 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Step Back: Prefix Importance Ratio Stabilizes Policy Optimization
Jan 30, 2026Reinforcement learning (RL) post-training has increasingly demonstrated strong ability to elicit reasoning behaviors in large language models (LLMs). For training efficiency, rollouts are typically generated in an off-policy manner using an older sampling policy and then used to update the current target policy. To correct the resulting discrepancy between the sampling and target policies, most existing RL objectives rely on a token-level importance sampling ratio, primarily due to its computational simplicity and numerical stability. However, we observe that token-level correction often leads to unstable training dynamics when the degree of off-policyness is large. In this paper, we revisit LLM policy optimization under off-policy conditions and show that the theoretically rigorous correction term is the prefix importance ratio, and that relaxing it to a token-level approximation can induce instability in RL post-training. To stabilize LLM optimization under large off-policy drift, we propose a simple yet effective objective, Minimum Prefix Ratio (MinPRO). MinPRO replaces the unstable cumulative prefix ratio with a non-cumulative surrogate based on the minimum token-level ratio observed in the preceding prefix. Extensive experiments on both dense and mixture-of-experts LLMs, across multiple mathematical reasoning benchmarks, demonstrate that MinPRO substantially improves training stability and peak performance in off-policy regimes.
Offline Behavioral Data Selection
Dec 20, 2025


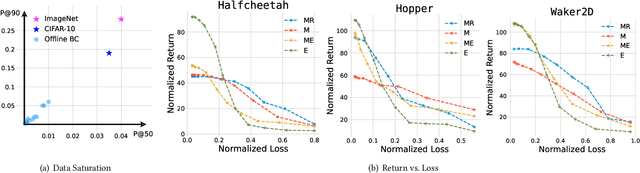
Behavioral cloning is a widely adopted approach for offline policy learning from expert demonstrations. However, the large scale of offline behavioral datasets often results in computationally intensive training when used in downstream tasks. In this paper, we uncover the striking data saturation in offline behavioral data: policy performance rapidly saturates when trained on a small fraction of the dataset. We attribute this effect to the weak alignment between policy performance and test loss, revealing substantial room for improvement through data selection. To this end, we propose a simple yet effective method, Stepwise Dual Ranking (SDR), which extracts a compact yet informative subset from large-scale offline behavioral datasets. SDR is build on two key principles: (1) stepwise clip, which prioritizes early-stage data; and (2) dual ranking, which selects samples with both high action-value rank and low state-density rank. Extensive experiments and ablation studies on D4RL benchmarks demonstrate that SDR significantly enhances data selection for offline behavioral data.
EarthSynth: Generating Informative Earth Observation with Diffusion Models
May 17, 2025Remote sensing image (RSI) interpretation typically faces challenges due to the scarcity of labeled data, which limits the performance of RSI interpretation tasks. To tackle this challenge, we propose EarthSynth, a diffusion-based generative foundation model that enables synthesizing multi-category, cross-satellite labeled Earth observation for downstream RSI interpretation tasks. To the best of our knowledge, EarthSynth is the first to explore multi-task generation for remote sensing. EarthSynth, trained on the EarthSynth-180K dataset, employs the Counterfactual Composition training strategy to improve training data diversity and enhance category control. Furthermore, a rule-based method of R-Filter is proposed to filter more informative synthetic data for downstream tasks. We evaluate our EarthSynth on scene classification, object detection, and semantic segmentation in open-world scenarios, offering a practical solution for advancing RSI interpretation.
Offline Behavior Distillation
Oct 30, 2024Massive reinforcement learning (RL) data are typically collected to train policies offline without the need for interactions, but the large data volume can cause training inefficiencies. To tackle this issue, we formulate offline behavior distillation (OBD), which synthesizes limited expert behavioral data from sub-optimal RL data, enabling rapid policy learning. We propose two naive OBD objectives, DBC and PBC, which measure distillation performance via the decision difference between policies trained on distilled data and either offline data or a near-expert policy. Due to intractable bi-level optimization, the OBD objective is difficult to minimize to small values, which deteriorates PBC by its distillation performance guarantee with quadratic discount complexity $\mathcal{O}(1/(1-\gamma)^2)$. We theoretically establish the equivalence between the policy performance and action-value weighted decision difference, and introduce action-value weighted PBC (Av-PBC) as a more effective OBD objective. By optimizing the weighted decision difference, Av-PBC achieves a superior distillation guarantee with linear discount complexity $\mathcal{O}(1/(1-\gamma))$. Extensive experiments on multiple D4RL datasets reveal that Av-PBC offers significant improvements in OBD performance, fast distillation convergence speed, and robust cross-architecture/optimizer generalization.
Image Captions are Natural Prompts for Text-to-Image Models
Jul 17, 2023With the rapid development of Artificial Intelligence Generated Content (AIGC), it has become common practice in many learning tasks to train or fine-tune large models on synthetic data due to the data-scarcity and privacy leakage problems. Albeit promising with unlimited data generation, owing to massive and diverse information conveyed in real images, it is challenging for text-to-image generative models to synthesize informative training data with hand-crafted prompts, which usually leads to inferior generalization performance when training downstream models. In this paper, we theoretically analyze the relationship between the training effect of synthetic data and the synthetic data distribution induced by prompts. Then we correspondingly propose a simple yet effective method that prompts text-to-image generative models to synthesize more informative and diverse training data. Specifically, we caption each real image with the advanced captioning model to obtain informative and faithful prompts that extract class-relevant information and clarify the polysemy of class names. The image captions and class names are concatenated to prompt generative models for training image synthesis. Extensive experiments on ImageNette, ImageNet-100, and ImageNet-1K verify that our method significantly improves the performance of models trained on synthetic training data, i.e., 10% classification accuracy improvements on average.
A Comprehensive Survey to Dataset Distillation
Jan 13, 2023



