 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the difficulty of low-precision post-training quantization of large language models
Oct 18, 2024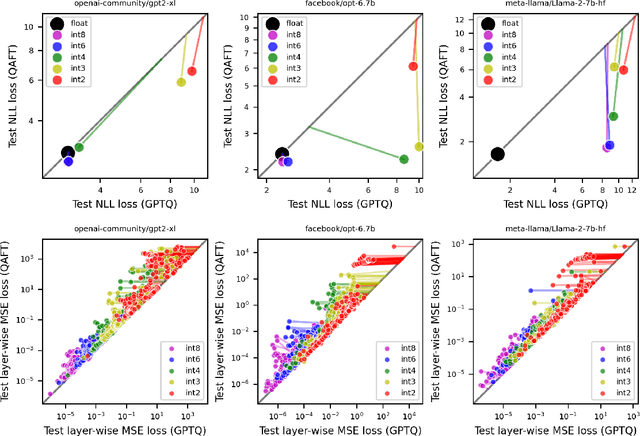
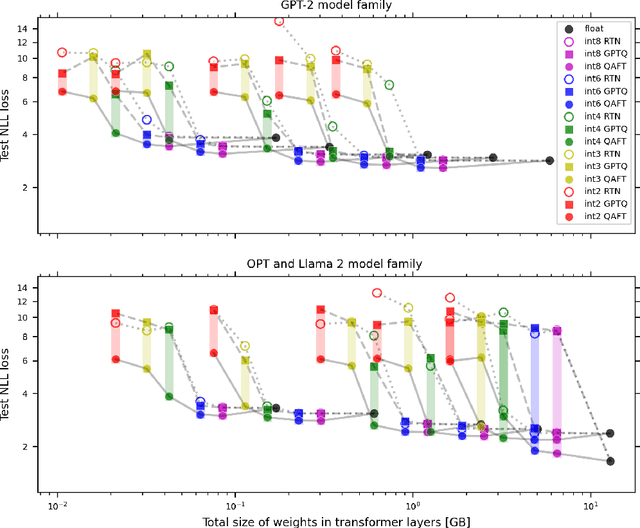
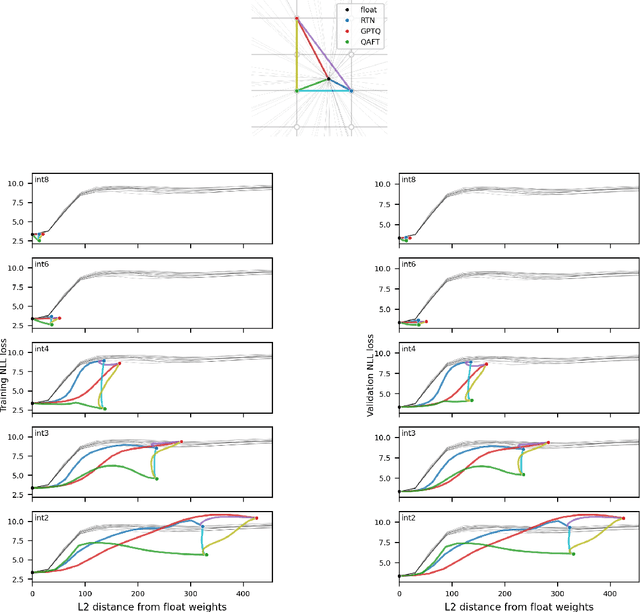
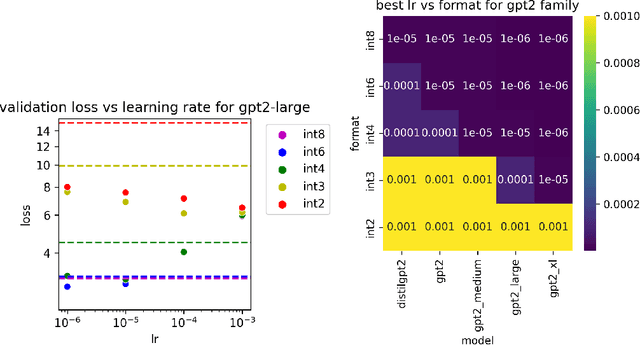
Large language models of high parameter counts are computationally expensive, yet can be made much more efficient by compressing their weights to very low numerical precision. This can be achieved either through post-training quantization by minimizing local, layer-wise quantization errors, or through quantization-aware fine-tuning by minimizing the global loss function. In this study, we discovered that, under the same data constraint, the former approach nearly always fared worse than the latter, a phenomenon particularly prominent when the numerical precision is very low. We further showed that this difficulty of post-training quantization arose from stark misalignment between optimization of the local and global objective functions. Our findings explains limited utility in minimization of local quantization error and the importance of direct quantization-aware fine-tuning, in the regime of large models at very low precision.
