 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Inter-Object Relationships via Group Homomorphism
Apr 22, 2026While current deep learning models achieve high performance by learning statistical correlations from vast datasets,which stands in stark contrast to human learning. They lack the flexibility of humans-particularly preverbal infants-to autonomously acquire the underlying structure of the world from limited experience and adapt to novel situations. In this study, we propose an unsupervised representation learning method based on a hierarchical relationship in group operations, rather than statistical independence, aiming to build a computational model of the cognitive development of infants. The proposed model features an integrated architecture that simultaneously performs object segmentation and the extraction of motion laws from dynamic image sequences. By introducing the Homomorphism from algebra as a structural constraint within a neural network, the model structurally separates pixel-level changes into meaningful, decomposed transformation components, such as translation and deformation. Using interaction scenes (chasing and evading tasks) based on developmental science findings, we experimentally demonstrate that the model can segment multiple objects into individual slots without any ground-truth labels. Furthermore, we confirmed that relative movements between objects, such as approaching or receding, are accurately mapped and structured into a one-dimensional additive latent space. These results suggest that by introducing algebraic geometric constraints rather than relying solely on statistical correlation learning, physically interpretable "disentangled representations" can be acquired. This study contributes to the understanding of the process by which infants internalize environmental laws as structures and provides a new perspective for constructing artificial systems with developmental intelligence.
Exploration-assisted Bottleneck Transition Toward Robust and Data-efficient Deformable Object Manipulation
Mar 14, 2026Imitation learning has demonstrated impressive results in robotic manipulation but fails under out-of-distribution (OOD) states. This limitation is particularly critical in Deformable Object Manipulation (DOM), where the near-infinite possible configurations render comprehensive data collection infeasible. Although several methods address OOD states, they typically require exhaustive data or highly precise perception. Such requirements are often impractical for DOM owing to its inherent complexities, including self-occlusion. To address the OOD problem in DOM, we propose a novel framework, Exploration-assisted Bottleneck Transition for Deformable Object Manipulation (ExBot), which addresses the OOD challenge through two key advantages. First, we introduce bottleneck states, standardized configurations that serve as starting points for task execution. This enables the reconceptualization of OOD challenges as the problem of transitioning diverse initial states to these bottleneck states, significantly reducing demonstration requirements. Second, to account for imperfect perception, we partition the OOD state space based on recognizability and employ dual action primitives. This approach enables ExBot to manipulate even unrecognizable states without requiring accurate perception. By concentrating demonstrations around bottleneck states and leveraging exploration to alter perceptual conditions, ExBot achieves both data efficiency and robustness to severe OOD scenarios. Real-world experiments on rope and cloth manipulation demonstrate successful task completion from diverse OOD states, including severe self-occlusions.
Topology Matters: A Cautionary Case Study of Graph SSL on Neuro-Inspired Benchmarks
Feb 03, 2026Understanding how local interactions give rise to global brain organization requires models that can represent information across multiple scales. We introduce a hierarchical self-supervised learning (SSL) framework that jointly learns node-, edge-, and graph-level embeddings, inspired by multimodal neuroimaging. We construct a controllable synthetic benchmark mimicking the topological properties of connectomes. Our four-stage evaluation protocol reveals a critical failure: the invariance-based SSL model is fundamentally misaligned with the benchmark's topological properties and is catastrophically outperformed by classical, topology-aware heuristics. Ablations confirm an objective mismatch: SSL objectives designed to be invariant to topological perturbations learn to ignore the very community structure that classical methods exploit. Our results expose a fundamental pitfall in applying generic graph SSL to connectome-like data. We present this framework as a cautionary case study, highlighting the need for new, topology-aware SSL objectives for neuro-AI research that explicitly reward the preservation of structure (e.g., modularity or motifs).
Why Consciousness Should Explain Physical Phenomena: Toward a Testable Theory
Nov 19, 2025The reductionist approach commonly employed in scientific methods presupposes that both macro and micro phenomena can be explained by micro-level laws alone. This assumption implies intra-level causal closure, rendering all macro phenomena epiphenomenal. However, the integrative nature of consciousness suggests that it is a macro phenomenon. To ensure scientific testability and reject epiphenomenalism, the reductionist assumption of intra-level causal closure must be rejected. This implies that even neural-level behavior cannot be explained by observable neural-level laws alone. Therefore, a new methodology is necessary to acknowledge the causal efficacy of macro-level phenomena. We model the brain as operating under dual laws at different levels. This model includes hypothetical macro-level psychological laws that are not determined solely by micro-level neural laws, as well as the causal effects from macro to micro levels. In this study, we propose a constructive approach that explains both mental and physical phenomena through the interaction between these two sets of laws.
