 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Copy-Paste: Controllable Diffusion-Based Augmentation Method for Remote Sensing Few-Shot Object Detection
Jul 29, 2025



Few-shot object detection (FSOD) for optical remote sensing images aims to detect rare objects with only a few annotated bounding boxes. The limited training data makes it difficult to represent the data distribution of realistic remote sensing scenes, which results in the notorious overfitting problem. Current researchers have begun to enhance the diversity of few-shot novel instances by leveraging diffusion models to solve the overfitting problem. However, naively increasing the diversity of objects is insufficient, as surrounding contexts also play a crucial role in object detection, and in cases where the object diversity is sufficient, the detector tends to overfit to monotonous contexts. Accordingly, we propose Control Copy-Paste, a controllable diffusion-based method to enhance the performance of FSOD by leveraging diverse contextual information. Specifically, we seamlessly inject a few-shot novel objects into images with diverse contexts by a conditional diffusion model. We also develop an orientation alignment strategy to mitigate the integration distortion caused by varying aspect ratios of instances. Experiments on the public DIOR dataset demonstrate that our method can improve detection performance by an average of 10.76%.
EarthSynth: Generating Informative Earth Observation with Diffusion Models
May 17, 2025Remote sensing image (RSI) interpretation typically faces challenges due to the scarcity of labeled data, which limits the performance of RSI interpretation tasks. To tackle this challenge, we propose EarthSynth, a diffusion-based generative foundation model that enables synthesizing multi-category, cross-satellite labeled Earth observation for downstream RSI interpretation tasks. To the best of our knowledge, EarthSynth is the first to explore multi-task generation for remote sensing. EarthSynth, trained on the EarthSynth-180K dataset, employs the Counterfactual Composition training strategy to improve training data diversity and enhance category control. Furthermore, a rule-based method of R-Filter is proposed to filter more informative synthetic data for downstream tasks. We evaluate our EarthSynth on scene classification, object detection, and semantic segmentation in open-world scenarios, offering a practical solution for advancing RSI interpretation.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Enhance Then Search: An Augmentation-Search Strategy with Foundation Models for Cross-Domain Few-Shot Object Detection
Apr 06, 2025Foundation models pretrained on extensive datasets, such as GroundingDINO and LAE-DINO, have performed remarkably in the cross-domain few-shot object detection (CD-FSOD) task. Through rigorous few-shot training, we found that the integration of image-based data augmentation techniques and grid-based sub-domain search strategy significantly enhances the performance of these foundation models. Building upon GroundingDINO, we employed several widely used image augmentation methods and established optimization objectives to effectively navigate the expansive domain space in search of optimal sub-domains. This approach facilitates efficient few-shot object detection and introduces an approach to solving the CD-FSOD problem by efficiently searching for the optimal parameter configuration from the foundation model. Our findings substantially advance the practical deployment of vision-language models in data-scarce environments, offering critical insights into optimizing their cross-domain generalization capabilities without labor-intensive retraining. Code is available at https://github.com/jaychempan/ETS.
Locate Anything on Earth: Advancing Open-Vocabulary Object Detection for Remote Sensing Community
Aug 17, 2024Object detection, particularly open-vocabulary object detection, plays a crucial role in Earth sciences, such as environmental monitoring, natural disaster assessment, and land-use planning. However, existing open-vocabulary detectors, primarily trained on natural-world images, struggle to generalize to remote sensing images due to a significant data domain gap. Thus, this paper aims to advance the development of open-vocabulary object detection in remote sensing community. To achieve this, we first reformulate the task as Locate Anything on Earth (LAE) with the goal of detecting any novel concepts on Earth. We then developed the LAE-Label Engine which collects, auto-annotates, and unifies up to 10 remote sensing datasets creating the LAE-1M - the first large-scale remote sensing object detection dataset with broad category coverage. Using the LAE-1M, we further propose and train the novel LAE-DINO Model, the first open-vocabulary foundation object detector for the LAE task, featuring Dynamic Vocabulary Construction (DVC) and Visual-Guided Text Prompt Learning (VisGT) modules. DVC dynamically constructs vocabulary for each training batch, while VisGT maps visual features to semantic space, enhancing text features. We comprehensively conduct experiments on established remote sensing benchmark DIOR, DOTAv2.0, as well as our newly introduced 80-class LAE-80C benchmark. Results demonstrate the advantages of the LAE-1M dataset and the effectiveness of the LAE-DINO method.
