 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Apr 13, 2026Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
AdaptMI: Adaptive Skill-based In-context Math Instruction for Small Language Models
Apr 30, 2025In-context learning (ICL) allows a language model to improve its problem-solving capability when provided with suitable information in context. Since the choice of in-context information can be determined based on the problem itself, in-context learning is analogous to human learning from teachers in a classroom. Recent works (Didolkar et al., 2024a; 2024b) show that ICL performance can be improved by leveraging a frontier large language model's (LLM) ability to predict required skills to solve a problem, popularly referred to as an LLM's metacognition, and using the recommended skills to construct necessary in-context examples. While this skill-based strategy boosts ICL performance in larger models, its gains on small language models (SLMs) have been minimal, highlighting a performance gap in ICL capabilities. We investigate this gap and show that skill-based prompting can hurt SLM performance on easy questions by introducing unnecessary information, akin to cognitive overload. To address this, we introduce AdaptMI, an adaptive approach to selecting skill-based in-context Math Instructions for SLMs. Inspired by cognitive load theory from human pedagogy, our method only introduces skill-based examples when the model performs poorly. We further propose AdaptMI+, which adds examples targeted to the specific skills missing from the model's responses. On 5-shot evaluations across popular math benchmarks and five SLMs (1B--7B; Qwen, Llama), AdaptMI+ improves accuracy by up to 6% over naive skill-based strategies.
On the Power of Context-Enhanced Learning in LLMs
Mar 03, 2025We formalize a new concept for LLMs, context-enhanced learning. It involves standard gradient-based learning on text except that the context is enhanced with additional data on which no auto-regressive gradients are computed. This setting is a gradient-based analog of usual in-context learning (ICL) and appears in some recent works. Using a multi-step reasoning task, we prove in a simplified setting that context-enhanced learning can be exponentially more sample-efficient than standard learning when the model is capable of ICL. At a mechanistic level, we find that the benefit of context-enhancement arises from a more accurate gradient learning signal. We also experimentally demonstrate that it appears hard to detect or recover learning materials that were used in the context during training. This may have implications for data security as well as copyright.
Generalizing from SIMPLE to HARD Visual Reasoning: Can We Mitigate Modality Imbalance in VLMs?
Jan 05, 2025



While Vision Language Models (VLMs) are impressive in tasks such as visual question answering (VQA) and image captioning, their ability to apply multi-step reasoning to images has lagged, giving rise to perceptions of modality imbalance or brittleness. Towards systematic study of such issues, we introduce a synthetic framework for assessing the ability of VLMs to perform algorithmic visual reasoning (AVR), comprising three tasks: Table Readout, Grid Navigation, and Visual Analogy. Each has two levels of difficulty, SIMPLE and HARD, and even the SIMPLE versions are difficult for frontier VLMs. We seek strategies for training on the SIMPLE version of the tasks that improve performance on the corresponding HARD task, i.e., S2H generalization. This synthetic framework, where each task also has a text-only version, allows a quantification of the modality imbalance, and how it is impacted by training strategy. Ablations highlight the importance of explicit image-to-text conversion in promoting S2H generalization when using auto-regressive training. We also report results of mechanistic study of this phenomenon, including a measure of gradient alignment that seems to identify training strategies that promote better S2H generalization.
Progressive distillation induces an implicit curriculum
Oct 07, 2024Knowledge distillation leverages a teacher model to improve the training of a student model. A persistent challenge is that a better teacher does not always yield a better student, to which a common mitigation is to use additional supervision from several ``intermediate'' teachers. One empirically validated variant of this principle is progressive distillation, where the student learns from successive intermediate checkpoints of the teacher. Using sparse parity as a sandbox, we identify an implicit curriculum as one mechanism through which progressive distillation accelerates the student's learning. This curriculum is available only through the intermediate checkpoints but not the final converged one, and imparts both empirical acceleration and a provable sample complexity benefit to the student. We then extend our investigation to Transformers trained on probabilistic context-free grammars (PCFGs) and real-world pre-training datasets (Wikipedia and Books). Through probing the teacher model, we identify an analogous implicit curriculum where the model progressively learns features that capture longer context. Our theoretical and empirical findings on sparse parity, complemented by empirical observations on more complex tasks, highlight the benefit of progressive distillation via implicit curriculum across setups.
Representing Rule-based Chatbots with Transformers
Jul 15, 2024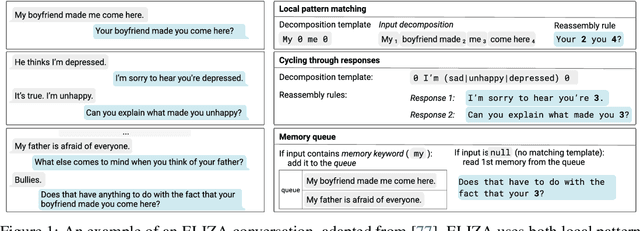


