 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM-GANs: Cross-modal Generative Adversarial Networks for Common Representation Learning
Apr 26, 2018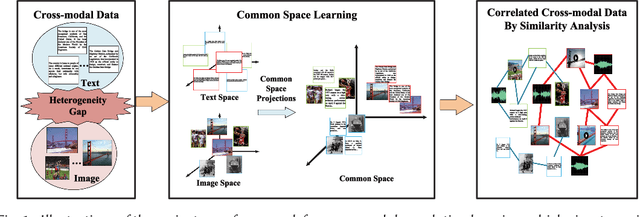
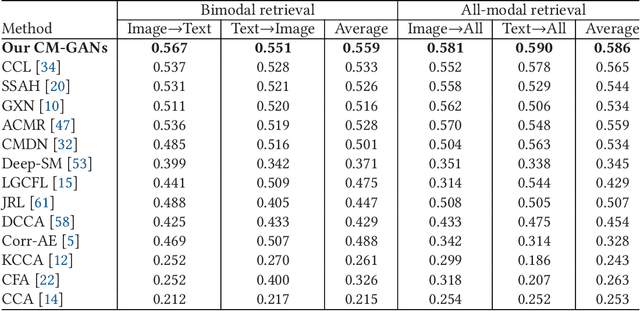
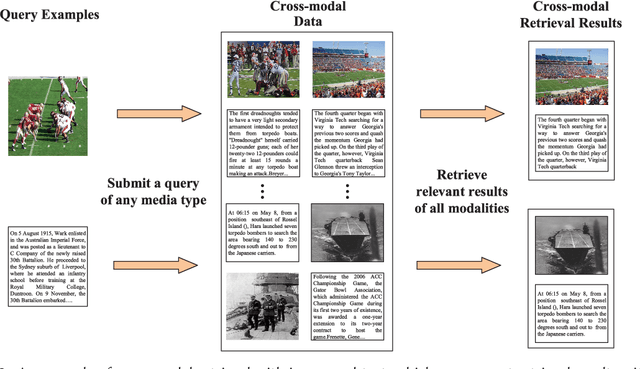
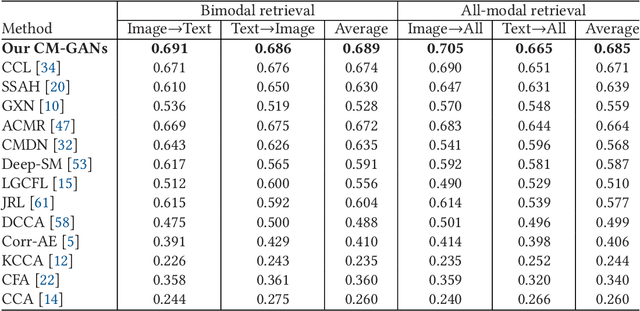
It is known that the inconsistent distribution and representation of different modalities, such as image and text, cause the heterogeneity gap that makes it challenging to correlate such heterogeneous data. Generative adversarial networks (GANs) have shown its strong ability of modeling data distribution and learning discriminative representation, existing GANs-based works mainly focus on generative problem to generate new data. We have different goal, aim to correlate heterogeneous data, by utilizing the power of GANs to model cross-modal joint distribution. Thus, we propose Cross-modal GANs to learn discriminative common representation for bridging heterogeneity gap. The main contributions are: (1) Cross-modal GANs architecture is proposed to model joint distribution over data of different modalities. The inter-modality and intra-modality correlation can be explored simultaneously in generative and discriminative models. Both of them beat each other to promote cross-modal correlation learning. (2) Cross-modal convolutional autoencoders with weight-sharing constraint are proposed to form generative model. They can not only exploit cross-modal correlation for learning common representation, but also preserve reconstruction information for capturing semantic consistency within each modality. (3) Cross-modal adversarial mechanism is proposed, which utilizes two kinds of discriminative models to simultaneously conduct intra-modality and inter-modality discrimination. They can mutually boost to make common representation more discriminative by adversarial training process. To the best of our knowledge, our proposed CM-GANs approach is the first to utilize GANs to perform cross-modal common representation learning. Experiments are conducted to verify the performance of our proposed approach on cross-modal retrieval paradigm, compared with 10 methods on 3 cross-modal datasets.
Modality-specific Cross-modal Similarity Measurement with Recurrent Attention Network
Aug 16, 2017

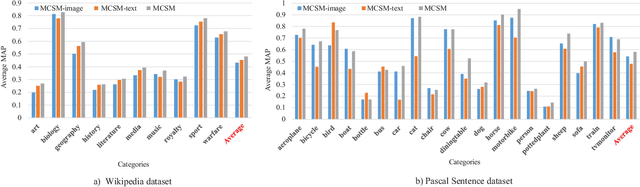

Nowadays, cross-modal retrieval plays an indispensable role to flexibly find information across different modalities of data. Effectively measuring the similarity between different modalities of data is the key of cross-modal retrieval. Different modalities such as image and text have imbalanced and complementary relationships, which contain unequal amount of information when describing the same semantics. For example, images often contain more details that cannot be demonstrated by textual descriptions and vice versa. Existing works based on Deep Neural Network (DNN) mostly construct one common space for different modalities to find the latent alignments between them, which lose their exclusive modality-specific characteristics. Different from the existing works, we propose modality-specific cross-modal similarity measurement (MCSM) approach by constructing independent semantic space for each modality, which adopts end-to-end framework to directly generate modality-specific cross-modal similarity without explicit common representation. For each semantic space, modality-specific characteristics within one modality are fully exploited by recurrent attention network, while the data of another modality is projected into this space with attention based joint embedding to utilize the learned attention weights for guiding the fine-grained cross-modal correlation learning, which can capture the imbalanced and complementary relationships between different modalities. Finally, the complementarity between the semantic spaces for different modalities is explored by adaptive fusion of the modality-specific cross-modal similarities to perform cross-modal retrieval. Experiments on the widely-used Wikipedia and Pascal Sentence datasets as well as our constructed large-scale XMediaNet dataset verify the effectiveness of our proposed approach, outperforming 9 state-of-the-art methods.