 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSTNet: Enhanced Polyp Segmentation with Multi-scale Alignment and Frequency Domain Integration
Sep 13, 2024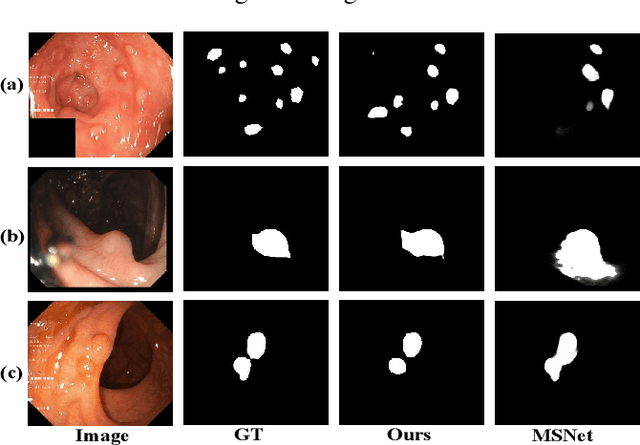
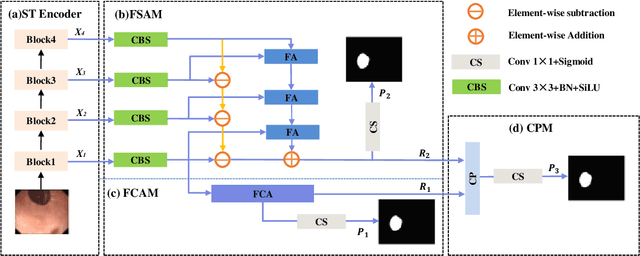
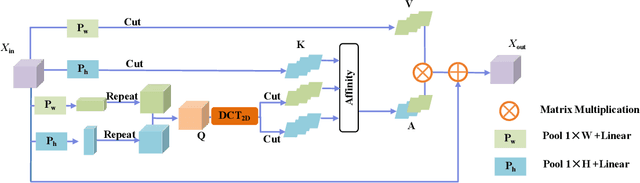
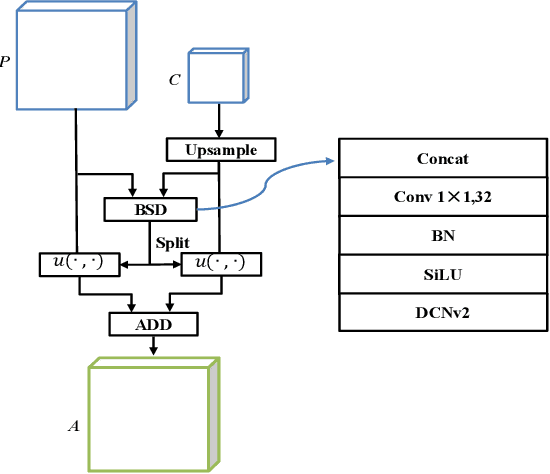
Accurate segmentation of colorectal polyps in colonoscopy images is crucial for effective diagnosis and management of colorectal cancer (CRC). However, current deep learning-based methods primarily rely on fusing RGB information across multiple scales, leading to limitations in accurately identifying polyps due to restricted RGB domain information and challenges in feature misalignment during multi-scale aggregation. To address these limitations, we propose the Polyp Segmentation Network with Shunted Transformer (PSTNet), a novel approach that integrates both RGB and frequency domain cues present in the images. PSTNet comprises three key modules: the Frequency Characterization Attention Module (FCAM) for extracting frequency cues and capturing polyp characteristics, the Feature Supplementary Alignment Module (FSAM) for aligning semantic information and reducing misalignment noise, and the Cross Perception localization Module (CPM) for synergizing frequency cues with high-level semantics to achieve efficient polyp segmentation. Extensive experiments on challenging datasets demonstrate PSTNet's significant improvement in polyp segmentation accuracy across various metrics, consistently outperforming state-of-the-art methods. The integration of frequency domain cues and the novel architectural design of PSTNet contribute to advancing computer-assisted polyp segmentation, facilitating more accurate diagnosis and management of CRC.
