 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Depth and Looping for In-Context Learning with Task Diversity
Paper and Code
Oct 29, 2024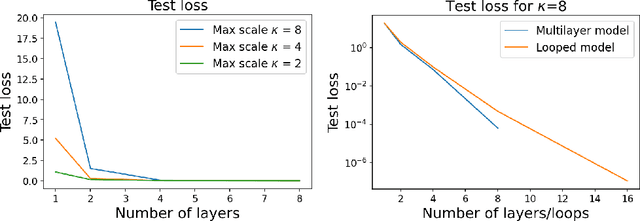
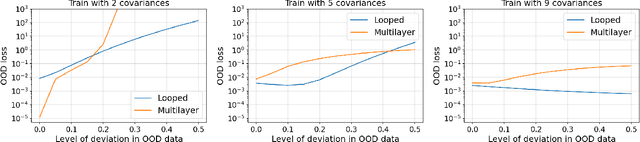
The intriguing in-context learning (ICL) abilities of deep Transformer models have lately garnered significant attention. By studying in-context linear regression on unimodal Gaussian data, recent empirical and theoretical works have argued that ICL emerges from Transformers' abilities to simulate learning algorithms like gradient descent. However, these works fail to capture the remarkable ability of Transformers to learn multiple tasks in context. To this end, we study in-context learning for linear regression with diverse tasks, characterized by data covariance matrices with condition numbers ranging from $[1, \kappa]$, and highlight the importance of depth in this setting. More specifically, (a) we show theoretical lower bounds of $\log(\kappa)$ (or $\sqrt{\kappa}$) linear attention layers in the unrestricted (or restricted) attention setting and, (b) we show that multilayer Transformers can indeed solve such tasks with a number of layers that matches the lower bounds. However, we show that this expressivity of multilayer Transformer comes at the price of robustness. In particular, multilayer Transformers are not robust to even distributional shifts as small as $O(e^{-L})$ in Wasserstein distance, where $L$ is the depth of the network. We then demonstrate that Looped Transformers -- a special class of multilayer Transformers with weight-sharing -- not only exhibit similar expressive power but are also provably robust under mild assumptions. Besides out-of-distribution generalization, we also show that Looped Transformers are the only models that exhibit a monotonic behavior of loss with respect to depth.