Deep learning technology has unprecedentedly developed in the last decade and has become the primary choice in many application domains. This progress is mainly attributed to a systematic collaboration that rapidly growing computing resources encourage advanced algorithms to deal with massive data. However, it gradually becomes challenging to cope with the unlimited growth of data with limited computing power. To this end, diverse approaches are proposed to improve data processing efficiency. Dataset distillation, one of the dataset reduction methods, tackles the problem via synthesising a small typical dataset from giant data and has attracted a lot of attention from the deep learning community. Existing dataset distillation methods can be taxonomised into meta-learning and data match framework according to whether explicitly mimic target data. Albeit dataset distillation has shown a surprising performance in compressing datasets, it still possesses several limitations such as distilling high-resolution data. This paper provides a holistic understanding of dataset distillation from multiple aspects, including distillation frameworks and algorithms, disentangled dataset distillation, performance comparison, and applications. Finally, we discuss challenges and promising directions to further promote future studies about dataset distillation.
Understanding deep learning via decision boundary
Jun 03, 2022

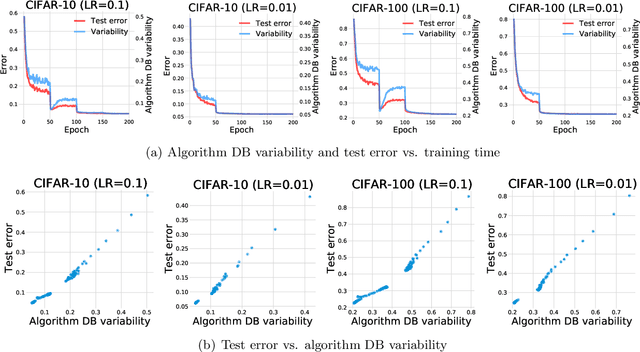

This paper discovers that the neural network with lower decision boundary (DB) variability has better generalizability. Two new notions, algorithm DB variability and $(\epsilon, \eta)$-data DB variability, are proposed to measure the decision boundary variability from the algorithm and data perspectives. Extensive experiments show significant negative correlations between the decision boundary variability and the generalizability. From the theoretical view, two lower bounds based on algorithm DB variability are proposed and do not explicitly depend on the sample size. We also prove an upper bound of order $\mathcal{O}\left(\frac{1}{\sqrt{m}}+\epsilon+\eta\log\frac{1}{\eta}\right)$ based on data DB variability. The bound is convenient to estimate without the requirement of labels, and does not explicitly depend on the network size which is usually prohibitively large in deep learning.
Spatial-Temporal-Fusion BNN: Variational Bayesian Feature Layer
Dec 12, 2021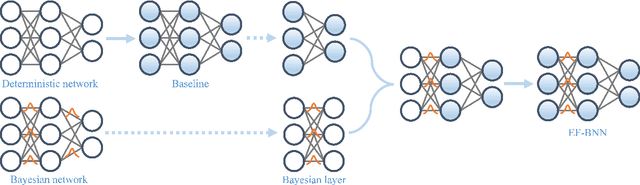
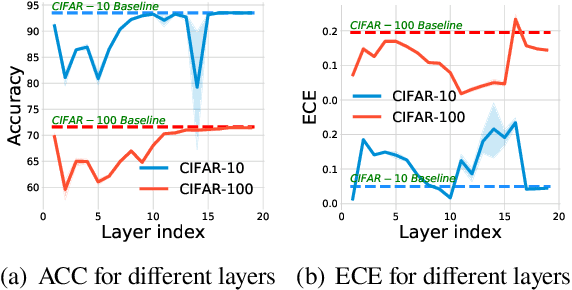
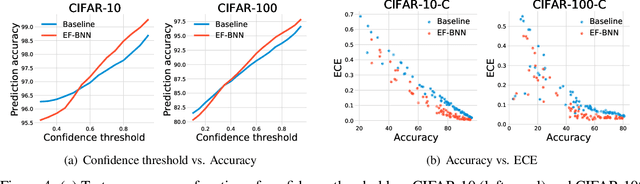
Bayesian neural networks (BNNs) have become a principal approach to alleviate overconfident predictions in deep learning, but they often suffer from scaling issues due to a large number of distribution parameters. In this paper, we discover that the first layer of a deep network possesses multiple disparate optima when solely retrained. This indicates a large posterior variance when the first layer is altered by a Bayesian layer, which motivates us to design a spatial-temporal-fusion BNN (STF-BNN) for efficiently scaling BNNs to large models: (1) first normally train a neural network from scratch to realize fast training; and (2) the first layer is converted to Bayesian and inferred by employing stochastic variational inference, while other layers are fixed. Compared to vanilla BNNs, our approach can greatly reduce the training time and the number of parameters, which contributes to scale BNNs efficiently. We further provide theoretical guarantees on the generalizability and the capability of mitigating overconfidence of STF-BNN. Comprehensive experiments demonstrate that STF-BNN (1) achieves the state-of-the-art performance on prediction and uncertainty quantification; (2) significantly improves adversarial robustness and privacy preservation; and (3) considerably reduces training time and memory costs.