Symmetry-Enhanced Attention Network for Acute Ischemic Infarct Segmentation with Non-Contrast CT Images
Oct 11, 2021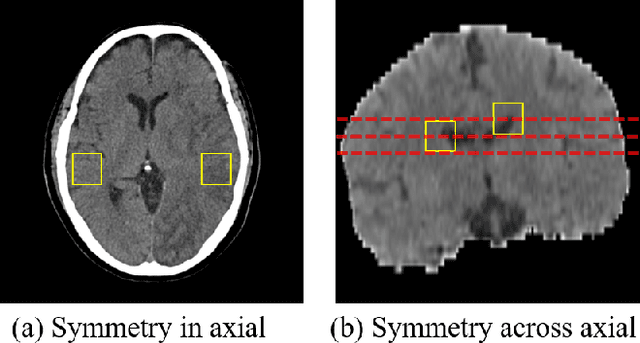
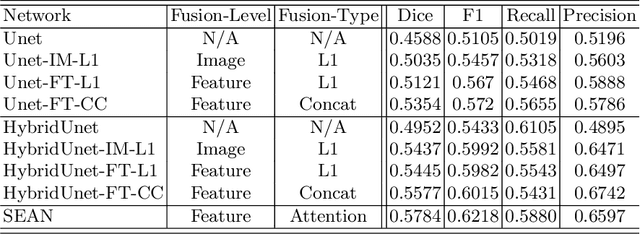
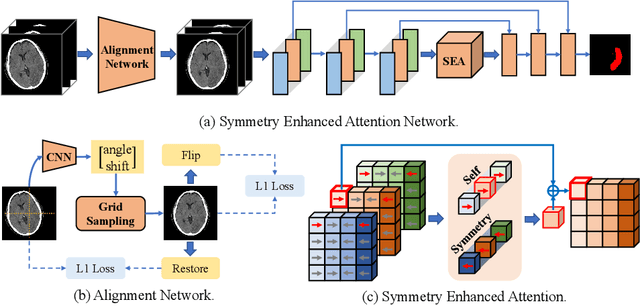

Quantitative estimation of the acute ischemic infarct is crucial to improve neurological outcomes of the patients with stroke symptoms. Since the density of lesions is subtle and can be confounded by normal physiologic changes, anatomical asymmetry provides useful information to differentiate the ischemic and healthy brain tissue. In this paper, we propose a symmetry enhanced attention network (SEAN) for acute ischemic infarct segmentation. Our proposed network automatically transforms an input CT image into the standard space where the brain tissue is bilaterally symmetric. The transformed image is further processed by a Ushape network integrated with the proposed symmetry enhanced attention for pixel-wise labelling. The symmetry enhanced attention can efficiently capture context information from the opposite side of the image by estimating long-range dependencies. Experimental results show that the proposed SEAN outperforms some symmetry-based state-of-the-art methods in terms of both dice coefficient and infarct localization.
Segmentation-based Method combined with Dynamic Programming for Brain Midline Delineation
Feb 27, 2020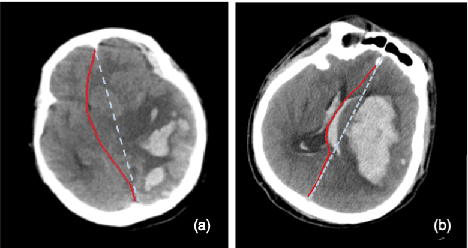

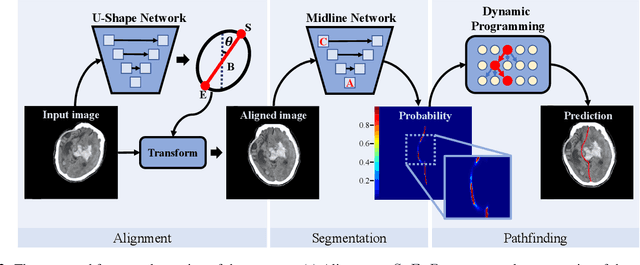

The midline related pathological image features are crucial for evaluating the severity of brain compression caused by stroke or traumatic brain injury (TBI). The automated midline delineation not only improves the assessment and clinical decision making for patients with stroke symptoms or head trauma but also reduces the time of diagnosis. Nevertheless, most of the previous methods model the midline by localizing the anatomical points, which are hard to detect or even missing in severe cases. In this paper, we formulate the brain midline delineation as a segmentation task and propose a three-stage framework. The proposed framework firstly aligns an input CT image into the standard space. Then, the aligned image is processed by a midline detection network (MD-Net) integrated with the CoordConv Layer and Cascade AtrousCconv Module to obtain the probability map. Finally, we formulate the optimal midline selection as a pathfinding problem to solve the problem of the discontinuity of midline delineation. Experimental results show that our proposed framework can achieve superior performance on one in-house dataset and one public dataset.
