 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reusability of Learned Skills for Robot Manipulation via Gaze and Bottleneck
Feb 26, 2025Autonomous agents capable of diverse object manipulations should be able to acquire a wide range of manipulation skills with high reusability. Although advances in deep learning have made it increasingly feasible to replicate the dexterity of human teleoperation in robots, generalizing these acquired skills to previously unseen scenarios remains a significant challenge. In this study, we propose a novel algorithm, Gaze-based Bottleneck-aware Robot Manipulation (GazeBot), which enables high reusability of the learned motions even when the object positions and end-effector poses differ from those in the provided demonstrations. By leveraging gaze information and motion bottlenecks, both crucial features for object manipulation, GazeBot achieves high generalization performance compared with state-of-the-art imitation learning methods, without sacrificing its dexterity and reactivity. Furthermore, the training process of GazeBot is entirely data-driven once a demonstration dataset with gaze data is provided. Videos and code are available at https://crumbyrobotics.github.io/gazebot.
Reinforced Imitation Learning by Free Energy Principle
Jul 25, 2021



Reinforcement Learning (RL) requires a large amount of exploration especially in sparse-reward settings. Imitation Learning (IL) can learn from expert demonstrations without exploration, but it never exceeds the expert's performance and is also vulnerable to distributional shift between demonstration and execution. In this paper, we radically unify RL and IL based on Free Energy Principle (FEP). FEP is a unified Bayesian theory of the brain that explains perception, action and model learning by a common fundamental principle. We present a theoretical extension of FEP and derive an algorithm in which an agent learns the world model that internalizes expert demonstrations and at the same time uses the model to infer the current and future states and actions that maximize rewards. The algorithm thus reduces exploration costs by partially imitating experts as well as maximizing its return in a seamless way, resulting in a higher performance than the suboptimal expert. Our experimental results show that this approach is promising in visual control tasks especially in sparse-reward environments.
Identifying Critical States by the Action-Based Variance of Expected Return
Aug 26, 2020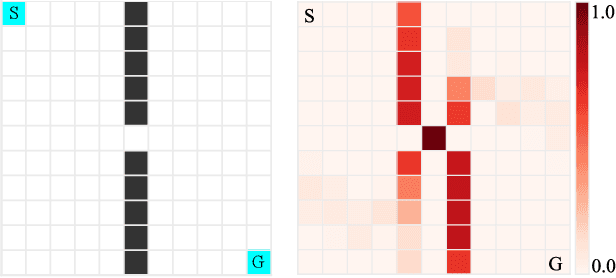
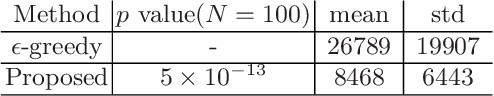
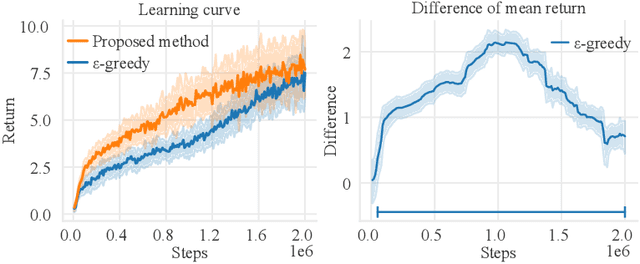
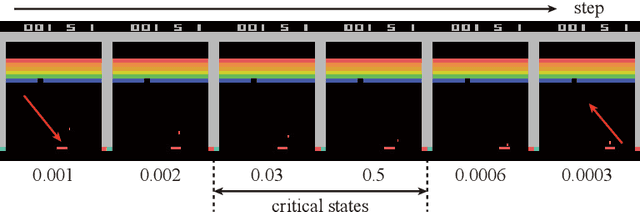
The balance of exploration and exploitation plays a crucial role in accelerating reinforcement learning (RL). To deploy an RL agent in human society, its explainability is also essential. However, basic RL approaches have difficulties in deciding when to choose exploitation as well as in extracting useful points for a brief explanation of its operation. One reason for the difficulties is that these approaches treat all states the same way. Here, we show that identifying critical states and treating them specially is commonly beneficial to both problems. These critical states are the states at which the action selection changes the potential of success and failure substantially. We propose to identify the critical states using the variance in the Q-function for the actions and to perform exploitation with high probability on the identified states. These simple methods accelerate RL in a grid world with cliffs and two baseline tasks of deep RL. Our results also demonstrate that the identified critical states are intuitively interpretable regarding the crucial nature of the action selection. Furthermore, our analysis of the relationship between the timing of the identification of especially critical states and the rapid progress of learning suggests there are a few especially critical states that have important information for accelerating RL rapidly.