Scaling laws for post-training quantized large language models
Oct 15, 2024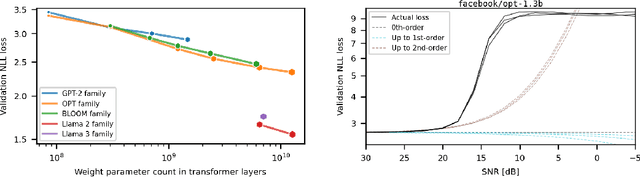
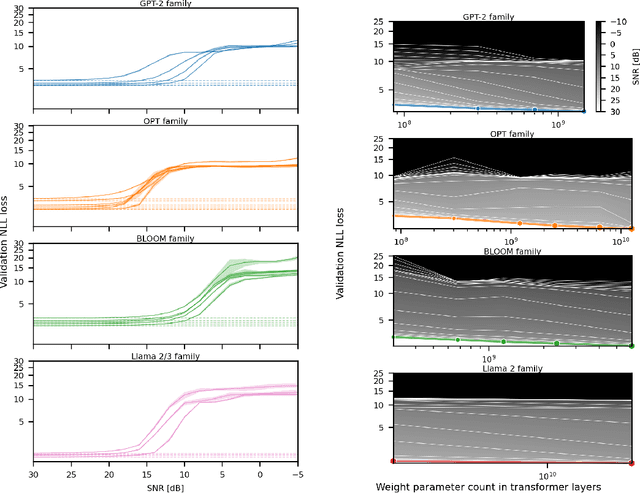
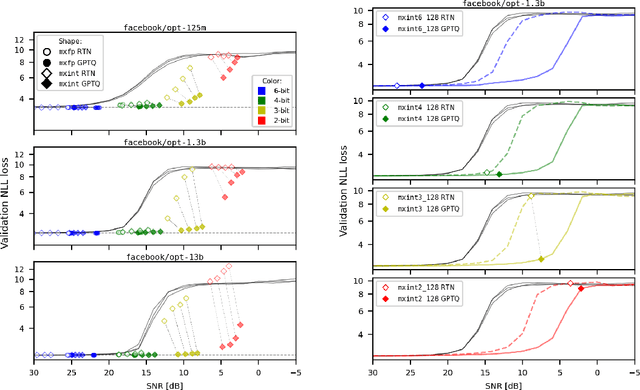
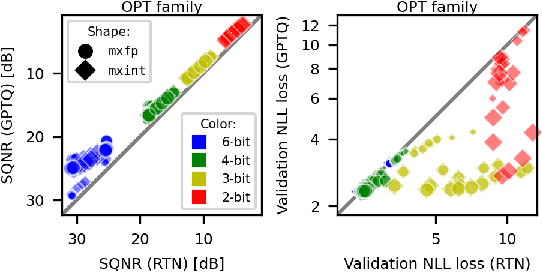
Generalization abilities of well-trained large language models (LLMs) are known to scale predictably as a function of model size. In contrast to the existence of practical scaling laws governing pre-training, the quality of LLMs after post-training compression remains highly unpredictable, often requiring case-by-case validation in practice. In this work, we attempted to close this gap for post-training weight quantization of LLMs by conducting a systematic empirical study on multiple LLM families quantized to numerous low-precision tensor data types using popular weight quantization techniques. We identified key scaling factors pertaining to characteristics of the local loss landscape, based on which the performance of quantized LLMs can be reasonably well predicted by a statistical model.
Combining multiple post-training techniques to achieve most efficient quantized LLMs
May 12, 2024Large Language Models (LLMs) have distinguished themselves with outstanding performance in complex language modeling tasks, yet they come with significant computational and storage challenges. This paper explores the potential of quantization to mitigate these challenges. We systematically study the combined application of two well-known post-training techniques, SmoothQuant and GPTQ, and provide a comprehensive analysis of their interactions and implications for advancing LLM quantization. We enhance the versatility of both techniques by enabling quantization to microscaling (MX) formats, expanding their applicability beyond their initial fixed-point format targets. We show that by applying GPTQ and SmoothQuant, and employing MX formats for quantizing models, we can achieve a significant reduction in the size of OPT models by up to 4x and LLaMA models by up to 3x with a negligible perplexity increase of 1-3%.