Predictive Ensemble Learning with Application to Scene Text Detection
May 16, 2019

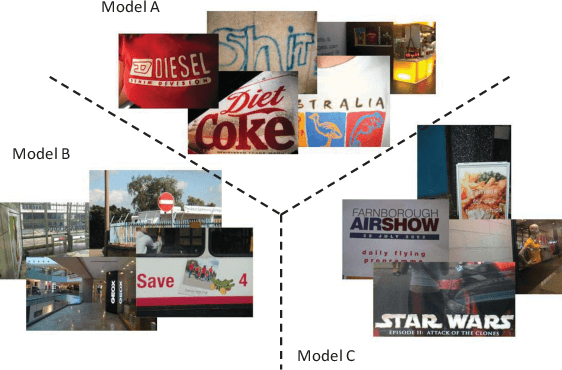
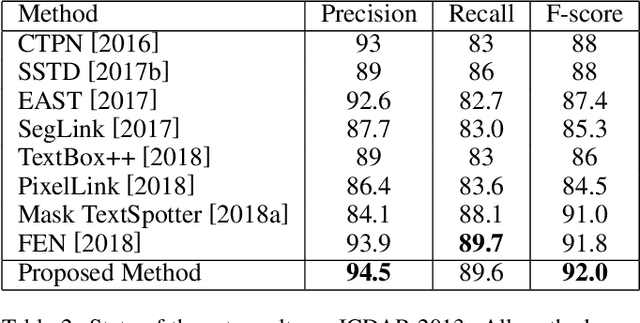
Deep learning based approaches have achieved significant progresses in different tasks like classification, detection, segmentation, and so on. Ensemble learning is widely known to further improve performance by combining multiple complementary models. It is easy to apply ensemble learning for classification tasks, for example, based on averaging, voting, or other methods. However, for other tasks (like object detection) where the outputs are varying in quantity and unable to be simply compared, the ensemble of multiple models become difficult. In this paper, we propose a new method called Predictive Ensemble Learning (PEL), based on powerful predictive ability of deep neural networks, to directly predict the best performing model among a pool of base models for each test example, thus transforming ensemble learning to a traditional classification task. Taking scene text detection as the application, where no suitable ensemble learning strategy exists, PEL can significantly improve the performance, compared to either individual state-of-the-art models, or the fusion of multiple models by non-maximum suppression. Experimental results show the possibility and potential of PEL in predicting different models' performance based only on a query example, which can be extended for ensemble learning in many other complex tasks.
Semi-Supervised Brain Lesion Segmentation with an Adapted Mean Teacher Model
Mar 04, 2019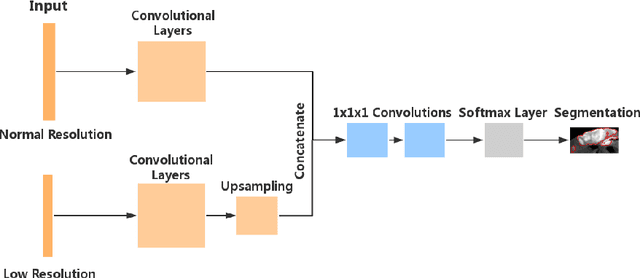
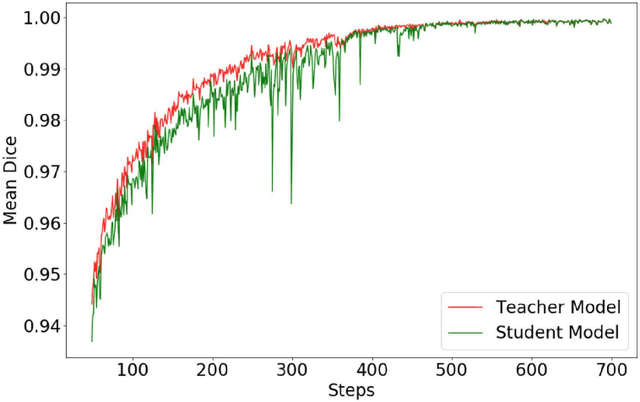

Automated brain lesion segmentation provides valuable information for the analysis and intervention of patients. In particular, methods based on convolutional neural networks (CNNs) have achieved state-of-the-art segmentation performance. However, CNNs usually require a decent amount of annotated data, which may be costly and time-consuming to obtain. Since unannotated data is generally abundant, it is desirable to use unannotated data to improve the segmentation performance for CNNs when limited annotated data is available. In this work, we propose a semi-supervised learning (SSL) approach to brain lesion segmentation, where unannotated data is