 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidar based 3D Tracking and State Estimation of Dynamic Objects
Apr 03, 2023State estimation of oncoming vehicles: Earlier research has been based on determining states like position, velocity, orientation , angular velocity, etc of ego-vehicle. Our approach focuses on estimating the states of non-ego vehicles which is crucial for Motion planning and decision-making. Dynamic Scene Based Localization: Our project will work on dynamic scenes like moving ego (self) and non-ego vehicles. Previous methods were focused on static environments.
Self-supervised Transparent Liquid Segmentation for Robotic Pouring
Mar 03, 2022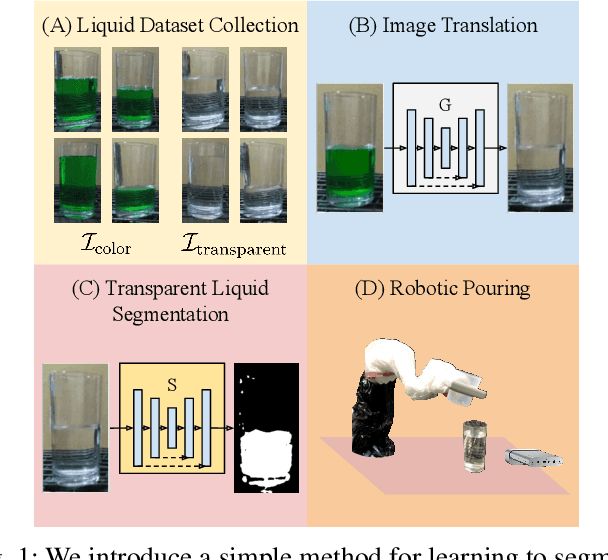
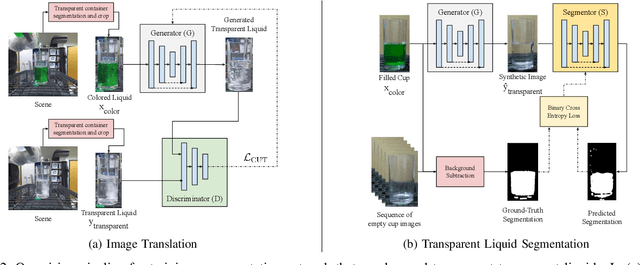
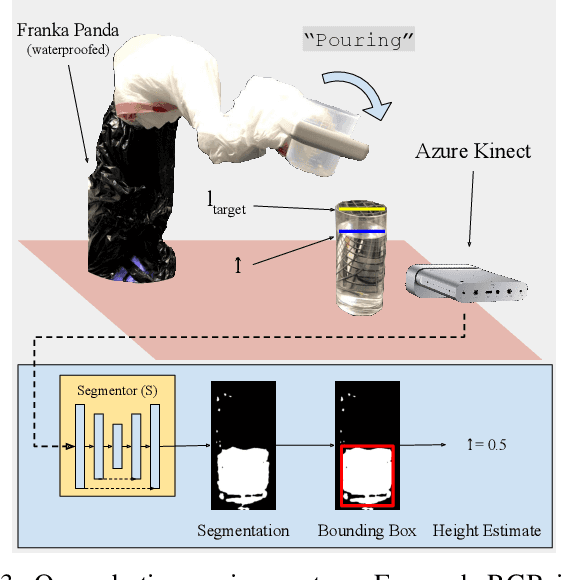

Liquid state estimation is important for robotics tasks such as pouring; however, estimating the state of transparent liquids is a challenging problem. We propose a novel segmentation pipeline that can segment transparent liquids such as water from a static, RGB image without requiring any manual annotations or heating of the liquid for training. Instead, we use a generative model that is capable of translating images of colored liquids into synthetically generated transparent liquid images, trained only on an unpaired dataset of colored and transparent liquid images. Segmentation labels of colored liquids are obtained automatically using background subtraction. Our experiments show that we are able to accurately predict a segmentation mask for transparent liquids without requiring any manual annotations. We demonstrate the utility of transparent liquid segmentation in a robotic pouring task that controls pouring by perceiving the liquid height in a transparent cup. Accompanying video and supplementary materials can be found
* Accepted at ICRA 2022
ROLL: Visual Self-Supervised Reinforcement Learning with Object Reasoning
Nov 13, 2020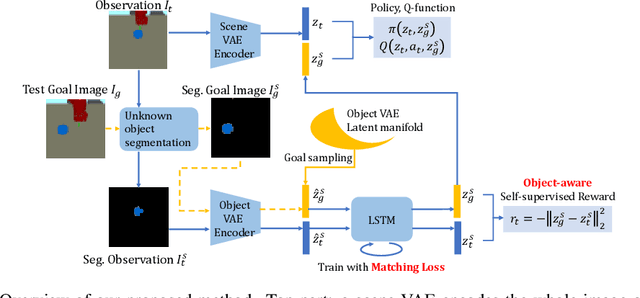


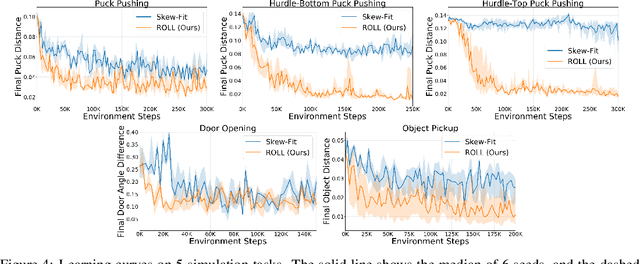
Current image-based reinforcement learning (RL) algorithms typically operate on the whole image without performing object-level reasoning. This leads to inefficient goal sampling and ineffective reward functions. In this paper, we improve upon previous visual self-supervised RL by incorporating object-level reasoning and occlusion reasoning. Specifically, we use unknown object segmentation to ignore distractors in the scene for better reward computation and goal generation; we further enable occlusion reasoning by employing a novel auxiliary loss and training scheme. We demonstrate that our proposed algorithm, ROLL (Reinforcement learning with Object Level Learning), learns dramatically faster and achieves better final performance compared with previous methods in several simulated visual control tasks. Project video and code are available at https://sites.google.com/andrew.cmu.edu/roll.