audio-video synchronization.
ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model
Mar 27, 2025Real-time interactive video-chat portraits have been increasingly recognized as the future trend, particularly due to the remarkable progress made in text and voice chat technologies. However, existing methods primarily focus on real-time generation of head movements, but struggle to produce synchronized body motions that match these head actions. Additionally, achieving fine-grained control over the speaking style and nuances of facial expressions remains a challenge. To address these limitations, we introduce a novel framework for stylized real-time portrait video generation, enabling expressive and flexible video chat that extends from talking head to upper-body interaction. Our approach consists of the following two stages. The first stage involves efficient hierarchical motion diffusion models, that take both explicit and implicit motion representations into account based on audio inputs, which can generate a diverse range of facial expressions with stylistic control and synchronization between head and body movements. The second stage aims to generate portrait video featuring upper-body movements, including hand gestures. We inject explicit hand control signals into the generator to produce more detailed hand movements, and further perform face refinement to enhance the overall realism and expressiveness of the portrait video. Additionally, our approach supports efficient and continuous generation of upper-body portrait video in maximum 512 * 768 resolution at up to 30fps on 4090 GPU, supporting interactive video-chat in real-time. Experimental results demonstrate the capability of our approach to produce portrait videos with rich expressiveness and natural upper-body movements.
CM-GANs: Cross-modal Generative Adversarial Networks for Common Representation Learning
Apr 26, 2018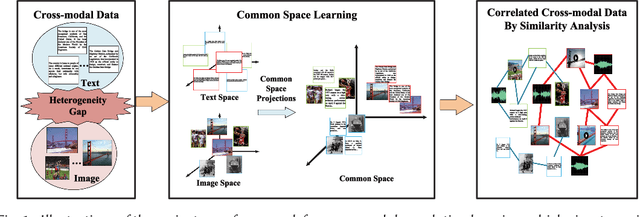
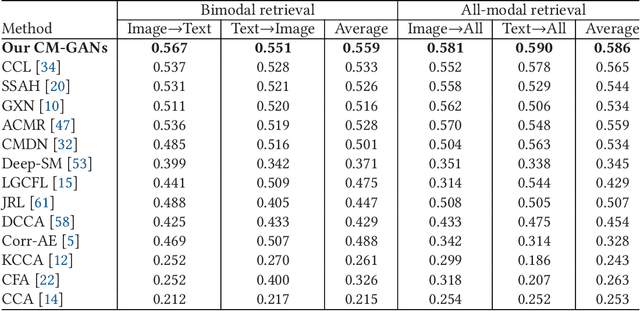
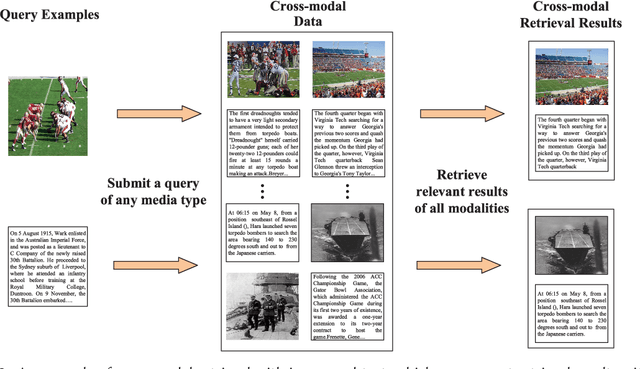
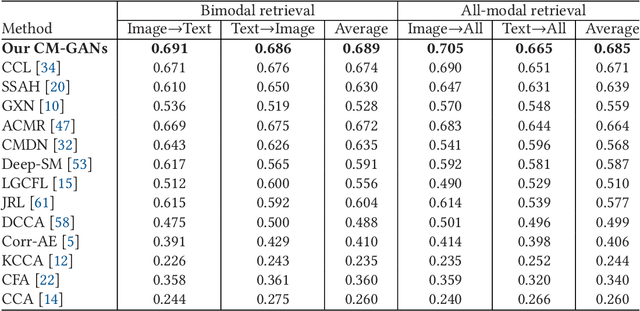
It is known that the inconsistent distribution and representation of different modalities, such as image and text, cause the heterogeneity gap that makes it challenging to correlate such heterogeneous data. Generative adversarial networks (GANs) have shown its strong ability of modeling data distribution and learning discriminative representation, existing GANs-based works mainly focus on generative problem to generate new data. We have different goal, aim to correlate heterogeneous data, by utilizing the power of GANs to model cross-modal joint distribution. Thus, we propose Cross-modal GANs to learn discriminative common representation for bridging heterogeneity gap. The main contributions are: (1) Cross-modal GANs architecture is proposed to model joint distribution over data of different modalities. The inter-modality and intra-modality correlation can be explored simultaneously in generative and discriminative models. Both of them beat each other to promote cross-modal correlation learning. (2) Cross-modal convolutional autoencoders with weight-sharing constraint are proposed to form generative model. They can not only exploit cross-modal correlation for learning common representation, but also preserve reconstruction information for capturing semantic consistency within each modality. (3) Cross-modal adversarial mechanism is proposed, which utilizes two kinds of discriminative models to simultaneously conduct intra-modality and inter-modality discrimination. They can mutually boost to make common representation more discriminative by adversarial training process. To the best of our knowledge, our proposed CM-GANs approach is the first to utilize GANs to perform cross-modal common representation learning. Experiments are conducted to verify the performance of our proposed approach on cross-modal retrieval paradigm, compared with 10 methods on 3 cross-modal datasets.
Modality-specific Cross-modal Similarity Measurement with Recurrent Attention Network
Aug 16, 2017

