 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Don't Tell: Detecting Novel Objects by Watching Human Videos
Mar 13, 2026How can a robot quickly identify and recognize new objects shown to it during a human demonstration? Existing closed-set object detectors frequently fail at this because the objects are out-of-distribution. While open-set detectors (e.g., VLMs) sometimes succeed, they often require expensive and tedious human-in-the-loop prompt engineering to uniquely recognize novel object instances. In this paper, we present a self-supervised system that eliminates the need for tedious language descriptions and expensive prompt engineering by training a bespoke object detector on an automatically created dataset, supervised by the human demonstration itself. In our approach, "Show, Don't Tell," we show the detector the specific objects of interest during the demonstration, rather than telling the detector about these objects via complex language descriptions. By bypassing language altogether, this paradigm enables us to quickly train bespoke detectors tailored to the relevant objects observed in human task demonstrations. We develop an integrated on-robot system to deploy our "Show, Don't Tell" paradigm of automatic dataset creation and novel object-detection on a real-world robot. Empirical results demonstrate that our pipeline significantly outperforms state-of-the-art detection and recognition methods for manipulated objects, leading to improved task completion for the robot.
Deep Projective Rotation Estimation through Relative Supervision
Nov 21, 2022Orientation estimation is the core to a variety of vision and robotics tasks such as camera and object pose estimation. Deep learning has offered a way to develop image-based orientation estimators; however, such estimators often require training on a large labeled dataset, which can be time-intensive to collect. In this work, we explore whether self-supervised learning from unlabeled data can be used to alleviate this issue. Specifically, we assume access to estimates of the relative orientation between neighboring poses, such that can be obtained via a local alignment method. While self-supervised learning has been used successfully for translational object keypoints, in this work, we show that naively applying relative supervision to the rotational group $SO(3)$ will often fail to converge due to the non-convexity of the rotational space. To tackle this challenge, we propose a new algorithm for self-supervised orientation estimation which utilizes Modified Rodrigues Parameters to stereographically project the closed manifold of $SO(3)$ to the open manifold of $\mathbb{R}^{3}$, allowing the optimization to be done in an open Euclidean space. We empirically validate the benefits of the proposed algorithm for rotational averaging problem in two settings: (1) direct optimization on rotation parameters, and (2) optimization of parameters of a convolutional neural network that predicts object orientations from images. In both settings, we demonstrate that our proposed algorithm is able to converge to a consistent relative orientation frame much faster than algorithms that purely operate in the $SO(3)$ space. Additional information can be found at https://sites.google.com/view/deep-projective-rotation/home .
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Nov 17, 2022



How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship ``cross-pose" and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
IFOR: Iterative Flow Minimization for Robotic Object Rearrangement
Feb 01, 2022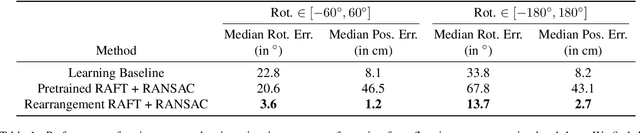
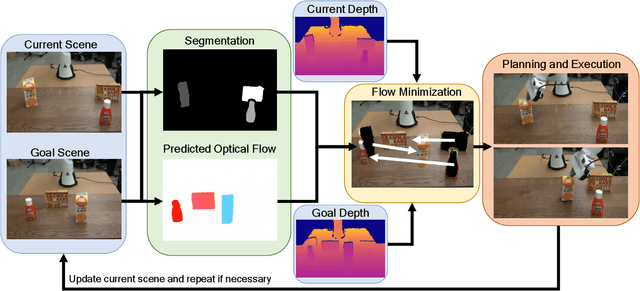


Accurate object rearrangement from vision is a crucial problem for a wide variety of real-world robotics applications in unstructured environments. We propose IFOR, Iterative Flow Minimization for Robotic Object Rearrangement, an end-to-end method for the challenging problem of object rearrangement for unknown objects given an RGBD image of the original and final scenes. First, we learn an optical flow model based on RAFT to estimate the relative transformation of the objects purely from synthetic data. This flow is then used in an iterative minimization algorithm to achieve accurate positioning of previously unseen objects. Crucially, we show that our method applies to cluttered scenes, and in the real world, while training only on synthetic data. Videos are available at https://imankgoyal.github.io/ifor.html.