Memory Determines Learning Direction: A Theory of Gradient-Based Optimization in State Space Models
Oct 01, 2025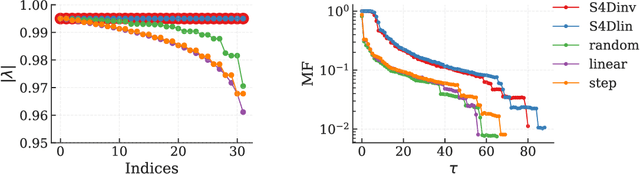
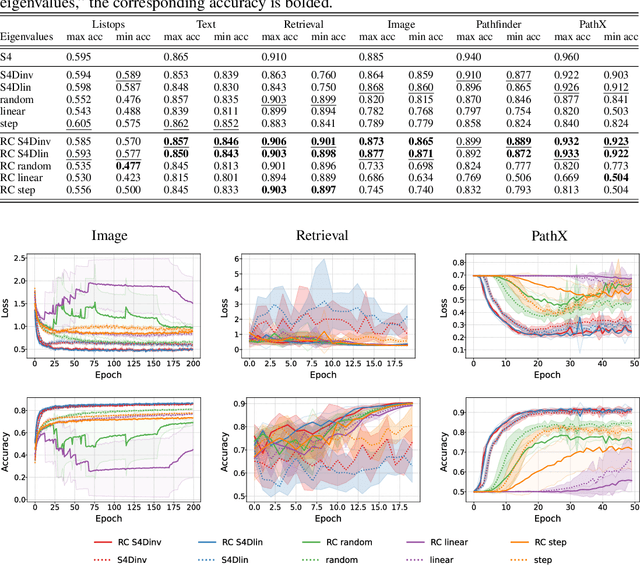
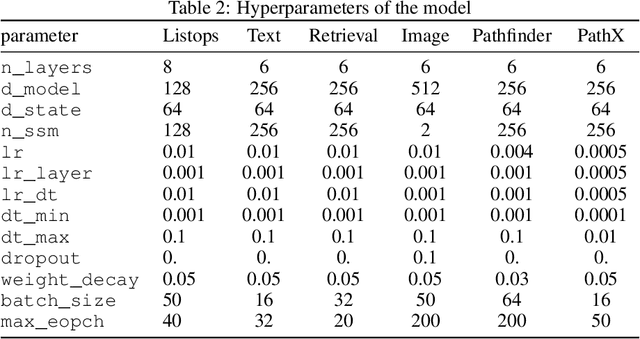
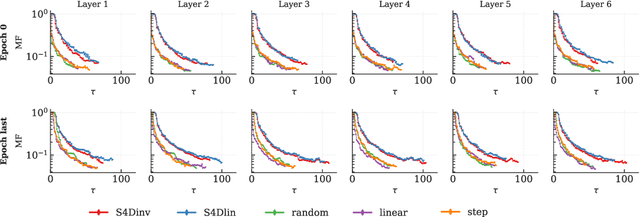
State space models (SSMs) have gained attention by showing potential to outperform Transformers. However, previous studies have not sufficiently addressed the mechanisms underlying their high performance owing to a lack of theoretical explanation of SSMs' learning dynamics. In this study, we provide such an explanation and propose an improved training strategy. The memory capacity of SSMs can be evaluated by examining how input time series are stored in their current state. Such an examination reveals a tradeoff between memory accuracy and length, as well as the theoretical equivalence between the structured state space sequence model (S4) and a simplified S4 with diagonal recurrent weights. This theoretical foundation allows us to elucidate the learning dynamics, proving the importance of initial parameters. Our analytical results suggest that successful learning requires the initial memory structure to be the longest possible even if memory accuracy may deteriorate or the gradient lose the teacher information. Experiments on tasks requiring long memory confirmed that extending memory is difficult, emphasizing the importance of initialization. Furthermore, we found that fixing recurrent weights can be more advantageous than adapting them because it achieves comparable or even higher performance with faster convergence. Our results provide a new theoretical foundation for SSMs and potentially offer a novel optimization strategy.
