 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Visual Autoregressive Acceleration via Dual-Linkage Entropy Analysis
Feb 01, 2026Visual AutoRegressive modeling (VAR) suffers from substantial computational cost due to the massive token count involved. Failing to account for the continuous evolution of modeling dynamics, existing VAR token reduction methods face three key limitations: heuristic stage partition, non-adaptive schedules, and limited acceleration scope, thereby leaving significant acceleration potential untapped. Since entropy variation intrinsically reflects the transition of predictive uncertainty, it offers a principled measure to capture modeling dynamics evolution. Therefore, we propose NOVA, a training-free token reduction acceleration framework for VAR models via entropy analysis. NOVA adaptively determines the acceleration activation scale during inference by online identifying the inflection point of scale entropy growth. Through scale-linkage and layer-linkage ratio adjustment, NOVA dynamically computes distinct token reduction ratios for each scale and layer, pruning low-entropy tokens while reusing the cache derived from the residuals at the prior scale to accelerate inference and maintain generation quality. Extensive experiments and analyses validate NOVA as a simple yet effective training-free acceleration framework.
Federated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Vision Also You Need: Navigating Out-of-Distribution Detection with Multimodal Large Language Model
Jan 20, 2026Out-of-Distribution (OOD) detection is a critical task that has garnered significant attention. The emergence of CLIP has spurred extensive research into zero-shot OOD detection, often employing a training-free approach. Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution samples in the image space. In this paper, we propose a novel pipeline, MM-OOD, which leverages the multimodal reasoning capabilities of MLLMs and their ability to conduct multi-round conversations for enhanced outlier detection. Our method is designed to improve performance in both near OOD and far OOD tasks. Specifically, (1) for near OOD tasks, we directly feed ID images and corresponding text prompts into MLLMs to identify potential outliers; and (2) for far OOD tasks, we introduce the sketch-generate-elaborate framework: first, we sketch outlier exposure using text prompts, then generate corresponding visual OOD samples, and finally elaborate by using multimodal prompts. Experiments demonstrate that our method achieves significant improvements on widely used multimodal datasets such as Food-101, while also validating its scalability on ImageNet-1K.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
CurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
Oct 14, 2025Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.
LargeMvC-Net: Anchor-based Deep Unfolding Network for Large-scale Multi-view Clustering
Jul 28, 2025Deep anchor-based multi-view clustering methods enhance the scalability of neural networks by utilizing representative anchors to reduce the computational complexity of large-scale clustering. Despite their scalability advantages, existing approaches often incorporate anchor structures in a heuristic or task-agnostic manner, either through post-hoc graph construction or as auxiliary components for message passing. Such designs overlook the core structural demands of anchor-based clustering, neglecting key optimization principles. To bridge this gap, we revisit the underlying optimization problem of large-scale anchor-based multi-view clustering and unfold its iterative solution into a novel deep network architecture, termed LargeMvC-Net. The proposed model decomposes the anchor-based clustering process into three modules: RepresentModule, NoiseModule, and AnchorModule, corresponding to representation learning, noise suppression, and anchor indicator estimation. Each module is derived by unfolding a step of the original optimization procedure into a dedicated network component, providing structural clarity and optimization traceability. In addition, an unsupervised reconstruction loss aligns each view with the anchor-induced latent space, encouraging consistent clustering structures across views. Extensive experiments on several large-scale multi-view benchmarks show that LargeMvC-Net consistently outperforms state-of-the-art methods in terms of both effectiveness and scalability.
Dark-EvGS: Event Camera as an Eye for Radiance Field in the Dark
Jul 16, 2025



