 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via Markov Likelihood
Oct 10, 2025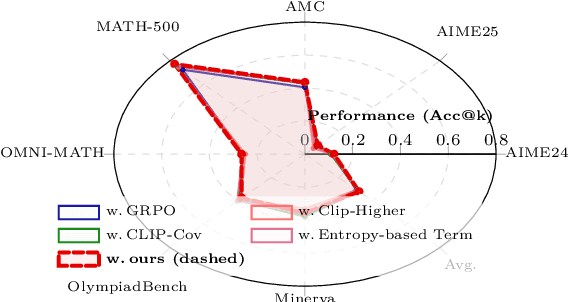
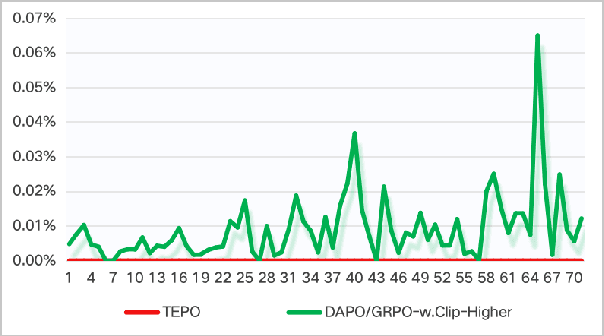
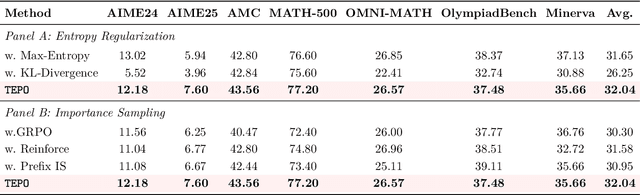
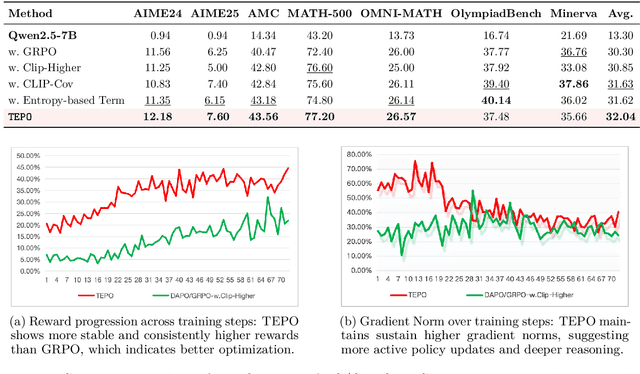
Group Relative Policy Optimization (GRPO) has significantly advanced the reasoning ability of large language models (LLMs), particularly by boosting their mathematical performance. However, GRPO and related entropy-regularization methods still face challenges rooted in the sparse token rewards inherent to chain-of-thought (CoT). Current approaches often rely on undifferentiated token-level entropy adjustments, which frequently lead to entropy collapse or model collapse. In this work, we propose TEPO, a novel token-level framework that incorporates Markov Likelihood (sequence likelihood) links group-level rewards with tokens via token-level aggregation. Experiments show that TEPO consistently outperforms existing baselines across key metrics (including @k and accuracy). It not only sets a new state of the art on mathematical reasoning tasks but also significantly enhances training stability.
RoboCopilot: Human-in-the-loop Interactive Imitation Learning for Robot Manipulation
Mar 10, 2025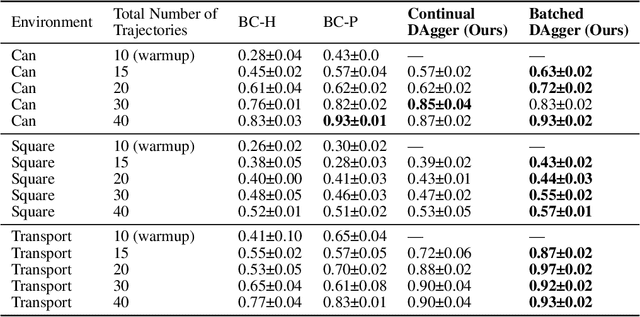
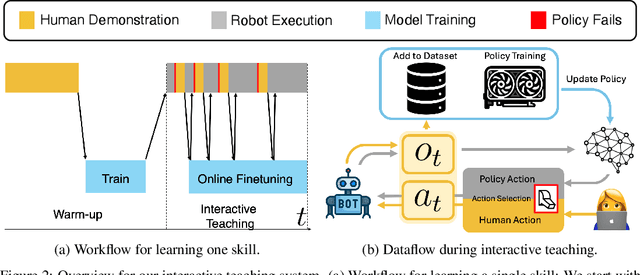
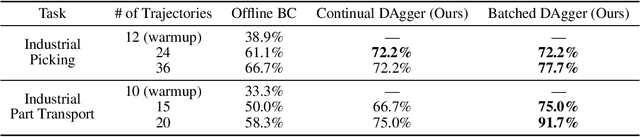
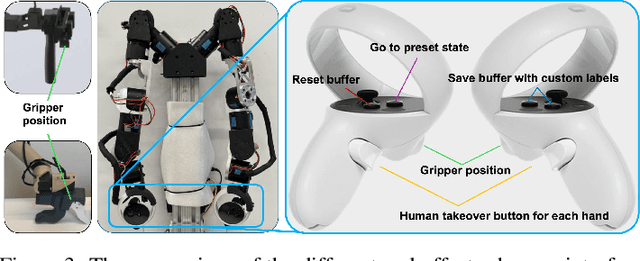
Learning from human demonstration is an effective approach for learning complex manipulation skills. However, existing approaches heavily focus on learning from passive human demonstration data for its simplicity in data collection. Interactive human teaching has appealing theoretical and practical properties, but they are not well supported by existing human-robot interfaces. This paper proposes a novel system that enables seamless control switching between human and an autonomous policy for bi-manual manipulation tasks, enabling more efficient learning of new tasks. This is achieved through a compliant, bilateral teleoperation system. Through simulation and hardware experiments, we demonstrate the value of our system in an interactive human teaching for learning complex bi-manual manipulation skills.
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
Mar 15, 2024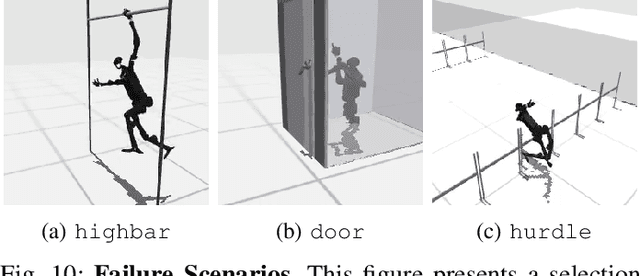


