 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCa: Accelerating Video Diffusion Transformers with Distillation-Compatible Learnable Feature Caching
Feb 05, 2026While diffusion models have achieved great success in the field of video generation, this progress is accompanied by a rapidly escalating computational burden. Among the existing acceleration methods, Feature Caching is popular due to its training-free property and considerable speedup performance, but it inevitably faces semantic and detail drop with further compression. Another widely adopted method, training-aware step-distillation, though successful in image generation, also faces drastic degradation in video generation with a few steps. Furthermore, the quality loss becomes more severe when simply applying training-free feature caching to the step-distilled models, due to the sparser sampling steps. This paper novelly introduces a distillation-compatible learnable feature caching mechanism for the first time. We employ a lightweight learnable neural predictor instead of traditional training-free heuristics for diffusion models, enabling a more accurate capture of the high-dimensional feature evolution process. Furthermore, we explore the challenges of highly compressed distillation on large-scale video models and propose a conservative Restricted MeanFlow approach to achieve more stable and lossless distillation. By undertaking these initiatives, we further push the acceleration boundaries to $11.8\times$ while preserving generation quality. Extensive experiments demonstrate the effectiveness of our method. The code is in the supplementary materials and will be publicly available.
InspecSafe-V1: A Multimodal Benchmark for Safety Assessment in Industrial Inspection Scenarios
Jan 29, 2026With the rapid development of industrial intelligence and unmanned inspection, reliable perception and safety assessment for AI systems in complex and dynamic industrial sites has become a key bottleneck for deploying predictive maintenance and autonomous inspection. Most public datasets remain limited by simulated data sources, single-modality sensing, or the absence of fine-grained object-level annotations, which prevents robust scene understanding and multimodal safety reasoning for industrial foundation models. To address these limitations, InspecSafe-V1 is released as the first multimodal benchmark dataset for industrial inspection safety assessment that is collected from routine operations of real inspection robots in real-world environments. InspecSafe-V1 covers five representative industrial scenarios, including tunnels, power facilities, sintering equipment, oil and gas petrochemical plants, and coal conveyor trestles. The dataset is constructed from 41 wheeled and rail-mounted inspection robots operating at 2,239 valid inspection sites, yielding 5,013 inspection instances. For each instance, pixel-level segmentation annotations are provided for key objects in visible-spectrum images. In addition, a semantic scene description and a corresponding safety level label are provided according to practical inspection tasks. Seven synchronized sensing modalities are further included, including infrared video, audio, depth point clouds, radar point clouds, gas measurements, temperature, and humidity, to support multimodal anomaly recognition, cross-modal fusion, and comprehensive safety assessment in industrial environments.
A Brain-inspired Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
Jan 21, 2026Recent advances in embodied intelligence have leveraged massive scaling of data and model parameters to master natural-language command following and multi-task control. In contrast, biological systems demonstrate an innate ability to acquire skills rapidly from sparse experience. Crucially, current robotic policies struggle to replicate the dynamic stability, reflexive responsiveness, and temporal memory inherent in biological motion. Here we present Neuromorphic Vision-Language-Action (NeuroVLA), a framework that mimics the structural organization of the bio-nervous system between the cortex, cerebellum, and spinal cord. We adopt a system-level bio-inspired design: a high-level model plans goals, an adaptive cerebellum module stabilizes motion using high-frequency sensors feedback, and a bio-inspired spinal layer executes lightning-fast actions generation. NeuroVLA represents the first deployment of a neuromorphic VLA on physical robotics, achieving state-of-the-art performance. We observe the emergence of biological motor characteristics without additional data or special guidance: it stops the shaking in robotic arms, saves significant energy(only 0.4w on Neuromorphic Processor), shows temporal memory ability and triggers safety reflexes in less than 20 milliseconds.
UniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
APEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
Spectral Discrepancy and Cross-modal Semantic Consistency Learning for Object Detection in Hyperspectral Image
Dec 20, 2025Hyperspectral images with high spectral resolution provide new insights into recognizing subtle differences in similar substances. However, object detection in hyperspectral images faces significant challenges in intra- and inter-class similarity due to the spatial differences in hyperspectral inter-bands and unavoidable interferences, e.g., sensor noises and illumination. To alleviate the hyperspectral inter-bands inconsistencies and redundancy, we propose a novel network termed \textbf{S}pectral \textbf{D}iscrepancy and \textbf{C}ross-\textbf{M}odal semantic consistency learning (SDCM), which facilitates the extraction of consistent information across a wide range of hyperspectral bands while utilizing the spectral dimension to pinpoint regions of interest. Specifically, we leverage a semantic consistency learning (SCL) module that utilizes inter-band contextual cues to diminish the heterogeneity of information among bands, yielding highly coherent spectral dimension representations. On the other hand, we incorporate a spectral gated generator (SGG) into the framework that filters out the redundant data inherent in hyperspectral information based on the importance of the bands. Then, we design the spectral discrepancy aware (SDA) module to enrich the semantic representation of high-level information by extracting pixel-level spectral features. Extensive experiments on two hyperspectral datasets demonstrate that our proposed method achieves state-of-the-art performance when compared with other ones.
VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
Dec 09, 2025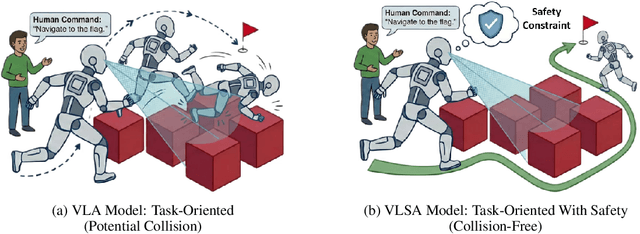
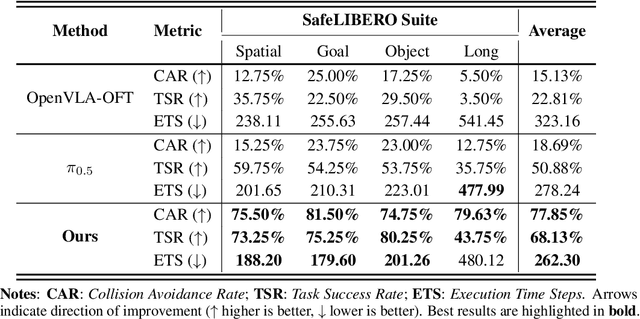
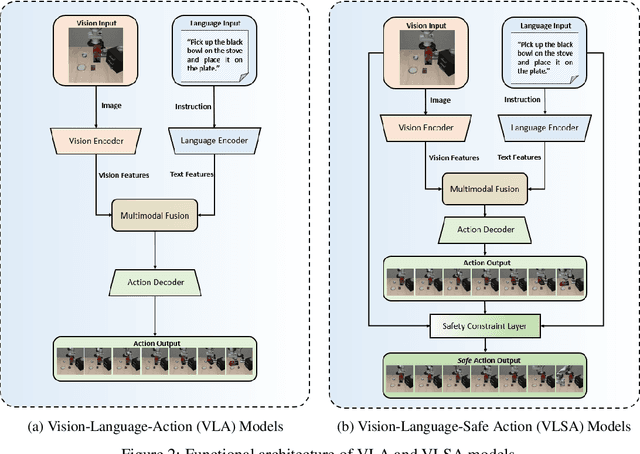
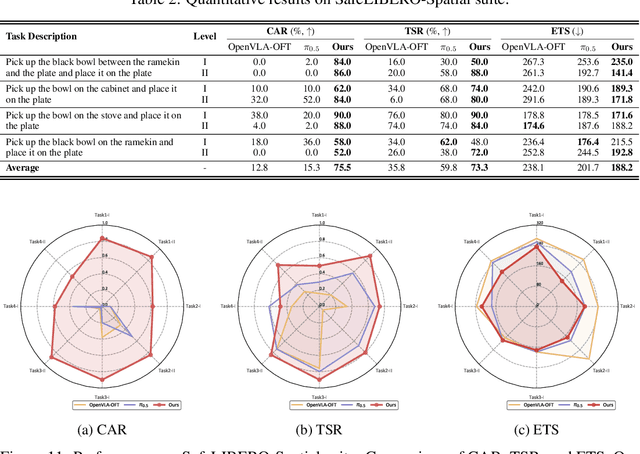
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in generalizing across diverse robotic manipulation tasks. However, deploying these models in unstructured environments remains challenging due to the critical need for simultaneous task compliance and safety assurance, particularly in preventing potential collisions during physical interactions. In this work, we introduce a Vision-Language-Safe Action (VLSA) architecture, named AEGIS, which contains a plug-and-play safety constraint (SC) layer formulated via control barrier functions. AEGIS integrates directly with existing VLA models to improve safety with theoretical guarantees, while maintaining their original instruction-following performance. To evaluate the efficacy of our architecture, we construct a comprehensive safety-critical benchmark SafeLIBERO, spanning distinct manipulation scenarios characterized by varying degrees of spatial complexity and obstacle intervention. Extensive experiments demonstrate the superiority of our method over state-of-the-art baselines. Notably, AEGIS achieves a 59.16% improvement in obstacle avoidance rate while substantially increasing the task execution success rate by 17.25%. To facilitate reproducibility and future research, we make our code, models, and the benchmark datasets publicly available at https://vlsa-aegis.github.io/.
