 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-point Trajectory Modeling for Policy Learning
Dec 28, 2023



Learning from demonstration is a powerful method for teaching robots new skills, and more demonstration data often improves policy learning. However, the high cost of collecting demonstration data is a significant bottleneck. Videos, as a rich data source, contain knowledge of behaviors, physics, and semantics, but extracting control-specific information from them is challenging due to the lack of action labels. In this work, we introduce a novel framework, Any-point Trajectory Modeling (ATM), that utilizes video demonstrations by pre-training a trajectory model to predict future trajectories of arbitrary points within a video frame. Once trained, these trajectories provide detailed control guidance, enabling the learning of robust visuomotor policies with minimal action-labeled data. Our method's effectiveness is demonstrated across 130 simulation tasks, focusing on language-conditioned manipulation tasks. Visualizations and code are available at: \url{https://xingyu-lin.github.io/atm}.
SpawnNet: Learning Generalizable Visuomotor Skills from Pre-trained Networks
Jul 07, 2023



The existing internet-scale image and video datasets cover a wide range of everyday objects and tasks, bringing the potential of learning policies that have broad generalization. Prior works have explored visual pre-training with different self-supervised objectives, but the generalization capabilities of the learned policies remain relatively unknown. In this work, we take the first step towards this challenge, focusing on how pre-trained representations can help the generalization of the learned policies. We first identify the key bottleneck in using a frozen pre-trained visual backbone for policy learning. We then propose SpawnNet, a novel two-stream architecture that learns to fuse pre-trained multi-layer representations into a separate network to learn a robust policy. Through extensive simulated and real experiments, we demonstrate significantly better categorical generalization compared to prior approaches in imitation learning settings.
Sim-to-Real via Sim-to-Seg: End-to-end Off-road Autonomous Driving Without Real Data
Oct 25, 2022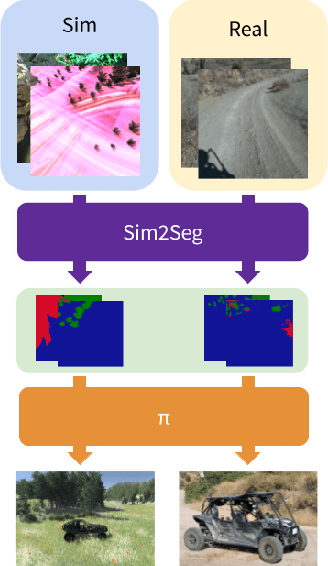
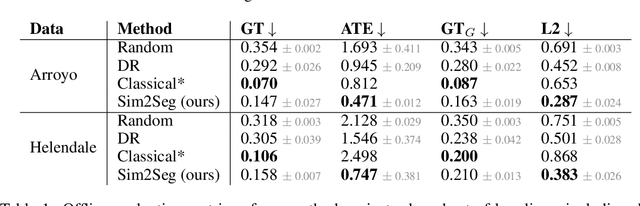

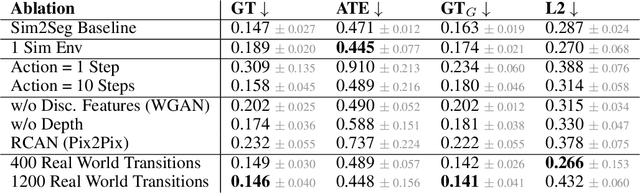
Autonomous driving is complex, requiring sophisticated 3D scene understanding, localization, mapping, and control. Rather than explicitly modelling and fusing each of these components, we instead consider an end-to-end approach via reinforcement learning (RL). However, collecting exploration driving data in the real world is impractical and dangerous. While training in simulation and deploying visual sim-to-real techniques has worked well for robot manipulation, deploying beyond controlled workspace viewpoints remains a challenge. In this paper, we address this challenge by presenting Sim2Seg, a re-imagining of RCAN that crosses the visual reality gap for off-road autonomous driving, without using any real-world data. This is done by learning to translate randomized simulation images into simulated segmentation and depth maps, subsequently enabling real-world images to also be translated. This allows us to train an end-to-end RL policy in simulation, and directly deploy in the real-world. Our approach, which can be trained in 48 hours on 1 GPU, can perform equally as well as a classical perception and control stack that took thousands of engineering hours over several months to build. We hope this work motivates future end-to-end autonomous driving research.