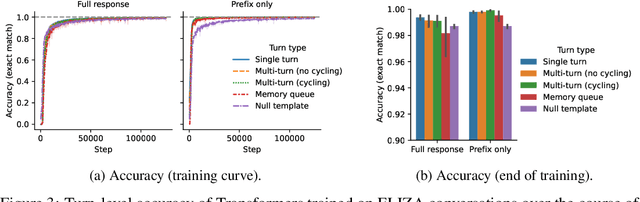
Transformer-based chatbots can conduct fluent, natural-sounding conversations, but we have limited understanding of the mechanisms underlying their behavior. Prior work has taken a bottom-up approach to understanding Transformers by constructing Transformers for various synthetic and formal language tasks, such as regular expressions and Dyck languages. However, it is not obvious how to extend this approach to understand more naturalistic conversational agents. In this work, we take a step in this direction by constructing a Transformer that implements the ELIZA program, a classic, rule-based chatbot. ELIZA illustrates some of the distinctive challenges of the conversational setting, including both local pattern matching and long-term dialog state tracking. We build on constructions from prior work -- in particular, for simulating finite-state automata -- showing how simpler constructions can be composed and extended to give rise to more sophisticated behavior. Next, we train Transformers on a dataset of synthetically generated ELIZA conversations and investigate the mechanisms the models learn. Our analysis illustrates the kinds of mechanisms these models tend to prefer -- for example, models favor an induction head mechanism over a more precise, position based copying mechanism; and using intermediate generations to simulate recurrent data structures, like ELIZA's memory mechanisms. Overall, by drawing an explicit connection between neural chatbots and interpretable, symbolic mechanisms, our results offer a new setting for mechanistic analysis of conversational agents.
Efficient Stagewise Pretraining via Progressive Subnetworks
Feb 08, 2024



Recent developments in large language models have sparked interest in efficient pretraining methods. A recent effective paradigm is to perform stage-wise training, where the size of the model is gradually increased over the course of training (e.g. gradual stacking (Reddi et al., 2023)). While the resource and wall-time savings are appealing, it has limitations, particularly the inability to evaluate the full model during earlier stages, and degradation in model quality due to smaller model capacity in the initial stages. In this work, we propose an alternative framework, progressive subnetwork training, that maintains the full model throughout training, but only trains subnetworks within the model in each step. We focus on a simple instantiation of this framework, Random Path Training (RaPTr) that only trains a sub-path of layers in each step, progressively increasing the path lengths in stages. RaPTr achieves better pre-training loss for BERT and UL2 language models while requiring 20-33% fewer FLOPs compared to standard training, and is competitive or better than other efficient training methods. Furthermore, RaPTr shows better downstream performance on UL2, improving QA tasks and SuperGLUE by 1-5% compared to standard training and stacking. Finally, we provide a theoretical basis for RaPTr to justify (a) the increasing complexity of subnetworks in stages, and (b) the stability in loss across stage transitions due to residual connections and layer norm.
Trainable Transformer in Transformer
Jul 03, 2023