incorporated into the training of CNNs. We adapt the mean teacher model, which is originally developed for SSL-based image classification, for brain lesion segmentation. Assuming that the network should produce consistent outputs for similar inputs, a loss of segmentation consistency is designed and integrated into a self-ensembling framework. Specifically, we build a student model and a teacher model, which share the same CNN architecture for segmentation. The student and teacher models are updated alternately. At each step, the student model learns from the teacher model by minimizing the weighted sum of the segmentation loss computed from annotated data and the segmentation consistency loss between the teacher and student models computed from unannotated data. Then, the teacher model is updated by combining the updated student model with the historical information of teacher models using an exponential moving average strategy. For demonstration, the proposed approach was evaluated on ischemic stroke lesion segmentation, where it improves stroke lesion segmentation with the incorporation of unannotated data.
Integrating Feature and Image Pyramid: A Lung Nodule Detector Learned in Curriculum Fashion
Aug 01, 2018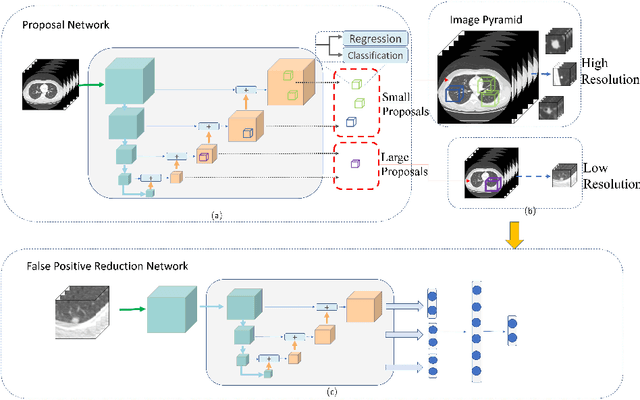
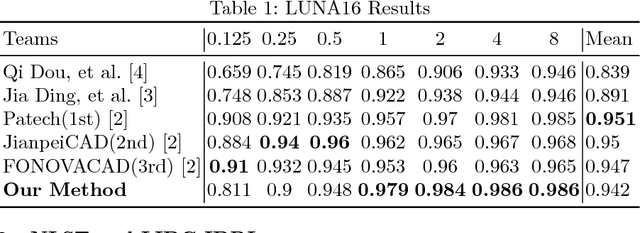
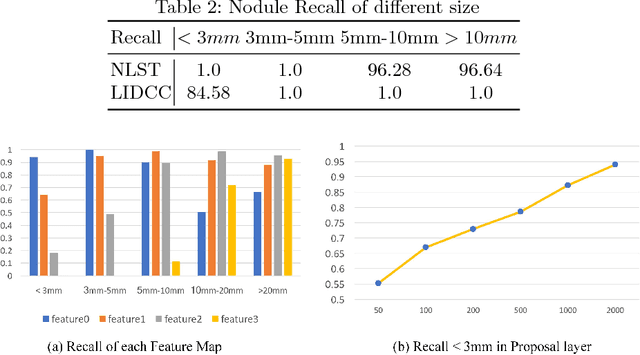

Lung nodules suffer large variation in size and appearance in CT images. Nodules less than 10mm can easily lose information after down-sampling in convolutional neural networks, which results in low sensitivity. In this paper, a combination of 3D image and feature pyramid is exploited to integrate lower-level texture features with high-level semantic features, thus leading to a higher recall. However, 3D operations are time and memory consuming, which aggravates the situation with the explosive growth of medical images. To tackle this problem, we propose a general curriculum training strategy to speed up training. An dynamic sampling method is designed to pick up partial samples which give the best contribution to network training, thus leading to much less time consuming. In experiments, we demonstrate that the proposed network outperforms previous state-of-the-art methods. Meanwhile, our sampling strategy halves the training time of the proposal network on LUNA16.