Spectral Complexity-scaled Generalization Bound of Complex-valued Neural Networks
Dec 07, 2021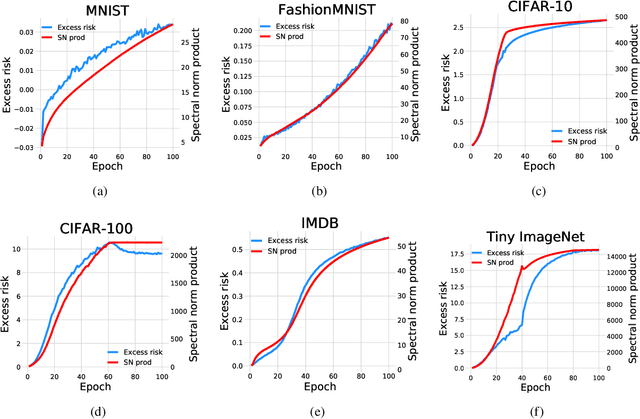
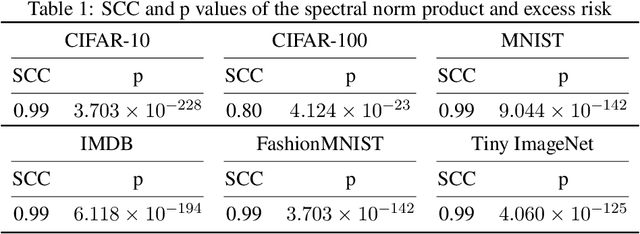
Complex-valued neural networks (CVNNs) have been widely applied to various fields, especially signal processing and image recognition. However, few works focus on the generalization of CVNNs, albeit it is vital to ensure the performance of CVNNs on unseen data. This paper is the first work that proves a generalization bound for the complex-valued neural network. The bound scales with the spectral complexity, the dominant factor of which is the spectral norm product of weight matrices. Further, our work provides a generalization bound for CVNNs when training data is sequential, which is also affected by the spectral complexity. Theoretically, these bounds are derived via Maurey Sparsification Lemma and Dudley Entropy Integral. Empirically, we conduct experiments by training complex-valued convolutional neural networks on different datasets: MNIST, FashionMNIST, CIFAR-10, CIFAR-100, Tiny ImageNet, and IMDB. Spearman's rank-order correlation coefficients and the corresponding p values on these datasets give strong proof that the spectral complexity of the network, measured by the weight matrices spectral norm product, has a statistically significant correlation with the generalization ability.
Neural networks behave as hash encoders: An empirical study
Jan 14, 2021



The input space of a neural network with ReLU-like activations is partitioned into multiple linear regions, each corresponding to a specific activation pattern of the included ReLU-like activations. We demonstrate that this partition exhibits the following encoding properties across a variety of deep learning models: (1) {\it determinism}: almost every linear region contains at most one training example. We can therefore represent almost every training example by a unique activation pattern, which is parameterized by a {\it neural code}; and (2) {\it categorization}: according to the neural code, simple algorithms, such as $K$-Means, $K$-NN, and logistic regression, can achieve fairly good performance on both training and test data. These encoding properties surprisingly suggest that {\it normal neural networks well-trained for classification behave as hash encoders without any extra efforts.} In addition, the encoding properties exhibit variability in different scenarios. {Further experiments demonstrate that {\it model size}, {\it training time}, {\it training sample size}, {\it regularization}, and {\it label noise} contribute in shaping the encoding properties, while the impacts of the first three are dominant.} We then define an {\it activation hash phase chart} to represent the space expanded by {model size}, training time, training sample size, and the encoding properties, which is divided into three canonical regions: {\it under-expressive regime}, {\it critically-expressive regime}, and {\it sufficiently-expressive regime}. The source code package is available at \url{https://github.com/LeavesLei/activation-code}.