OSSID: Online Self-Supervised Instance Detection by (and for) Pose Estimation
Jan 18, 2022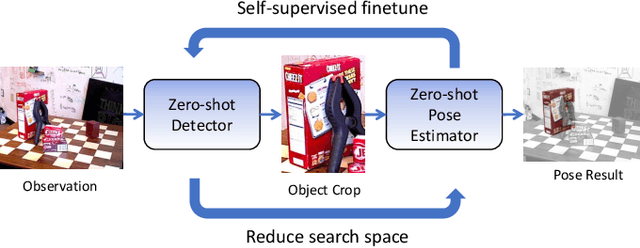
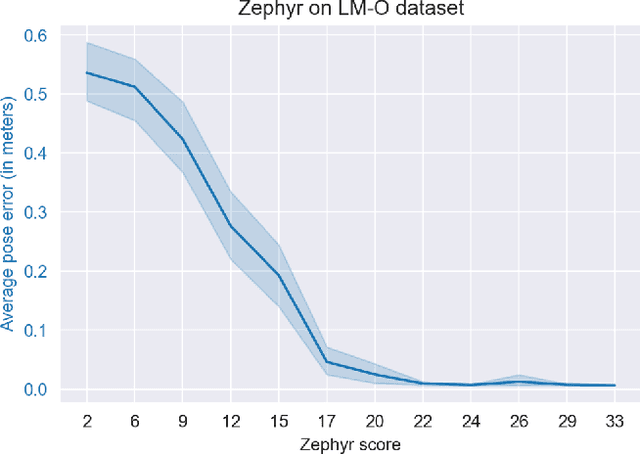
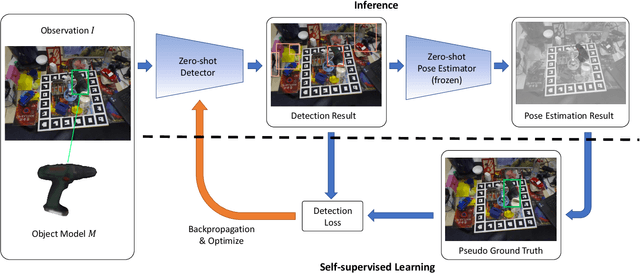
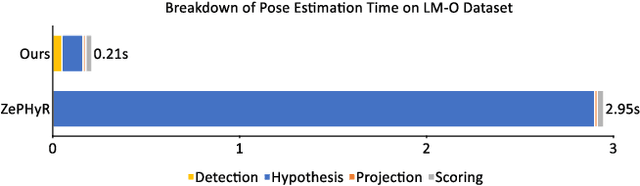
Real-time object pose estimation is necessary for many robot manipulation algorithms. However, state-of-the-art methods for object pose estimation are trained for a specific set of objects; these methods thus need to be retrained to estimate the pose of each new object, often requiring tens of GPU-days of training for optimal performance. \revisef{In this paper, we propose the OSSID framework,} leveraging a slow zero-shot pose estimator to self-supervise the training of a fast detection algorithm. This fast detector can then be used to filter the input to the pose estimator, drastically improving its inference speed. We show that this self-supervised training exceeds the performance of existing zero-shot detection methods on two widely used object pose estimation and detection datasets, without requiring any human annotations. Further, we show that the resulting method for pose estimation has a significantly faster inference speed, due to the ability to filter out large parts of the image. Thus, our method for self-supervised online learning of a detector (trained using pseudo-labels from a slow pose estimator) leads to accurate pose estimation at real-time speeds, without requiring human annotations. Supplementary materials and code can be found at https://georgegu1997.github.io/OSSID/
Self-Supervised Point Cloud Completion via Inpainting
Nov 21, 2021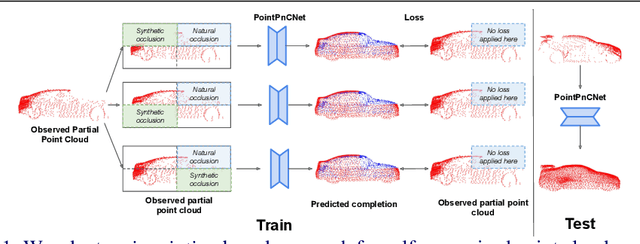
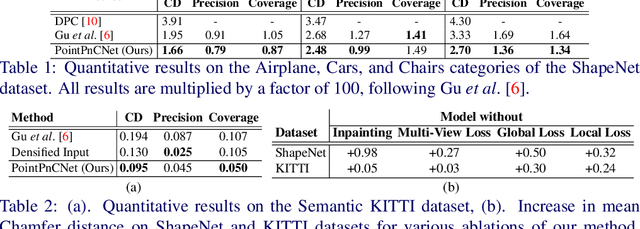

When navigating in urban environments, many of the objects that need to be tracked and avoided are heavily occluded. Planning and tracking using these partial scans can be challenging. The aim of this work is to learn to complete these partial point clouds, giving us a full understanding of the object's geometry using only partial observations. Previous methods achieve this with the help of complete, ground-truth annotations