Switching Isotropic and Directional Exploration with Parameter Space Noise in Deep Reinforcement Learning
Sep 27, 2018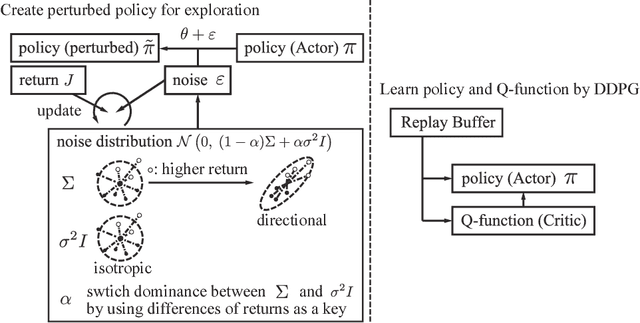
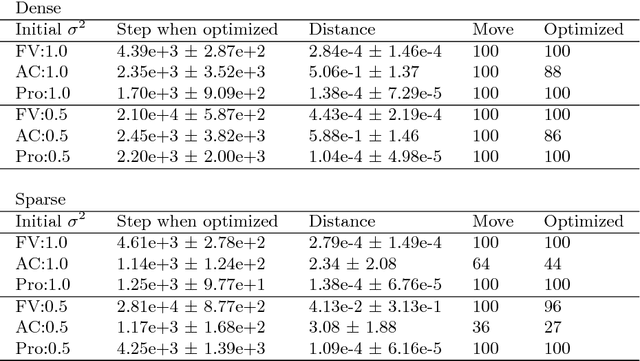
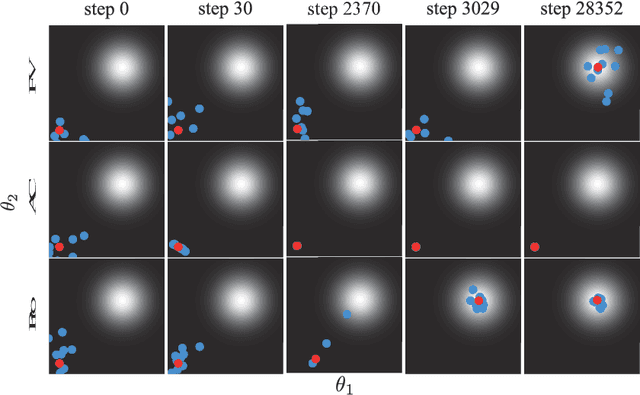
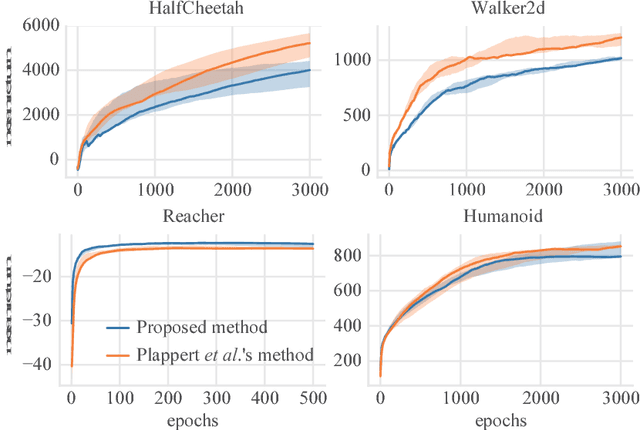
This paper proposes an exploration method for deep reinforcement learning based on parameter space noise. Recent studies have experimentally shown that parameter space noise results in better exploration than the commonly used action space noise. Previous methods devised a way to update the diagonal covariance matrix of a noise distribution and did not consider the direction of the noise vector and its correlation. In addition, fast updates of the noise distribution are required to facilitate policy learning. We propose a method that deforms the noise distribution according to the accumulated returns and the noises that have led to the returns. Moreover, this method switches isotropic exploration and directional exploration in parameter space with regard to obtained rewards. We validate our exploration strategy in the OpenAI Gym continuous environments and modified environments with sparse rewards. The proposed method achieves results that are competitive with a previous method at baseline tasks. Moreover, our approach exhibits better performance in sparse reward environments by exploration with the switching strategy.