Humanoid robots hold great promise in assisting humans in diverse environments and tasks, due to their flexibility and adaptability leveraging human-like morphology. However, research in humanoid robots is often bottlenecked by the costly and fragile hardware setups. To accelerate algorithmic research in humanoid robots, we present a high-dimensional, simulated robot learning benchmark, HumanoidBench, featuring a humanoid robot equipped with dexterous hands and a variety of challenging whole-body manipulation and locomotion tasks. Our findings reveal that state-of-the-art reinforcement learning algorithms struggle with most tasks, whereas a hierarchical learning baseline achieves superior performance when supported by robust low-level policies, such as walking or reaching. With HumanoidBench, we provide the robotics community with a platform to identify the challenges arising when solving diverse tasks with humanoid robots, facilitating prompt verification of algorithms and ideas. The open-source code is available at https://sferrazza.cc/humanoidbench_site.
Any-point Trajectory Modeling for Policy Learning
Dec 28, 2023



Learning from demonstration is a powerful method for teaching robots new skills, and more demonstration data often improves policy learning. However, the high cost of collecting demonstration data is a significant bottleneck. Videos, as a rich data source, contain knowledge of behaviors, physics, and semantics, but extracting control-specific information from them is challenging due to the lack of action labels. In this work, we introduce a novel framework, Any-point Trajectory Modeling (ATM), that utilizes video demonstrations by pre-training a trajectory model to predict future trajectories of arbitrary points within a video frame. Once trained, these trajectories provide detailed control guidance, enabling the learning of robust visuomotor policies with minimal action-labeled data. Our method's effectiveness is demonstrated across 130 simulation tasks, focusing on language-conditioned manipulation tasks. Visualizations and code are available at: \url{https://xingyu-lin.github.io/atm}.
Learning Generalizable Tool-use Skills through Trajectory Generation
Oct 06, 2023



Autonomous systems that efficiently utilize tools can assist humans in completing many common tasks such as cooking and cleaning. However, current systems fall short of matching human-level of intelligence in terms of adapting to novel tools. Prior works based on affordance often make strong assumptions about the environments and cannot scale to more complex, contact-rich tasks. In this work, we tackle this challenge and explore how agents can learn to use previously unseen tools to manipulate deformable objects. We propose to learn a generative model of the tool-use trajectories as a sequence of point clouds, which generalizes to different tool shapes. Given any novel tool, we first generate a tool-use trajectory and then optimize the sequence of tool poses to align with the generated trajectory. We train a single model for four different challenging deformable object manipulation tasks. Our model is trained with demonstration data from just a single tool for each task and is able to generalize to various novel tools, significantly outperforming baselines. Additional materials can be found on our project website: https://sites.google.com/view/toolgen.
GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators
Sep 22, 2023