of the target objects, which are available only for simulated datasets. However, such ground truth is unavailable for real-world LiDAR data. In this work, we present a self-supervised point cloud completion algorithm, PointPnCNet, which is trained only on partial scans without assuming access to complete, ground-truth annotations. Our method achieves this via inpainting. We remove a portion of the input data and train the network to complete the missing region. As it is difficult to determine which regions were occluded in the initial cloud and which were synthetically removed, our network learns to complete the full cloud, including the missing regions in the initial partial cloud. We show that our method outperforms previous unsupervised and weakly-supervised methods on both the synthetic dataset, ShapeNet, and real-world LiDAR dataset, Semantic KITTI.
ZePHyR: Zero-shot Pose Hypothesis Rating
Apr 30, 2021
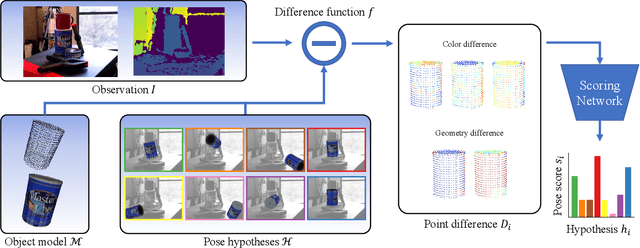

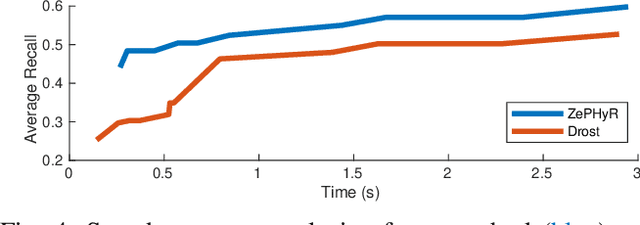
Pose estimation is a basic module in many robot manipulation pipelines. Estimating the pose of objects in the environment can be useful for grasping, motion planning, or manipulation. However, current state-of-the-art methods for pose estimation either rely on large annotated training sets or simulated data. Further, the long training times for these methods prohibit quick interaction with novel objects. To address these issues, we introduce a novel method for zero-shot object pose estimation in clutter. Our approach uses a hypothesis generation and scoring framework, with a focus on learning a scoring function that generalizes to objects not used for training. We achieve zero-shot generalization by rating hypotheses as a function of unordered point differences. We evaluate our method on challenging datasets with both textured and untextured objects in cluttered scenes and demonstrate that our method significantly outperforms previous methods on this task. We also demonstrate how our system can be used by quickly scanning and building a model of a novel object, which can immediately be used by our method for pose estimation. Our work allows users to estimate the pose of novel objects without requiring any retraining. Additional information can be found on our website https://bokorn.github.io/zephyr/