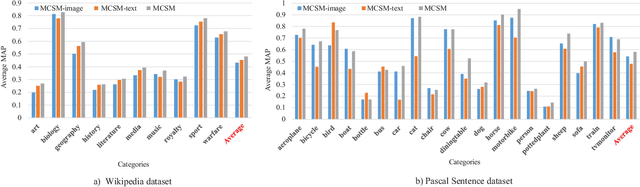

Nowadays, cross-modal retrieval plays an indispensable role to flexibly find information across different modalities of data. Effectively measuring the similarity between different modalities of data is the key of cross-modal retrieval. Different modalities such as image and text have imbalanced and complementary relationships, which contain unequal amount of information when describing the same semantics. For example, images often contain more details that cannot be demonstrated by textual descriptions and vice versa. Existing works based on Deep Neural Network (DNN) mostly construct one common space for different modalities to find the latent alignments between them, which lose their exclusive modality-specific characteristics. Different from the existing works, we propose modality-specific cross-modal similarity measurement (MCSM) approach by constructing independent semantic space for each modality, which adopts end-to-end framework to directly generate modality-specific cross-modal similarity without explicit common representation. For each semantic space, modality-specific characteristics within one modality are fully exploited by recurrent attention network, while the data of another modality is projected into this space with attention based joint embedding to utilize the learned attention weights for guiding the fine-grained cross-modal correlation learning, which can capture the imbalanced and complementary relationships between different modalities. Finally, the complementarity between the semantic spaces for different modalities is explored by adaptive fusion of the modality-specific cross-modal similarities to perform cross-modal retrieval. Experiments on the widely-used Wikipedia and Pascal Sentence datasets as well as our constructed large-scale XMediaNet dataset verify the effectiveness of our proposed approach, outperforming 9 state-of-the-art methods.
Cross-media Similarity Metric Learning with Unified Deep Networks
Apr 14, 2017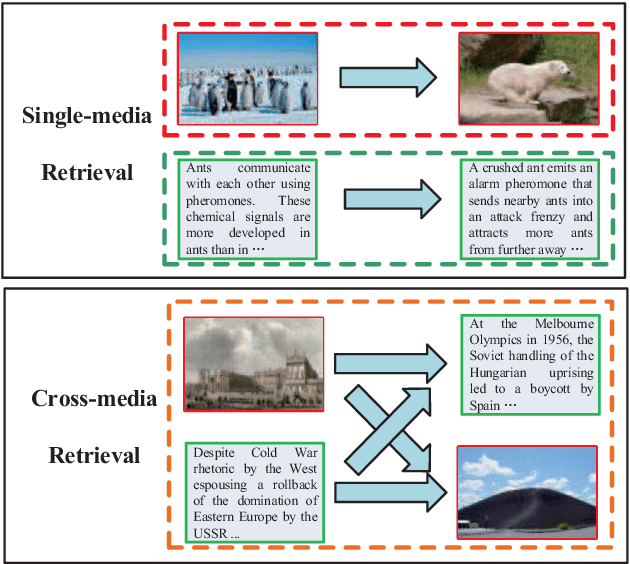
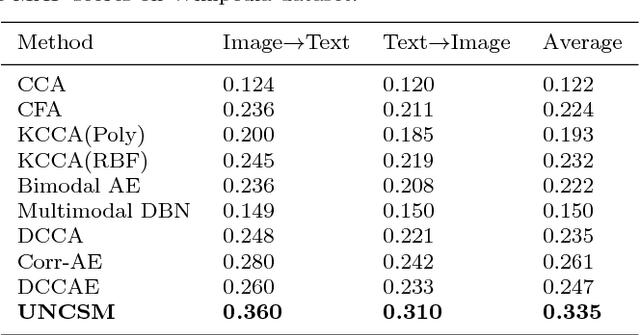

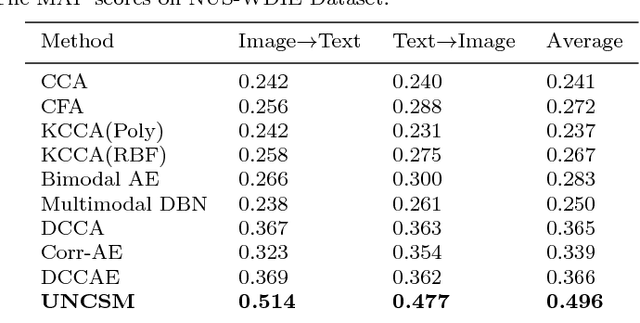
As a highlighting research topic in the multimedia area, cross-media retrieval aims to capture the complex correlations among multiple media types. Learning better shared representation and distance metric for multimedia data is important to boost the cross-media retrieval. Motivated by the strong ability of deep neural network in feature representation and comparison functions learning, we propose the Unified Network for Cross-media Similarity Metric (UNCSM) to associate cross-media shared representation learning with distance metric in a unified framework. First, we design a two-pathway deep network pretrained with contrastive loss, and employ double triplet similarity loss for fine-tuning to learn the shared representation for each media type by modeling the relative semantic similarity. Second, the metric network is designed for effectively calculating the cross-media similarity of the shared representation, by modeling the pairwise similar and dissimilar constraints. Compared to the existing methods which mostly ignore the dissimilar constraints and only use sample distance metric as Euclidean distance separately, our UNCSM approach unifies the representation learning and distance metric to preserve the relative similarity as well as embrace more complex similarity functions for further improving the cross-media retrieval accuracy. The experimental results show that our UNCSM approach outperforms 8 state-of-the-art methods on 4 widely-used cross-media datasets.