 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTalking: A Unified Audio-Video Framework for Talking Portrait Generation
Mar 02, 2026While state-of-the-art audio-video generation models like Veo3 and Sora2 demonstrate remarkable capabilities, their closed-source nature makes their architectures and training paradigms inaccessible. To bridge this gap in accessibility and performance, we introduce UniTalking, a unified, end-to-end diffusion framework for generating high-fidelity speech and lip-synchronized video. At its core, our framework employs Multi-Modal Transformer Blocks to explicitly model the fine-grained temporal correspondence between audio and video latent tokens via a shared self-attention mechanism. By leveraging powerful priors from a pre-trained video generation model, our framework ensures state-of-the-art visual fidelity while enabling efficient training. Furthermore, UniTalking incorporates a personalized voice cloning capability, allowing the generation of speech in a target style from a brief audio reference. Qualitative and quantitative results demonstrate that our method produces highly realistic talking portraits, achieving superior performance over existing open-source approaches in lip-sync accuracy, audio naturalness, and overall perceptual quality.
Hierarchical Event Memory for Accurate and Low-latency Online Video Temporal Grounding
Aug 06, 2025In this paper, we tackle the task of online video temporal grounding (OnVTG), which requires the model to locate events related to a given text query within a video stream. Unlike regular video temporal grounding, OnVTG requires the model to make predictions without observing future frames. As online videos are streaming inputs and can go on indefinitely, it is impractical and inefficient to store all historical inputs. The existing OnVTG models employ memory to store recent historical video frame features and predict scores indicating whether the current frame corresponds to the start or end time of the target event. However, these methods lack effective event modeling and cannot retain long-term historical information, leading to low performance. To tackle these challenges, we propose a hierarchical event memory for OnVTG. We propose an event-based OnVTG framework that makes predictions based on event proposals that model event-level information with various durations. To preserve historically valuable event information, we introduce a hierarchical event memory that retains historical events, allowing the model to access both recent and long-term information. To enable the real-time prediction, we further propose a future prediction branch that predicts whether the target event will occur shortly and further regresses the start time of the event. We achieve state-of-the-art performance on the TACoS, ActivityNet Captions, and MAD datasets. Code is available at https://github.com/minghangz/OnVTG.
GPPF: A General Perception Pre-training Framework via Sparsely Activated Multi-Task Learning
Aug 04, 2022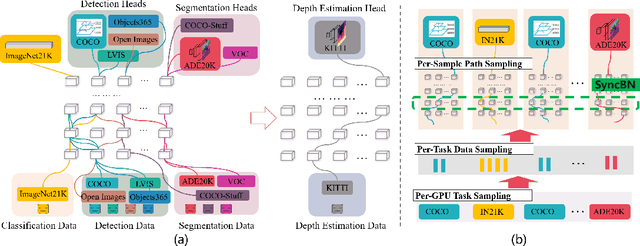
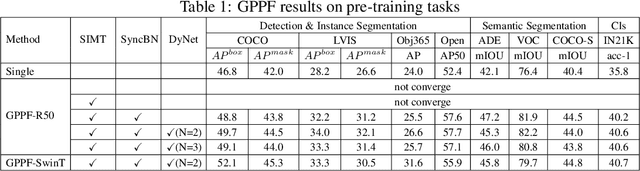
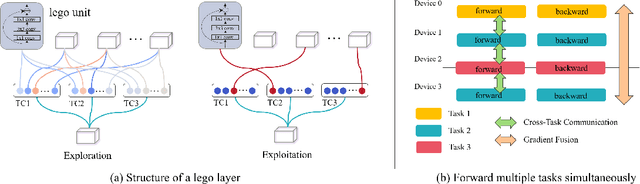
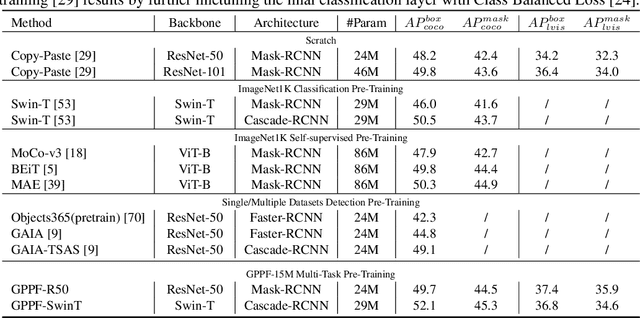
Pre-training over mixtured multi-task, multi-domain, and multi-modal data remains an open challenge in vision perception pre-training. In this paper, we propose GPPF, a General Perception Pre-training Framework, that pre-trains a task-level dynamic network, which is composed by knowledge "legos" in each layers, on labeled multi-task and multi-domain datasets. By inspecting humans' innate ability to learn in complex environment, we recognize and transfer three critical elements to deep networks: (1) simultaneous exposure to diverse cross-task and cross-domain information in each batch. (2) partitioned knowledge storage in separate lego units driven by knowledge sharing. (3) sparse activation of a subset of lego units for both pre-training and downstream tasks. Noteworthy, the joint training of disparate vision tasks is non-trivial due to their differences in input shapes, loss functions, output formats, data distributions, etc. Therefore, we innovatively develop a plug-and-play multi-task training algorithm, which supports Single Iteration Multiple Tasks (SIMT) concurrently training. SIMT lays the foundation of pre-training with large-scale multi-task multi-domain datasets and is proved essential for stable training in our GPPF experiments. Excitingly, the exhaustive experiments show that, our GPPF-R50 model achieves significant improvements of 2.5-5.8 over a strong baseline of the 8 pre-training tasks in GPPF-15M and harvests a range of SOTAs over the 22 downstream tasks with similar computation budgets. We also validate the generalization ability of GPPF to SOTA vision transformers with consistent improvements. These solid experimental results fully prove the effective knowledge learning, storing, sharing, and transfer provided by our novel GPPF framework.