ROLL: Visual Self-Supervised Reinforcement Learning with Object Reasoning
Nov 13, 2020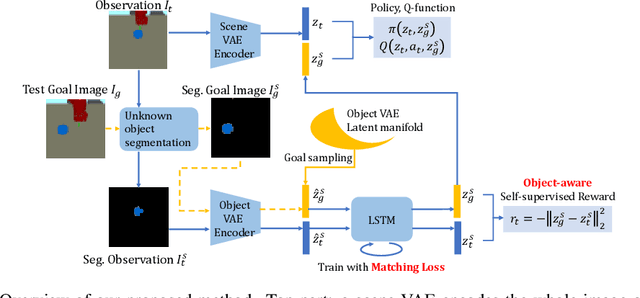


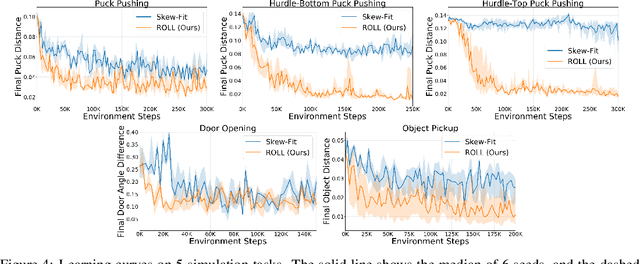
Current image-based reinforcement learning (RL) algorithms typically operate on the whole image without performing object-level reasoning. This leads to inefficient goal sampling and ineffective reward functions. In this paper, we improve upon previous visual self-supervised RL by incorporating object-level reasoning and occlusion reasoning. Specifically, we use unknown object segmentation to ignore distractors in the scene for better reward computation and goal generation; we further enable occlusion reasoning by employing a novel auxiliary loss and training scheme. We demonstrate that our proposed algorithm, ROLL (Reinforcement learning with Object Level Learning), learns dramatically faster and achieves better final performance compared with previous methods in several simulated visual control tasks. Project video and code are available at https://sites.google.com/andrew.cmu.edu/roll.
Robust Instance Tracking via Uncertainty Flow
Oct 09, 2020
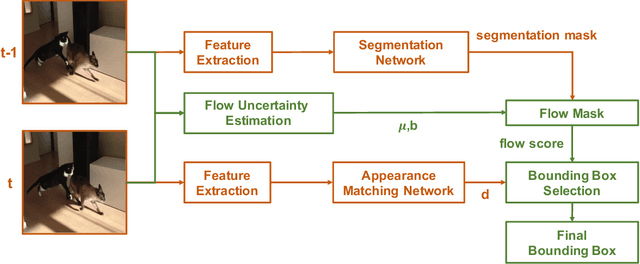
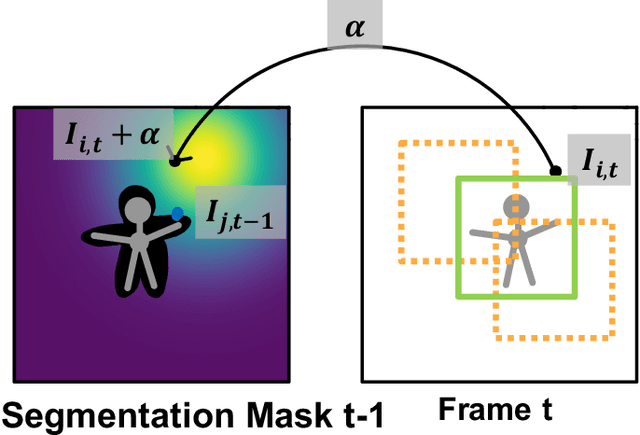
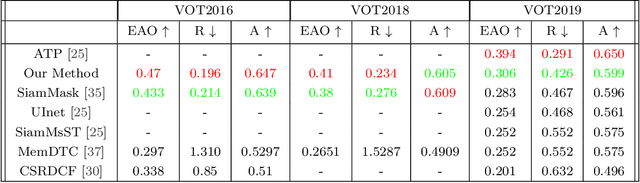
Current state-of-the-art trackers often fail due to distractorsand large object appearance changes. In this work, we explore the use ofdense optical flow to improve tracking robustness. Our main insight is that, because flow estimation can also have errors, we need to incorporate an estimate of flow uncertainty for robust tracking. We present a novel tracking framework which combines appearance and flow uncertainty information to track objects in challenging scenarios. We experimentally verify that our framework improves tracking robustness, leading to new state-of-the-art results. Further, our experimental ablations shows the importance of flow uncertainty for robust tracking.
