 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Reward Function for Survival
Paper and Code
Jul 24, 2016
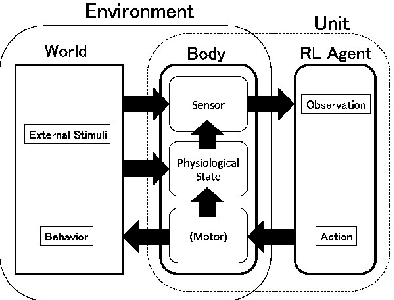

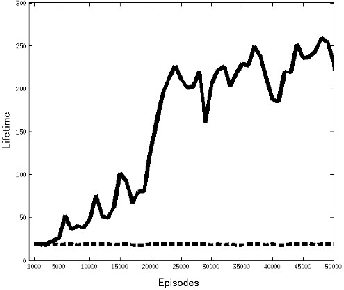
Obtaining a survival strategy (policy) is one of the fundamental problems of biological agents. In this paper, we generalize the formulation of previous research related to the survival of an agent and we formulate the survival problem as a maximization of the multi-step survival probability in future time steps. We introduce a method for converting the maximization of multi-step survival probability into a classical reinforcement learning problem. Using this conversion, the reward function (negative temporal cost function) is expressed as the log of the temporal survival probability. And we show that the objective function of the reinforcement learning in this sense is proportional to the variational lower bound of the original problem. Finally, We empirically demonstrate that the agent learns survival behavior by using the reward function introduced in this paper.