Imitation learning from human demonstrations is a powerful framework to teach robots new skills. However, the performance of the learned policies is bottlenecked by the quality, scale, and variety of the demonstration data. In this paper, we aim to lower the barrier to collecting large and high-quality human demonstration data by proposing GELLO, a general framework for building low-cost and intuitive teleoperation systems for robotic manipulation. Given a target robot arm, we build a GELLO controller that has the same kinematic structure as the target arm, leveraging 3D-printed parts and off-the-shelf motors. GELLO is easy to build and intuitive to use. Through an extensive user study, we show that GELLO enables more reliable and efficient demonstration collection compared to commonly used teleoperation devices in the imitation learning literature such as VR controllers and 3D spacemouses. We further demonstrate the capabilities of GELLO for performing complex bi-manual and contact-rich manipulation tasks. To make GELLO accessible to everyone, we have designed and built GELLO systems for 3 commonly used robotic arms: Franka, UR5, and xArm. All software and hardware are open-sourced and can be found on our website: https://wuphilipp.github.io/gello/.
SpawnNet: Learning Generalizable Visuomotor Skills from Pre-trained Networks
Jul 07, 2023



The existing internet-scale image and video datasets cover a wide range of everyday objects and tasks, bringing the potential of learning policies that have broad generalization. Prior works have explored visual pre-training with different self-supervised objectives, but the generalization capabilities of the learned policies remain relatively unknown. In this work, we take the first step towards this challenge, focusing on how pre-trained representations can help the generalization of the learned policies. We first identify the key bottleneck in using a frozen pre-trained visual backbone for policy learning. We then propose SpawnNet, a novel two-stream architecture that learns to fuse pre-trained multi-layer representations into a separate network to learn a robust policy. Through extensive simulated and real experiments, we demonstrate significantly better categorical generalization compared to prior approaches in imitation learning settings.
RoboNinja: Learning an Adaptive Cutting Policy for Multi-Material Objects
Feb 22, 2023



We introduce RoboNinja, a learning-based cutting system for multi-material objects (i.e., soft objects with rigid cores such as avocados or mangos). In contrast to prior works using open-loop cutting actions to cut through single-material objects (e.g., slicing a cucumber), RoboNinja aims to remove the soft part of an object while preserving the rigid core, thereby maximizing the yield. To achieve this, our system closes the perception-action loop by utilizing an interactive state estimator and an adaptive cutting policy. The system first employs sparse collision information to iteratively estimate the position and geometry of an object's core and then generates closed-loop cutting actions based on the estimated state and a tolerance value. The "adaptiveness" of the policy is achieved through the tolerance value, which modulates the policy's conservativeness when encountering collisions, maintaining an adaptive safety distance from the estimated core. Learning such cutting skills directly on a real-world robot is challenging. Yet, existing simulators are limited in simulating multi-material objects or computing the energy consumption during the cutting process. To address this issue, we develop a differentiable cutting simulator that supports multi-material coupling and allows for the generation of optimized trajectories as demonstrations for policy learning. Furthermore, by using a low-cost force sensor to capture collision feedback, we were able to successfully deploy the learned model in real-world scenarios, including objects with diverse core geometries and soft materials.
Self-supervised Cloth Reconstruction via Action-conditioned Cloth Tracking
Feb 19, 2023State estimation is one of the greatest challenges for cloth manipulation due to cloth's high dimensionality and self-occlusion. Prior works propose to identify the full state of crumpled clothes by training a mesh reconstruction model in simulation. However, such models are prone to suffer from a sim-to-real gap due to differences between cloth simulation and the real world. In this work, we propose a self-supervised method to finetune a mesh reconstruction model in the real world. Since the full mesh of crumpled cloth is difficult to obtain in the real world, we design a special data collection scheme and an action-conditioned model-based cloth tracking method to generate pseudo-labels for self-supervised learning. By finetuning the pretrained mesh reconstruction model on this pseudo-labeled dataset, we show that we can improve the quality of the reconstructed mesh without requiring human annotations, and improve the performance of downstream manipulation task.
Planning with Spatial-Temporal Abstraction from Point Clouds for Deformable Object Manipulation
Oct 27, 2022Effective planning of long-horizon deformable object manipulation requires suitable abstractions at both the spatial and temporal levels. Previous methods typically either focus on short-horizon tasks or make strong assumptions that full-state information is available, which prevents their use on deformable objects. In this paper, we propose PlAnning with Spatial-Temporal Abstraction (PASTA), which incorporates both spatial abstraction (reasoning about objects and their relations to each other) and temporal abstraction (reasoning over skills instead of low-level actions). Our framework maps high-dimension 3D observations such as point clouds into a set of latent vectors and plans over skill sequences on top of the latent set representation. We show that our method can effectively perform challenging sequential deformable object manipulation tasks in the real world, which require combining multiple tool-use skills such as cutting with a knife, pushing with a pusher, and spreading the dough with a roller.