ZeroCard: Cardinality Estimation with Zero Dependence on Target Databases -- No Data, No Query, No Retraining
Oct 09, 2025



Cardinality estimation is a fundamental task in database systems and plays a critical role in query optimization. Despite significant advances in learning-based cardinality estimation methods, most existing approaches remain difficult to generalize to new datasets due to their strong dependence on raw data or queries, thus limiting their practicality in real scenarios. To overcome these challenges, we argue that semantics in the schema may benefit cardinality estimation, and leveraging such semantics may alleviate these dependencies. To this end, we introduce ZeroCard, the first semantics-driven cardinality estimation method that can be applied without any dependence on raw data access, query logs, or retraining on the target database. Specifically, we propose to predict data distributions using schema semantics, thereby avoiding raw data dependence. Then, we introduce a query template-agnostic representation method to alleviate query dependence. Finally, we construct a large-scale query dataset derived from real-world tables and pretrain ZeroCard on it, enabling it to learn cardinality from schema semantics and predicate representations. After pretraining, ZeroCard's parameters can be frozen and applied in an off-the-shelf manner. We conduct extensive experiments to demonstrate the distinct advantages of ZeroCard and show its practical applications in query optimization. Its zero-dependence property significantly facilitates deployment in real-world scenarios.
Awesome-OL: An Extensible Toolkit for Online Learning
Jul 27, 2025In recent years, online learning has attracted increasing attention due to its adaptive capability to process streaming and non-stationary data. To facilitate algorithm development and practical deployment in this area, we introduce Awesome-OL, an extensible Python toolkit tailored for online learning research. Awesome-OL integrates state-of-the-art algorithm, which provides a unified framework for reproducible comparisons, curated benchmark datasets, and multi-modal visualization. Built upon the scikit-multiflow open-source infrastructure, Awesome-OL emphasizes user-friendly interactions without compromising research flexibility or extensibility. The source code is publicly available at: https://github.com/liuzy0708/Awesome-OL.
SURPRISE3D: A Dataset for Spatial Understanding and Reasoning in Complex 3D Scenes
Jul 10, 2025The integration of language and 3D perception is critical for embodied AI and robotic systems to perceive, understand, and interact with the physical world. Spatial reasoning, a key capability for understanding spatial relationships between objects, remains underexplored in current 3D vision-language research. Existing datasets often mix semantic cues (e.g., object name) with spatial context, leading models to rely on superficial shortcuts rather than genuinely interpreting spatial relationships. To address this gap, we introduce S\textsc{urprise}3D, a novel dataset designed to evaluate language-guided spatial reasoning segmentation in complex 3D scenes. S\textsc{urprise}3D consists of more than 200k vision language pairs across 900+ detailed indoor scenes from ScanNet++ v2, including more than 2.8k unique object classes. The dataset contains 89k+ human-annotated spatial queries deliberately crafted without object name, thereby mitigating shortcut biases in spatial understanding. These queries comprehensively cover various spatial reasoning skills, such as relative position, narrative perspective, parametric perspective, and absolute distance reasoning. Initial benchmarks demonstrate significant challenges for current state-of-the-art expert 3D visual grounding methods and 3D-LLMs, underscoring the necessity of our dataset and the accompanying 3D Spatial Reasoning Segmentation (3D-SRS) benchmark suite. S\textsc{urprise}3D and 3D-SRS aim to facilitate advancements in spatially aware AI, paving the way for effective embodied interaction and robotic planning. The code and datasets can be found in https://github.com/liziwennba/SUPRISE.