 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroCard: Cardinality Estimation with Zero Dependence on Target Databases -- No Data, No Query, No Retraining
Oct 09, 2025



Cardinality estimation is a fundamental task in database systems and plays a critical role in query optimization. Despite significant advances in learning-based cardinality estimation methods, most existing approaches remain difficult to generalize to new datasets due to their strong dependence on raw data or queries, thus limiting their practicality in real scenarios. To overcome these challenges, we argue that semantics in the schema may benefit cardinality estimation, and leveraging such semantics may alleviate these dependencies. To this end, we introduce ZeroCard, the first semantics-driven cardinality estimation method that can be applied without any dependence on raw data access, query logs, or retraining on the target database. Specifically, we propose to predict data distributions using schema semantics, thereby avoiding raw data dependence. Then, we introduce a query template-agnostic representation method to alleviate query dependence. Finally, we construct a large-scale query dataset derived from real-world tables and pretrain ZeroCard on it, enabling it to learn cardinality from schema semantics and predicate representations. After pretraining, ZeroCard's parameters can be frozen and applied in an off-the-shelf manner. We conduct extensive experiments to demonstrate the distinct advantages of ZeroCard and show its practical applications in query optimization. Its zero-dependence property significantly facilitates deployment in real-world scenarios.
PLM4NDV: Minimizing Data Access for Number of Distinct Values Estimation with Pre-trained Language Models
Apr 01, 2025



Number of Distinct Values (NDV) estimation of a multiset/column is a basis for many data management tasks, especially within databases. Despite decades of research, most existing methods require either a significant amount of samples through uniform random sampling or access to the entire column to produce estimates, leading to substantial data access costs and potentially ineffective estimations in scenarios with limited data access. In this paper, we propose leveraging semantic information, i.e., schema, to address these challenges. The schema contains rich semantic information that can benefit the NDV estimation. To this end, we propose PLM4NDV, a learned method incorporating Pre-trained Language Models (PLMs) to extract semantic schema information for NDV estimation. Specifically, PLM4NDV leverages the semantics of the target column and the corresponding table to gain a comprehensive understanding of the column's meaning. By using the semantics, PLM4NDV reduces data access costs, provides accurate NDV estimation, and can even operate effectively without any data access. Extensive experiments on a large-scale real-world dataset demonstrate the superiority of PLM4NDV over baseline methods. Our code is available at https://github.com/bytedance/plm4ndv.
Federated Temporal Graph Clustering
Oct 16, 2024
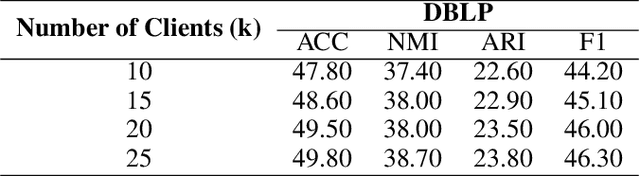
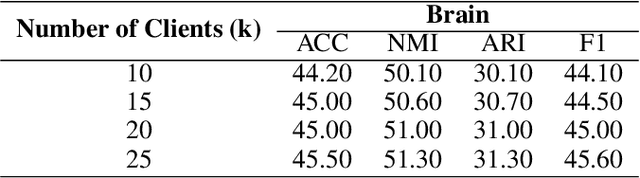

Temporal graph clustering is a complex task that involves discovering meaningful structures in dynamic graphs where relationships and entities change over time. Existing methods typically require centralized data collection, which poses significant privacy and communication challenges. In this work, we introduce a novel Federated Temporal Graph Clustering (FTGC) framework that enables decentralized training of graph neural networks (GNNs) across multiple clients, ensuring data privacy throughout the process. Our approach incorporates a temporal aggregation mechanism to effectively capture the evolution of graph structures over time and a federated optimization strategy to collaboratively learn high-quality clustering representations. By preserving data privacy and reducing communication overhead, our framework achieves competitive performance on temporal graph datasets, making it a promising solution for privacy-sensitive, real-world applications involving dynamic data.
Mining Interest Trends and Adaptively Assigning SampleWeight for Session-based Recommendation
Jun 20, 2023Session-based Recommendation (SR) aims to predict users' next click based on their behavior within a short period, which is crucial for online platforms. However, most existing SR methods somewhat ignore the fact that user preference is not necessarily strongly related to the order of interactions. Moreover, they ignore the differences in importance between different samples, which limits the model-fitting performance. To tackle these issues, we put forward the method, Mining Interest Trends and Adaptively Assigning Sample Weight, abbreviated as MTAW. Specifically, we model users' instant interest based on their present behavior and all their previous behaviors. Meanwhile, we discriminatively integrate instant interests to capture the changing trend of user interest to make more personalized recommendations. Furthermore, we devise a novel loss function that dynamically weights the samples according to their prediction difficulty in the current epoch. Extensive experimental results on two benchmark datasets demonstrate the effectiveness and superiority of our method.