 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomeostatic Coupling for Prosocial Behavior
Jun 15, 2025



When regarding the suffering of others, we often experience personal distress and feel compelled to help\footnote{Preprint. Under review.}. Inspired by living systems, we investigate the emergence of prosocial behavior among autonomous agents that are motivated by homeostatic self-regulation. We perform multi-agent reinforcement learning, treating each agent as a vulnerable homeostat charged with maintaining its own well-being. We introduce an empathy-like mechanism to share homeostatic states between agents: an agent can either \emph{observe} their partner's internal state ({\bf cognitive empathy}) or the agent's internal state can be \emph{directly coupled} to that of their partner ({\bf affective empathy}). In three simple multi-agent environments, we show that prosocial behavior arises only under homeostatic coupling - when the distress of a partner can affect one's own well-being. Additionally, we show that empathy can be learned: agents can ``decode" their partner's external emotive states to infer the partner's internal homeostatic states. Assuming some level of physiological similarity, agents reference their own emotion-generation functions to invert the mapping from outward display to internal state. Overall, we demonstrate the emergence of prosocial behavior when homeostatic agents learn to ``read" the emotions of others and then to empathize, or feel as they feel.
Reward-Independent Messaging for Decentralized Multi-Agent Reinforcement Learning
May 28, 2025In multi-agent reinforcement learning (MARL), effective communication improves agent performance, particularly under partial observability. We propose MARL-CPC, a framework that enables communication among fully decentralized, independent agents without parameter sharing. MARL-CPC incorporates a message learning model based on collective predictive coding (CPC) from emergent communication research. Unlike conventional methods that treat messages as part of the action space and assume cooperation, MARL-CPC links messages to state inference, supporting communication in non-cooperative, reward-independent settings. We introduce two algorithms -Bandit-CPC and IPPO-CPC- and evaluate them in non-cooperative MARL tasks. Benchmarks show that both outperform standard message-as-action approaches, establishing effective communication even when messages offer no direct benefit to the sender. These results highlight MARL-CPC's potential for enabling coordination in complex, decentralized environments.
Emergence of Goal-Directed Behaviors via Active Inference with Self-Prior
Apr 15, 2025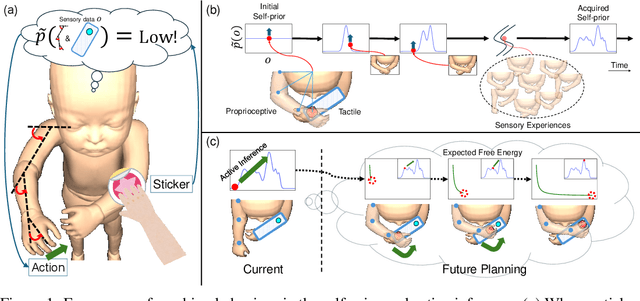



Infants often exhibit goal-directed behaviors, such as reaching for a sensory stimulus, even when no external reward criterion is provided. These intrinsically motivated behaviors facilitate spontaneous exploration and learning of the body and environment during early developmental stages. Although computational modeling can offer insight into the mechanisms underlying such behaviors, many existing studies on intrinsic motivation focus primarily on how exploration contributes to acquiring external rewards. In this paper, we propose a novel density model for an agent's own multimodal sensory experiences, called the "self-prior," and investigate whether it can autonomously induce goal-directed behavior. Integrated within an active inference framework based on the free energy principle, the self-prior generates behavioral references purely from an intrinsic process that minimizes mismatches between average past sensory experiences and current observations. This mechanism is also analogous to the acquisition and utilization of a body schema through continuous interaction with the environment. We examine this approach in a simulated environment and confirm that the agent spontaneously reaches toward a tactile stimulus. Our study implements intrinsically motivated behavior shaped by the agent's own sensory experiences, demonstrating the spontaneous emergence of intentional behavior during early development.
Emergence of Implicit World Models from Mortal Agents
Nov 19, 2024

We discuss the possibility of world models and active exploration as emergent properties of open-ended behavior optimization in autonomous agents. In discussing the source of the open-endedness of living things, we start from the perspective of biological systems as understood by the mechanistic approach of theoretical biology and artificial life. From this perspective, we discuss the potential of homeostasis in particular as an open-ended objective for autonomous agents and as a general, integrative extrinsic motivation. We then discuss the possibility of implicitly acquiring a world model and active exploration through the internal dynamics of a network, and a hypothetical architecture for this, by combining meta-reinforcement learning, which assumes domain adaptation as a system that achieves robust homeostasis.
On Reward Function for Survival
Jul 24, 2016
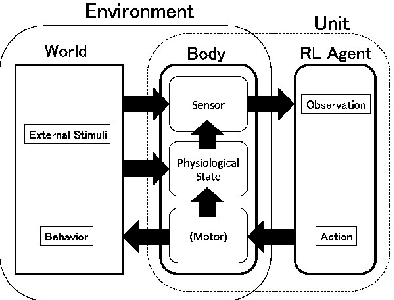

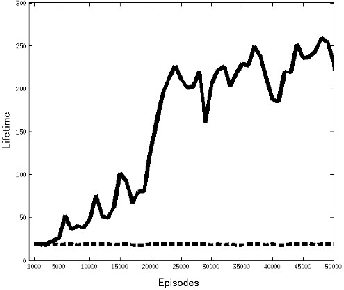
Obtaining a survival strategy (policy) is one of the fundamental problems of biological agents. In this paper, we generalize the formulation of previous research related to the survival of an agent and we formulate the survival problem as a maximization of the multi-step survival probability in future time steps. We introduce a method for converting the maximization of multi-step survival probability into a classical reinforcement learning problem. Using this conversion, the reward function (negative temporal cost function) is expressed as the log of the temporal survival probability. And we show that the objective function of the reinforcement learning in this sense is proportional to the variational lower bound of the original problem. Finally, We empirically demonstrate that the agent learns survival behavior by using the reward function introduced in this paper.
Q-Networks for Binary Vector Actions
Dec 04, 2015



In this paper reinforcement learning with binary vector actions was investigated. We suggest an effective architecture of the neural networks for approximating an action-value function with binary vector actions. The proposed architecture approximates the action-value function by a linear function with respect to the action vector, but is still non-linear with respect to the state input. We show that this approximation method enables the efficient calculation of greedy action selection and softmax action selection. Using this architecture, we suggest an online algorithm based on Q-learning. The empirical results in the grid world and the blocker task suggest that our approximation architecture would be effective for the RL problems with large discrete action sets.