PIR: Remote Sensing Image-Text Retrieval with Prior Instruction Representation Learning
May 16, 2024Remote sensing image-text retrieval constitutes a foundational aspect of remote sensing interpretation tasks, facilitating the alignment of vision and language representations. This paper introduces a prior instruction representation (PIR) learning paradigm that draws on prior knowledge to instruct adaptive learning of vision and text representations. Based on PIR, a domain-adapted remote sensing image-text retrieval framework PIR-ITR is designed to address semantic noise issues in vision-language understanding tasks. However, with massive additional data for pre-training the vision-language foundation model, remote sensing image-text retrieval is further developed into an open-domain retrieval task. Continuing with the above, we propose PIR-CLIP, a domain-specific CLIP-based framework for remote sensing image-text retrieval, to address semantic noise in remote sensing vision-language representations and further improve open-domain retrieval performance. In vision representation, Vision Instruction Representation (VIR) based on Spatial-PAE utilizes the prior-guided knowledge of the remote sensing scene recognition by building a belief matrix to select key features for reducing the impact of semantic noise. In text representation, Language Cycle Attention (LCA) based on Temporal-PAE uses the previous time step to cyclically activate the current time step to enhance text representation capability. A cluster-wise Affiliation Loss (AL) is proposed to constrain the inter-classes and to reduce the semantic confusion zones in the common subspace. Comprehensive experiments demonstrate that PIR could enhance vision and text representations and outperform the state-of-the-art methods of closed-domain and open-domain retrieval on two benchmark datasets, RSICD and RSITMD.
Direction-Oriented Visual-semantic Embedding Model for Remote Sensing Image-text Retrieval
Oct 12, 2023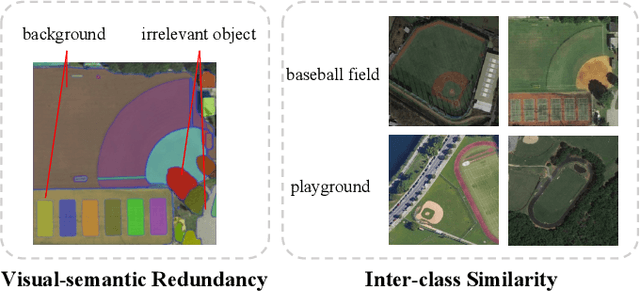
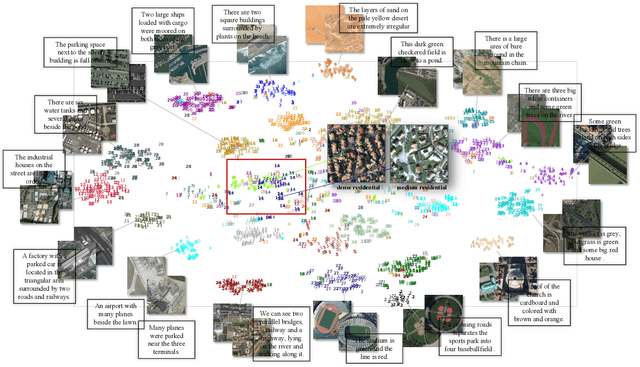
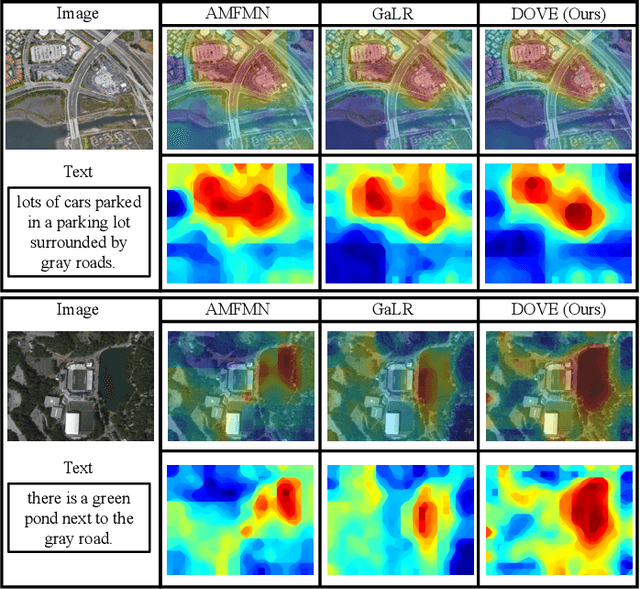
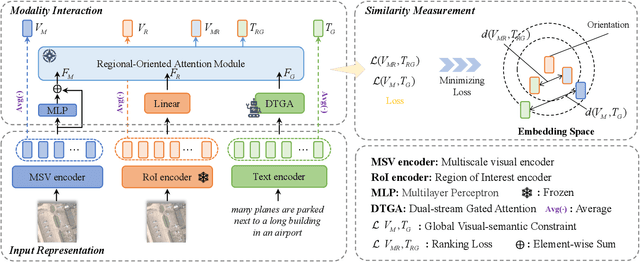
Image-text retrieval has developed rapidly in recent years. However, it is still a challenge in remote sensing due to visual-semantic imbalance, which leads to incorrect matching of non-semantic visual and textual features. To solve this problem, we propose a novel Direction-Oriented Visual-semantic Embedding Model (DOVE) to mine the relationship between vision and language. Concretely, a Regional-Oriented Attention Module (ROAM) adaptively adjusts the distance between the final visual and textual embeddings in the latent semantic space, oriented by regional visual features. Meanwhile, a lightweight Digging Text Genome Assistant (DTGA) is designed to expand the range of tractable textual representation and enhance global word-level semantic connections using less attention operations. Ultimately, we exploit a global visual-semantic constraint to reduce single visual dependency and serve as an external constraint for the final visual and textual representations. The effectiveness and superiority of our method are verified by extensive experiments including parameter evaluation, quantitative comparison, ablation studies and visual analysis, on two benchmark datasets, RSICD and RSITMD.