 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
Understanding Complexity in VideoQA via Visual Program Generation
May 19, 2025We propose a data-driven approach to analyzing query complexity in Video Question Answering (VideoQA). Previous efforts in benchmark design have relied on human expertise to design challenging questions, yet we experimentally show that humans struggle to predict which questions are difficult for machine learning models. Our automatic approach leverages recent advances in code generation for visual question answering, using the complexity of generated code as a proxy for question difficulty. We demonstrate that this measure correlates significantly better with model performance than human estimates. To operationalize this insight, we propose an algorithm for estimating question complexity from code. It identifies fine-grained primitives that correlate with the hardest questions for any given set of models, making it easy to scale to new approaches in the future. Finally, to further illustrate the utility of our method, we extend it to automatically generate complex questions, constructing a new benchmark that is 1.9 times harder than the popular NExT-QA.
FastMap: Revisiting Dense and Scalable Structure from Motion
May 07, 2025We propose FastMap, a new global structure from motion method focused on speed and simplicity. Previous methods like COLMAP and GLOMAP are able to estimate high-precision camera poses, but suffer from poor scalability when the number of matched keypoint pairs becomes large. We identify two key factors leading to this problem: poor parallelization and computationally expensive optimization steps. To overcome these issues, we design an SfM framework that relies entirely on GPU-friendly operations, making it easily parallelizable. Moreover, each optimization step runs in time linear to the number of image pairs, independent of keypoint pairs or 3D points. Through extensive experiments, we show that FastMap is one to two orders of magnitude faster than COLMAP and GLOMAP on large-scale scenes with comparable pose accuracy.
Should VLMs be Pre-trained with Image Data?
Mar 10, 2025Pre-trained LLMs that are further trained with image data perform well on vision-language tasks. While adding images during a second training phase effectively unlocks this capability, it is unclear how much of a gain or loss this two-step pipeline gives over VLMs which integrate images earlier into the training process. To investigate this, we train models spanning various datasets, scales, image-text ratios, and amount of pre-training done before introducing vision tokens. We then fine-tune these models and evaluate their downstream performance on a suite of vision-language and text-only tasks. We find that pre-training with a mixture of image and text data allows models to perform better on vision-language tasks while maintaining strong performance on text-only evaluations. On an average of 6 diverse tasks, we find that for a 1B model, introducing visual tokens 80% of the way through pre-training results in a 2% average improvement over introducing visual tokens to a fully pre-trained model.
Incorporating dense metric depth into neural 3D representations for view synthesis and relighting
Sep 04, 2024



Synthesizing accurate geometry and photo-realistic appearance of small scenes is an active area of research with compelling use cases in gaming, virtual reality, robotic-manipulation, autonomous driving, convenient product capture, and consumer-level photography. When applying scene geometry and appearance estimation techniques to robotics, we found that the narrow cone of possible viewpoints due to the limited range of robot motion and scene clutter caused current estimation techniques to produce poor quality estimates or even fail. On the other hand, in robotic applications, dense metric depth can often be measured directly using stereo and illumination can be controlled. Depth can provide a good initial estimate of the object geometry to improve reconstruction, while multi-illumination images can facilitate relighting. In this work we demonstrate a method to incorporate dense metric depth into the training of neural 3D representations and address an artifact observed while jointly refining geometry and appearance by disambiguating between texture and geometry edges. We also discuss a multi-flash stereo camera system developed to capture the necessary data for our pipeline and show results on relighting and view synthesis with a few training views.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry
Jun 03, 2024



Monocular visual odometry is a key technology in a wide variety of autonomous systems. Relative to traditional feature-based methods, that suffer from failures due to poor lighting, insufficient texture, large motions, etc., recent learning-based SLAM methods exploit iterative dense bundle adjustment to address such failure cases and achieve robust accurate localization in a wide variety of real environments, without depending on domain-specific training data. However, despite its potential, learning-based SLAM still struggles with scenarios involving large motion and object dynamics. In this paper, we diagnose key weaknesses in a popular learning-based SLAM model (DROID-SLAM) by analyzing major failure cases on outdoor benchmarks and exposing various shortcomings of its optimization process. We then propose the use of self-supervised priors leveraging a frozen large-scale pre-trained monocular depth estimation to initialize the dense bundle adjustment process, leading to robust visual odometry without the need to fine-tune the SLAM backbone. Despite its simplicity, our proposed method demonstrates significant improvements on KITTI odometry, as well as the challenging DDAD benchmark. Code and pre-trained models will be released upon publication.
Linearizing Large Language Models
May 10, 2024



Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
Transcrib3D: 3D Referring Expression Resolution through Large Language Models
Apr 30, 2024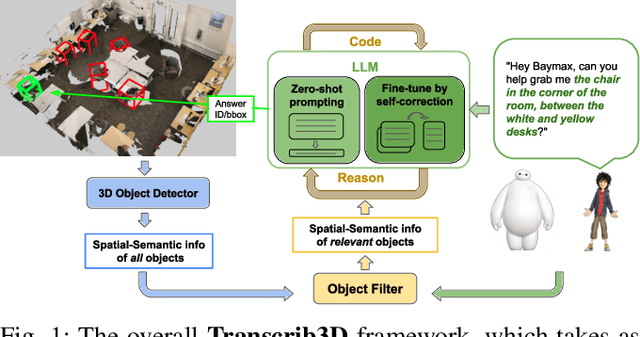
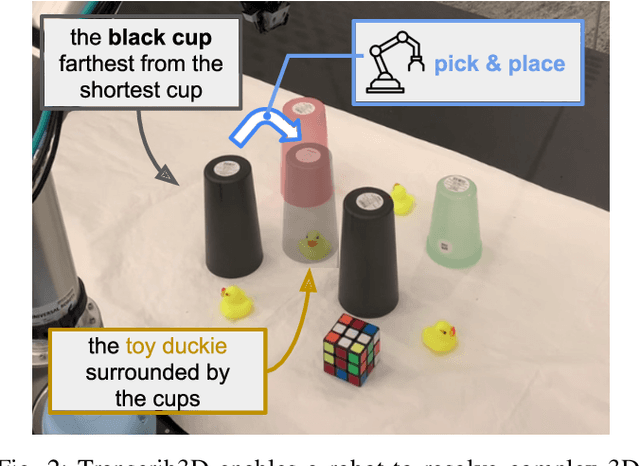
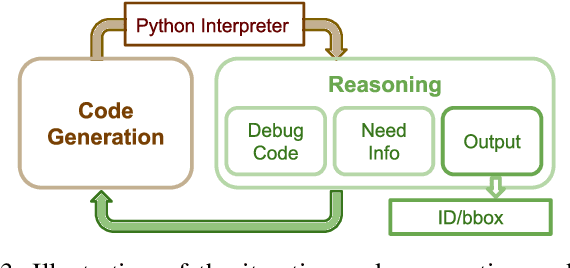

If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging -- it requires the ability to both parse the 3D structure of the scene and correctly ground free-form language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Project site is at https://ripl.github.io/Transcrib3D.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024



Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.