 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-CLING: Prior-Preserving Depth-Conditioned Fine-Tuning for Navigation Foundation Models
May 19, 2026Navigation Foundation Models (NFMs) trained on large cross-embodied datasets have demonstrated powerful generalizability in various scenarios. Adopting in-domain fine-tuning for an NFM efficiently calibrates the visuomotor policy, promising further improvement even in a novel scenario. However, the fine-tuned models still suffer from poor obstacle avoidance or fail to properly reach the provided goals. Furthermore, model updates using a small subset of data typically erode the pre-trained prior, compromising the pre-training generalization. Consequently, fine-tuning deteriorates the capability of the model for robust and accurate navigation. In this work, we present a novel fine-tuning method that leverages large-scale pre-training while efficiently learning in novel setups, such as environments or camera configurations. In particular, inspired by ControlNet, we fine-tune an NFM by attaching a trainable copy of the pre-trained backbone using zero-initialized residual pathways, thereby learning geometric cues. This design enables the model to efficiently acquire in-domain geometry while preserving pre-trained knowledge across various behaviors. Despite its simplicity, our comprehensive evaluation of real-world navigation suggests that our proposal effectively enables robust long-horizon navigation with minimal collisions and human intervention. Additionally, our offline analysis shows that the proposed method maintains or further improves action prediction capabilities beyond the fine-tuned dataset, providing a key insight into continual learning for general navigation. The project page: https://toyotafrc.github.io/DCLING-Proj/
Where Do We Look When We Teach? Analyzing Human Gaze Behavior Across Demonstration Devices in Robot Imitation Learning
Jun 06, 2025Imitation learning for acquiring generalizable policies often requires a large volume of demonstration data, making the process significantly costly. One promising strategy to address this challenge is to leverage the cognitive and decision-making skills of human demonstrators with strong generalization capability, particularly by extracting task-relevant cues from their gaze behavior. However, imitation learning typically involves humans collecting data using demonstration devices that emulate a robot's embodiment and visual condition. This raises the question of how such devices influence gaze behavior. We propose an experimental framework that systematically analyzes demonstrators' gaze behavior across a spectrum of demonstration devices. Our experimental results indicate that devices emulating (1) a robot's embodiment or (2) visual condition impair demonstrators' capability to extract task-relevant cues via gaze behavior, with the extent of impairment depending on the degree of emulation. Additionally, gaze data collected using devices that capture natural human behavior improves the policy's task success rate from 18.8% to 68.8% under environmental shifts.
Robust Imitation Learning for Mobile Manipulator Focusing on Task-Related Viewpoints and Regions
Oct 02, 2024



We study how to generalize the visuomotor policy of a mobile manipulator from the perspective of visual observations. The mobile manipulator is prone to occlusion owing to its own body when only a single viewpoint is employed and a significant domain shift when deployed in diverse situations. However, to the best of the authors' knowledge, no study has been able to solve occlusion and domain shift simultaneously and propose a robust policy. In this paper, we propose a robust imitation learning method for mobile manipulators that focuses on task-related viewpoints and their spatial regions when observing multiple viewpoints. The multiple viewpoint policy includes attention mechanism, which is learned with an augmented dataset, and brings optimal viewpoints and robust visual embedding against occlusion and domain shift. Comparison of our results for different tasks and environments with those of previous studies revealed that our proposed method improves the success rate by up to 29.3 points. We also conduct ablation studies using our proposed method. Learning task-related viewpoints from the multiple viewpoints dataset increases robustness to occlusion than using a uniquely defined viewpoint. Focusing on task-related regions contributes to up to a 33.3-point improvement in the success rate against domain shift.
Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry
Jun 03, 2024



Monocular visual odometry is a key technology in a wide variety of autonomous systems. Relative to traditional feature-based methods, that suffer from failures due to poor lighting, insufficient texture, large motions, etc., recent learning-based SLAM methods exploit iterative dense bundle adjustment to address such failure cases and achieve robust accurate localization in a wide variety of real environments, without depending on domain-specific training data. However, despite its potential, learning-based SLAM still struggles with scenarios involving large motion and object dynamics. In this paper, we diagnose key weaknesses in a popular learning-based SLAM model (DROID-SLAM) by analyzing major failure cases on outdoor benchmarks and exposing various shortcomings of its optimization process. We then propose the use of self-supervised priors leveraging a frozen large-scale pre-trained monocular depth estimation to initialize the dense bundle adjustment process, leading to robust visual odometry without the need to fine-tune the SLAM backbone. Despite its simplicity, our proposed method demonstrates significant improvements on KITTI odometry, as well as the challenging DDAD benchmark. Code and pre-trained models will be released upon publication.
Robust Self-Supervised Extrinsic Self-Calibration
Aug 07, 2023



Autonomous vehicles and robots need to operate over a wide variety of scenarios in order to complete tasks efficiently and safely. Multi-camera self-supervised monocular depth estimation from videos is a promising way to reason about the environment, as it generates metrically scaled geometric predictions from visual data without requiring additional sensors. However, most works assume well-calibrated extrinsics to fully leverage this multi-camera setup, even though accurate and efficient calibration is still a challenging problem. In this work, we introduce a novel method for extrinsic calibration that builds upon the principles of self-supervised monocular depth and ego-motion learning. Our proposed curriculum learning strategy uses monocular depth and pose estimators with velocity supervision to estimate extrinsics, and then jointly learns extrinsic calibration along with depth and pose for a set of overlapping cameras rigidly attached to a moving vehicle. Experiments on a benchmark multi-camera dataset (DDAD) demonstrate that our method enables self-calibration in various scenes robustly and efficiently compared to a traditional vision-based pose estimation pipeline. Furthermore, we demonstrate the benefits of extrinsics self-calibration as a way to improve depth prediction via joint optimization.
* Project page: https://sites.google.com/view/tri-sesc
Third-party Evaluation of Robotic Hand Designs Using a Mechanical Glove
Sep 22, 2021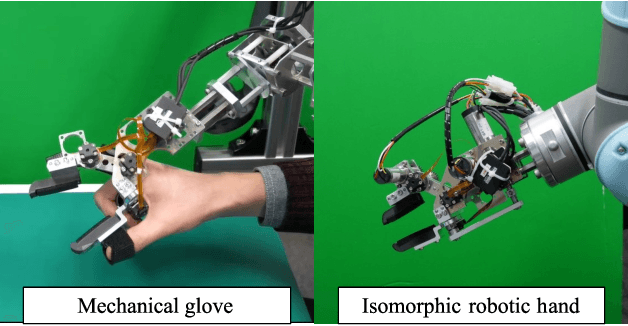



A robotic hand design suitable for dexterity should be examined using functional tests. To achieve this, we designed a mechanical glove, which is a rigid wearable glove that enables us to develop the corresponding isomorphic robotic hand and evaluate its hardware properties. Subsequently, the effectiveness of multiple degrees-of-freedom (DOFs) was evaluated by human participants. Several fine motor skills were evaluated using the mechanical glove under two conditions: one- and three-DOF conditions. To the best of our knowledge, this is the first extensive evaluation method for robotic hand designs suitable for dexterity. (This paper was peer-reviewed and is the full translation from the Journal of the Robotics Society of Japan, Vol.39, No.6, pp.557-560, 2021.)
* 5 pages, 7 figures