Synaptic bundle theory for spike-driven sensor-motor system: More than eight independent synaptic bundles collapse reward-STDP learning
Aug 20, 2025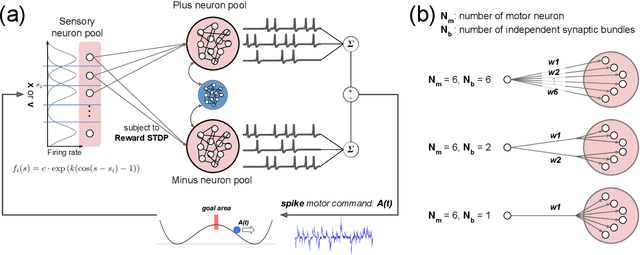
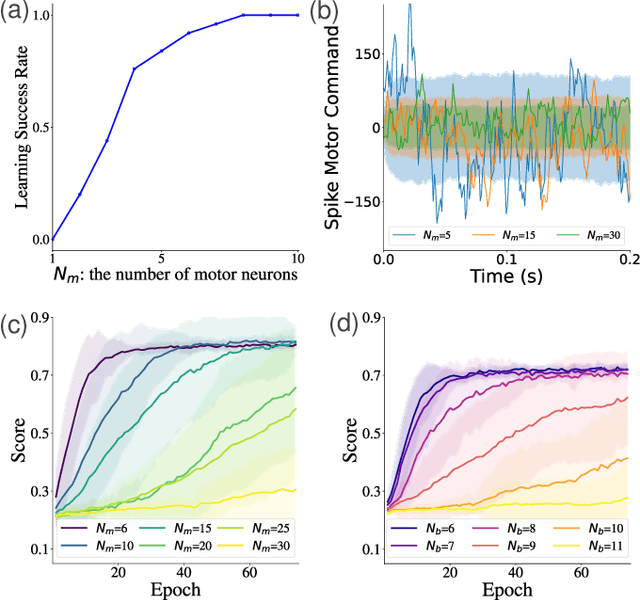
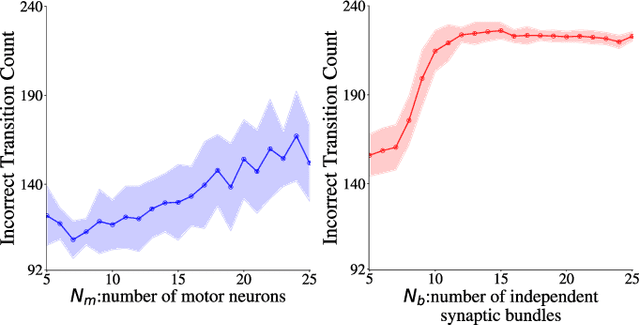
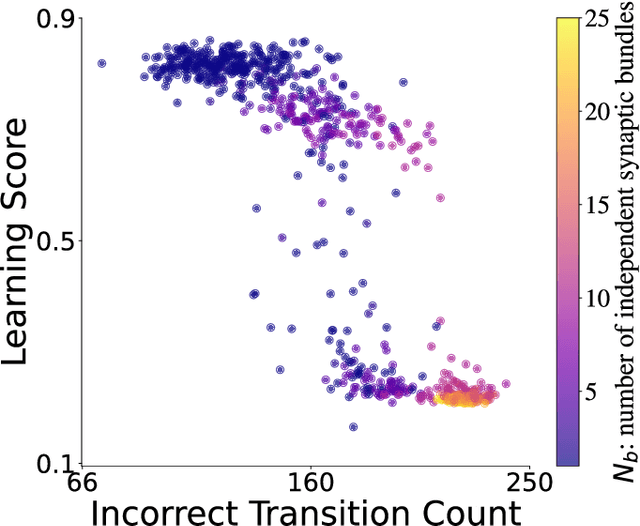
Neuronal spikes directly drive muscles and endow animals with agile movements, but applying the spike-based control signals to actuators in artificial sensor-motor systems inevitably causes a collapse of learning. We developed a system that can vary \emph{the number of independent synaptic bundles} in sensor-to-motor connections. This paper demonstrates the following four findings: (i) Learning collapses once the number of motor neurons or the number of independent synaptic bundles exceeds a critical limit. (ii) The probability of learning failure is increased by a smaller number of motor neurons, while (iii) if learning succeeds, a smaller number of motor neurons leads to faster learning. (iv) The number of weight updates that move in the opposite direction of the optimal weight can quantitatively explain these results. The functions of spikes remain largely unknown. Identifying the parameter range in which learning systems using spikes can be constructed will make it possible to study the functions of spikes that were previously inaccessible due to the difficulty of learning.
