 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Learning as an Empirical Science: Best Practices for Policy Evaluation
Sep 14, 2024
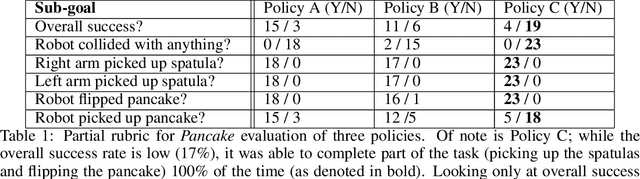

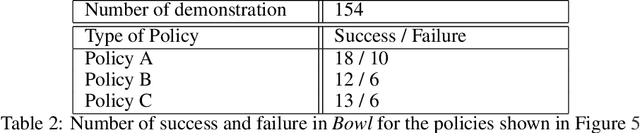
The robot learning community has made great strides in recent years, proposing new architectures and showcasing impressive new capabilities; however, the dominant metric used in the literature, especially for physical experiments, is "success rate", i.e. the percentage of runs that were successful. Furthermore, it is common for papers to report this number with little to no information regarding the number of runs, the initial conditions, and the success criteria, little to no narrative description of the behaviors and failures observed, and little to no statistical analysis of the findings. In this paper we argue that to move the field forward, researchers should provide a nuanced evaluation of their methods, especially when evaluating and comparing learned policies on physical robots. To do so, we propose best practices for future evaluations: explicitly reporting the experimental conditions, evaluating several metrics designed to complement success rate, conducting statistical analysis, and adding a qualitative description of failures modes. We illustrate these through an evaluation on physical robots of several learned policies for manipulation tasks.