Integrating Feature and Image Pyramid: A Lung Nodule Detector Learned in Curriculum Fashion
Aug 01, 2018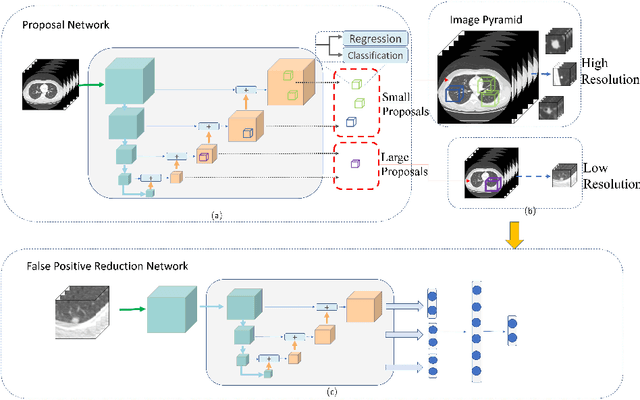
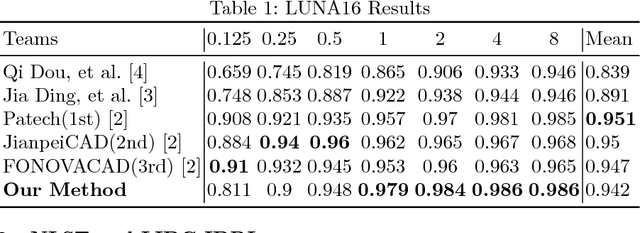
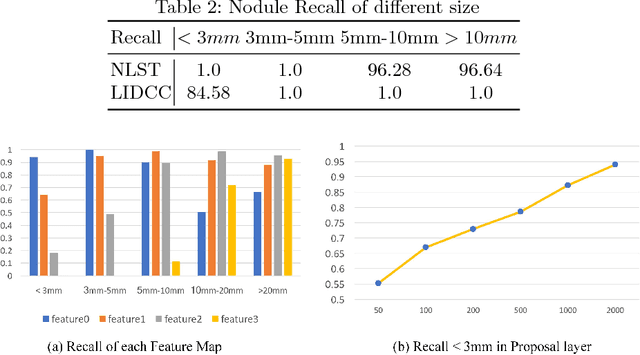

Lung nodules suffer large variation in size and appearance in CT images. Nodules less than 10mm can easily lose information after down-sampling in convolutional neural networks, which results in low sensitivity. In this paper, a combination of 3D image and feature pyramid is exploited to integrate lower-level texture features with high-level semantic features, thus leading to a higher recall. However, 3D operations are time and memory consuming, which aggravates the situation with the explosive growth of medical images. To tackle this problem, we propose a general curriculum training strategy to speed up training. An dynamic sampling method is designed to pick up partial samples which give the best contribution to network training, thus leading to much less time consuming. In experiments, we demonstrate that the proposed network outperforms previous state-of-the-art methods. Meanwhile, our sampling strategy halves the training time of the proposal network on LUNA16.
Face Detection with End-to-End Integration of a ConvNet and a 3D Model
Aug 29, 2016



This paper presents a method for face detection in the wild, which integrates a ConvNet and a 3D mean face model in an end-to-end multi-task discriminative learning framework. The 3D mean face model is predefined and fixed (e.g., we used the one provided in the AFLW dataset). The ConvNet consists of two components: (i) The face pro- posal component computes face bounding box proposals via estimating facial key-points and the 3D transformation (rotation and translation) parameters for each predicted key-point w.r.t. the 3D mean face model. (ii) The face verification component computes detection results by prun- ing and refining proposals based on facial key-points based configuration pooling. The proposed method addresses two issues in adapting state- of-the-art generic object detection ConvNets (e.g., faster R-CNN) for face detection: (i) One is to eliminate the heuristic design of prede- fined anchor boxes in the region proposals network (RPN) by exploit- ing a 3D mean face model. (ii) The other is to replace the generic RoI (Region-of-Interest) pooling layer with a configuration pooling layer to respect underlying object structures. The multi-task loss consists of three terms: the classification Softmax loss and the location smooth l1 -losses [14] of both the facial key-points and the face bounding boxes. In ex- periments, our ConvNet is trained on the AFLW dataset only and tested on the FDDB benchmark with fine-tuning and on the AFW benchmark without fine-tuning. The proposed method obtains very competitive state-of-the-art performance in the two benchmarks.