Feature-Based Lie Group Transformer for Real-World Applications
Jun 06, 2025



The main goal of representation learning is to acquire meaningful representations from real-world sensory inputs without supervision. Representation learning explains some aspects of human development. Various neural network (NN) models have been proposed that acquire empirically good representations. However, the formulation of a good representation has not been established. We recently proposed a method for categorizing changes between a pair of sensory inputs. A unique feature of this approach is that transformations between two sensory inputs are learned to satisfy algebraic structural constraints. Conventional representation learning often assumes that disentangled independent feature axes is a good representation; however, we found that such a representation cannot account for conditional independence. To overcome this problem, we proposed a new method using group decomposition in Galois algebra theory. Although this method is promising for defining a more general representation, it assumes pixel-to-pixel translation without feature extraction, and can only process low-resolution images with no background, which prevents real-world application. In this study, we provide a simple method to apply our group decomposition theory to a more realistic scenario by combining feature extraction and object segmentation. We replace pixel translation with feature translation and formulate object segmentation as grouping features under the same transformation. We validated the proposed method on a practical dataset containing both real-world object and background. We believe that our model will lead to a better understanding of human development of object recognition in the real world.
Emergence of Fixational and Saccadic Movements in a Multi-Level Recurrent Attention Model for Vision
May 19, 2025Inspired by foveal vision, hard attention models promise interpretability and parameter economy. However, existing models like the Recurrent Model of Visual Attention (RAM) and Deep Recurrent Attention Model (DRAM) failed to model the hierarchy of human vision system, that compromise on the visual exploration dynamics. As a result, they tend to produce attention that are either overly fixational or excessively saccadic, diverging from human eye movement behavior. In this paper, we propose a Multi-Level Recurrent Attention Model (MRAM), a novel hard attention framework that explicitly models the neural hierarchy of human visual processing. By decoupling the function of glimpse location generation and task execution in two recurrent layers, MRAM emergent a balanced behavior between fixation and saccadic movement. Our results show that MRAM not only achieves more human-like attention dynamics, but also consistently outperforms CNN, RAM and DRAM baselines on standard image classification benchmarks.
Attractor-merging Crises and Intermittency in Reservoir Computing
Apr 17, 2025Reservoir computing can embed attractors into random neural networks (RNNs), generating a ``mirror'' of a target attractor because of its inherent symmetrical constraints. In these RNNs, we report that an attractor-merging crisis accompanied by intermittency emerges simply by adjusting the global parameter. We further reveal its underlying mechanism through a detailed analysis of the phase-space structure and demonstrate that this bifurcation scenario is intrinsic to a general class of RNNs, independent of training data.
Emergence of Goal-Directed Behaviors via Active Inference with Self-Prior
Apr 15, 2025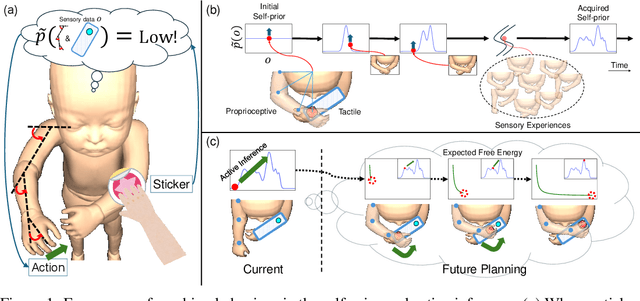



Infants often exhibit goal-directed behaviors, such as reaching for a sensory stimulus, even when no external reward criterion is provided. These intrinsically motivated behaviors facilitate spontaneous exploration and learning of the body and environment during early developmental stages. Although computational modeling can offer insight into the mechanisms underlying such behaviors, many existing studies on intrinsic motivation focus primarily on how exploration contributes to acquiring external rewards. In this paper, we propose a novel density model for an agent's own multimodal sensory experiences, called the "self-prior," and investigate whether it can autonomously induce goal-directed behavior. Integrated within an active inference framework based on the free energy principle, the self-prior generates behavioral references purely from an intrinsic process that minimizes mismatches between average past sensory experiences and current observations. This mechanism is also analogous to the acquisition and utilization of a body schema through continuous interaction with the environment. We examine this approach in a simulated environment and confirm that the agent spontaneously reaches toward a tactile stimulus. Our study implements intrinsically motivated behavior shaped by the agent's own sensory experiences, demonstrating the spontaneous emergence of intentional behavior during early development.