Self-Selected Attention Span for Accelerating Large Language Model Inference
Apr 14, 2024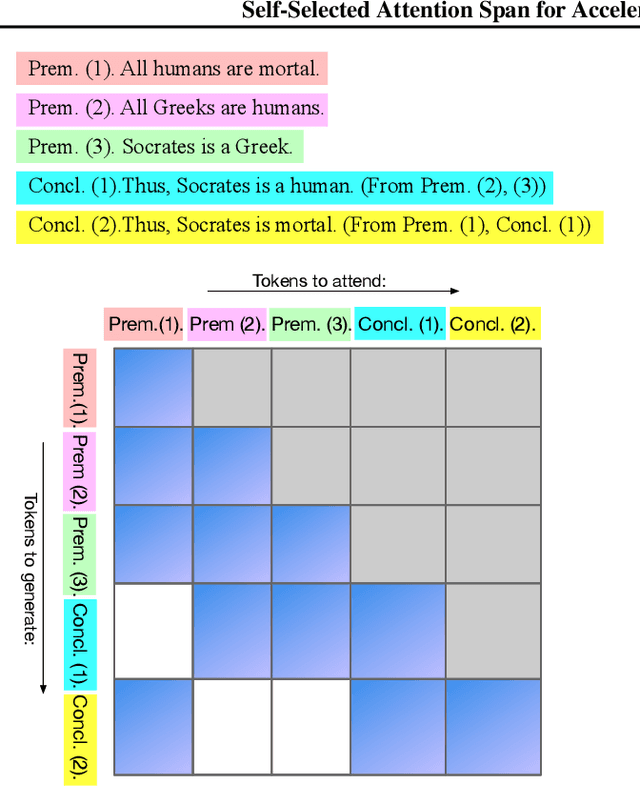
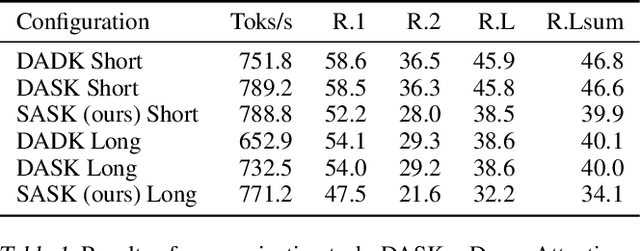
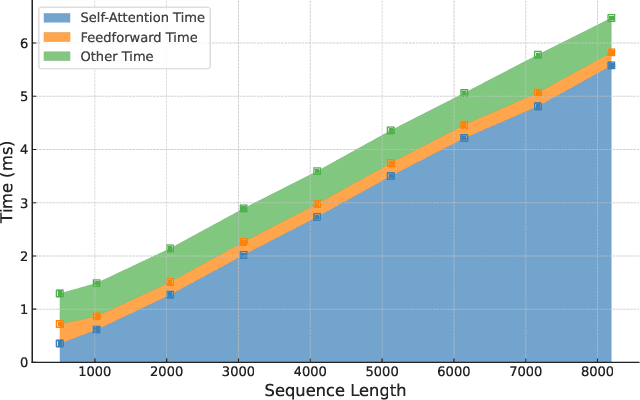
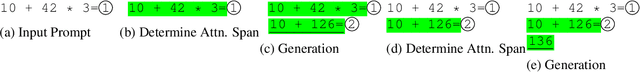
Large language models (LLMs) can solve challenging tasks. However, their inference computation on modern GPUs is highly inefficient due to the increasing number of tokens they must attend to as they generate new ones. To address this inefficiency, we capitalize on LLMs' problem-solving capabilities to optimize their own inference-time efficiency. We demonstrate with two specific tasks: (a) evaluating complex arithmetic expressions and (b) summarizing news articles. For both tasks, we create custom datasets to fine-tune an LLM. The goal of fine-tuning is twofold: first, to make the LLM learn to solve the evaluation or summarization task, and second, to train it to identify the minimal attention spans required for each step of the task. As a result, the fine-tuned model is able to convert these self-identified minimal attention spans into sparse attention masks on-the-fly during inference. We develop a custom CUDA kernel to take advantage of the reduced context to attend to. We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%. Our work presents an end-to-end demonstration showing that training LLMs to self-select their attention spans speeds up autoregressive inference in solving real-world tasks.