Cloth Region Segmentation for Robust Grasp Selection
Aug 13, 2020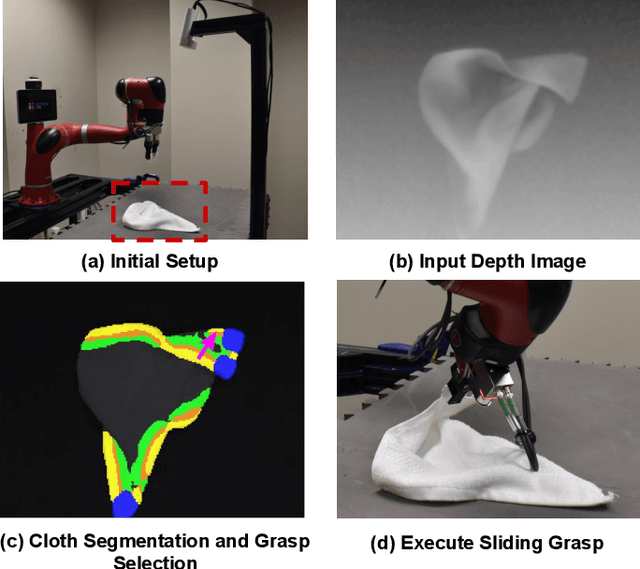
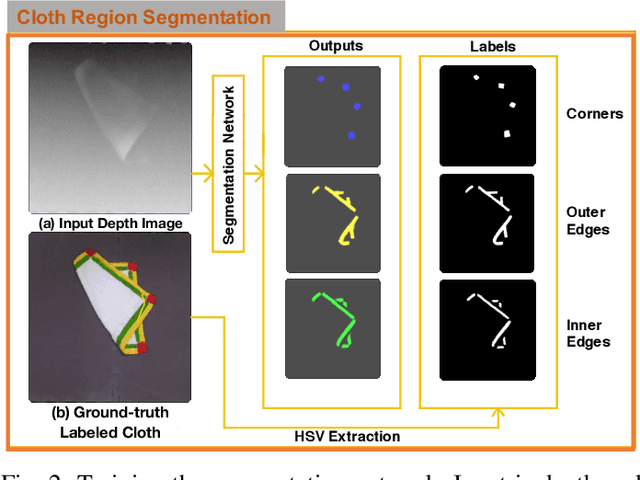
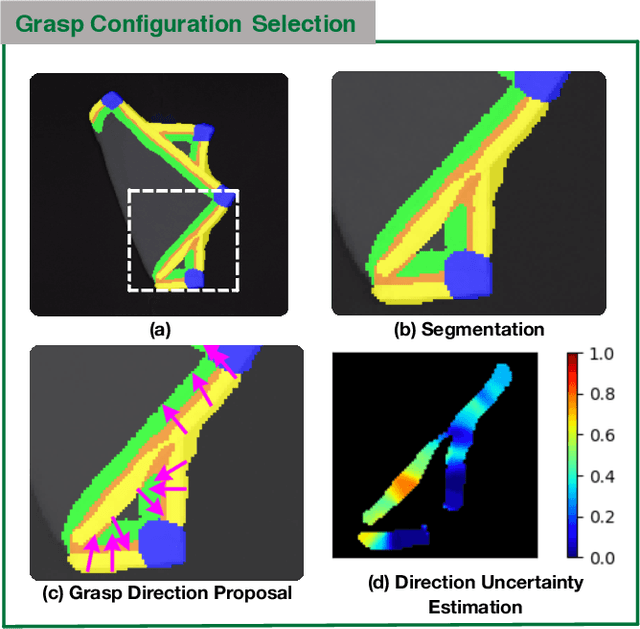

Cloth detection and manipulation is a common task in domestic and industrial settings, yet such tasks remain a challenge for robots due to cloth deformability. Furthermore, in many cloth-related tasks like laundry folding and bed making, it is crucial to manipulate specific regions like edges and corners, as opposed to folds. In this work, we focus on the problem of segmenting and grasping these key regions. Our approach trains a network to segment the edges and corners of a cloth from a depth image, distinguishing such regions from wrinkles or folds. We also provide a novel algorithm for estimating the grasp location, direction, and directional uncertainty from the segmentation. We demonstrate our method on a real robot system and show that it outperforms baseline methods on grasping success. Video and other supplementary materials are available at: https://sites.google.com/view/cloth-segmentation.