In low-light environments, conventional cameras often struggle to capture clear multi-view images of objects due to dynamic range limitations and motion blur caused by long exposure. Event cameras, with their high-dynamic range and high-speed properties, have the potential to mitigate these issues. Additionally, 3D Gaussian Splatting (GS) enables radiance field reconstruction, facilitating bright frame synthesis from multiple viewpoints in low-light conditions. However, naively using an event-assisted 3D GS approach still faced challenges because, in low light, events are noisy, frames lack quality, and the color tone may be inconsistent. To address these issues, we propose Dark-EvGS, the first event-assisted 3D GS framework that enables the reconstruction of bright frames from arbitrary viewpoints along the camera trajectory. Triplet-level supervision is proposed to gain holistic knowledge, granular details, and sharp scene rendering. The color tone matching block is proposed to guarantee the color consistency of the rendered frames. Furthermore, we introduce the first real-captured dataset for the event-guided bright frame synthesis task via 3D GS-based radiance field reconstruction. Experiments demonstrate that our method achieves better results than existing methods, conquering radiance field reconstruction under challenging low-light conditions. The code and sample data are included in the supplementary material.
3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering
Jul 16, 2025
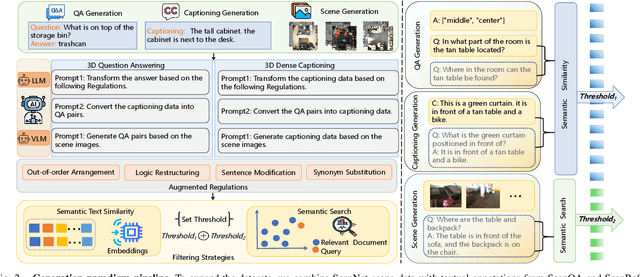


With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks. Our code and generated datasets will be publicly released to benefit the community, and both can be accessed on the https://3D-MoRe.github.io.
Graph of Verification: Structured Verification of LLM Reasoning with Directed Acyclic Graphs
Jun 14, 2025



Verifying the reliability of complex, multi-step reasoning in Large Language Models (LLMs) remains a fundamental challenge, as existing methods often lack both faithfulness and precision. To address this issue, we propose the Graph of Verification (GoV) framework. GoV offers three key contributions: First, it explicitly models the underlying deductive process as a directed acyclic graph (DAG), whether this structure is implicit or explicitly constructed. Second, it enforces a topological order over the DAG to guide stepwise verification. Third, GoV introduces the notion of customizable node blocks, which flexibly define the verification granularity, from atomic propositions to full paragraphs, while ensuring that all requisite premises derived from the graph are provided as contextual input for each verification unit. We evaluate GoV on the Number Triangle Summation task and the ProcessBench benchmark with varying levels of reasoning complexity. Experimental results show that GoV substantially improves verification accuracy, faithfulness, and error localization when compared to conventional end-to-end verification approaches. Our code and data are available at https://github.com/Frevor/Graph-of-Verification.
SAMamba: Adaptive State Space Modeling with Hierarchical Vision for Infrared Small Target Detection
May 29, 2025Infrared small target detection (ISTD) is vital for long-range surveillance in military, maritime, and early warning applications. ISTD is challenged by targets occupying less than 0.15% of the image and low distinguishability from complex backgrounds. Existing deep learning methods often suffer from information loss during downsampling and inefficient global context modeling. This paper presents SAMamba, a novel framework integrating SAM2's hierarchical feature learning with Mamba's selective sequence modeling. Key innovations include: (1) A Feature Selection Adapter (FS-Adapter) for efficient natural-to-infrared domain adaptation via dual-stage selection (token-level with a learnable task embedding and channel-wise adaptive transformations); (2) A Cross-Channel State-Space Interaction (CSI) module for efficient global context modeling with linear complexity using selective state space modeling; and (3) A Detail-Preserving Contextual Fusion (DPCF) module that adaptively combines multi-scale features with a gating mechanism to balance high-resolution and low-resolution feature contributions. SAMamba addresses core ISTD challenges by bridging the domain gap, maintaining fine-grained details, and efficiently modeling long-range dependencies. Experiments on NUAA-SIRST, IRSTD-1k, and NUDT-SIRST datasets show SAMamba significantly outperforms state-of-the-art methods, especially in challenging scenarios with heterogeneous backgrounds and varying target scales. Code: https://github.com/zhengshuchen/SAMamba.