Recent works attribute the capability of in-context learning (ICL) in large pre-trained language models to implicitly simulating and fine-tuning an internal model (e.g., linear or 2-layer MLP) during inference. However, such constructions require large memory overhead, which makes simulation of more sophisticated internal models intractable. In this work, we propose an efficient construction, Transformer in Transformer (in short, TinT), that allows a transformer to simulate and fine-tune complex models internally during inference (e.g., pre-trained language models). In particular, we introduce innovative approximation techniques that allow a TinT model with less than 2 billion parameters to simulate and fine-tune a 125 million parameter transformer model within a single forward pass. TinT accommodates many common transformer variants and its design ideas also improve the efficiency of past instantiations of simple models inside transformers. We conduct end-to-end experiments to validate the internal fine-tuning procedure of TinT on various language modeling and downstream tasks. For example, even with a limited one-step budget, we observe TinT for a OPT-125M model improves performance by 4-16% absolute on average compared to OPT-125M. These findings suggest that large pre-trained language models are capable of performing intricate subroutines. To facilitate further work, a modular and extensible codebase for TinT is included.
Do Transformers Parse while Predicting the Masked Word?
Mar 14, 2023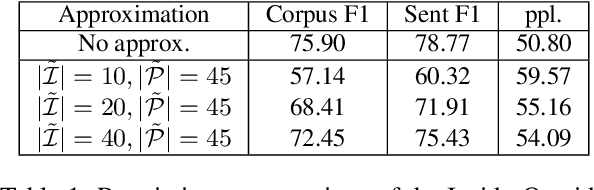
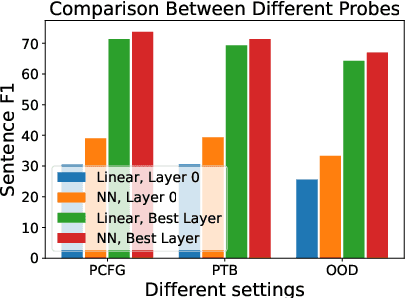
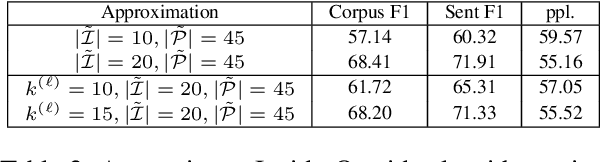
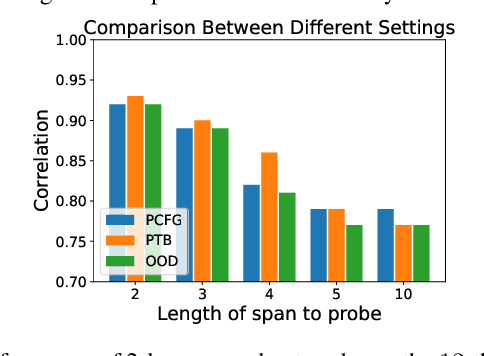
Pre-trained language models have been shown to encode linguistic structures, e.g. dependency and constituency parse trees, in their embeddings while being trained on unsupervised loss functions like masked language modeling. Some doubts have been raised whether the models actually are doing parsing or only some computation weakly correlated with it. We study questions: (a) Is it possible to explicitly describe transformers with realistic embedding dimension, number of heads, etc. that are capable of doing parsing -- or even approximate parsing? (b) Why do pre-trained models capture parsing structure? This paper takes a step toward answering these questions in the context of generative modeling with PCFGs. We show that masked language models like BERT or RoBERTa of moderate sizes can approximately execute the Inside-Outside algorithm for the English PCFG [Marcus et al, 1993]. We also show that the Inside-Outside algorithm is optimal for masked language modeling loss on the PCFG-generated data. We also give a construction of transformers with $50$ layers, $15$ attention heads, and $1275$ dimensional embeddings in average such that using its embeddings it is possible to do constituency parsing with $>70\%$ F1 score on PTB dataset. We conduct probing experiments on models pre-trained on PCFG-generated data to show that this not only allows recovery of approximate parse tree, but also recovers marginal span probabilities computed by the Inside-Outside algorithm, which suggests an implicit bias of masked language modeling towards this algorithm.
Task-Specific Skill Localization in Fine-tuned Language Models
Feb 13, 2023



Pre-trained language models can be fine-tuned to solve diverse NLP tasks, including in few-shot settings. Thus fine-tuning allows the model to quickly pick up task-specific ``skills,'' but there has been limited study of where these newly-learnt skills reside inside the massive model. This paper introduces the term skill localization for this problem and proposes a solution. Given the downstream task and a model fine-tuned on that task, a simple optimization is used to identify a very small subset of parameters ($\sim0.01$% of model parameters) responsible for ($>95$%) of the model's performance, in the sense that grafting the fine-tuned values for just this tiny subset onto the pre-trained model gives performance almost as well as the fine-tuned model. While reminiscent of recent works on parameter-efficient fine-tuning, the novel aspects here are that: (i) No further re-training is needed on the subset (unlike, say, with lottery tickets). (ii) Notable improvements are seen over vanilla fine-tuning with respect to calibration of predictions in-distribution ($40$-$90$% error reduction) as well as the quality of predictions out-of-distribution (OOD). In models trained on multiple tasks, a stronger notion of skill localization is observed, where the sparse regions corresponding to different tasks are almost disjoint, and their overlap (when it happens) is a proxy for task similarity. Experiments suggest that localization via grafting can assist certain forms of continual learning.