 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPPF: A General Perception Pre-training Framework via Sparsely Activated Multi-Task Learning
Paper and Code
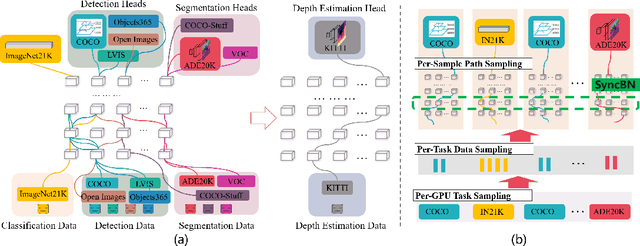
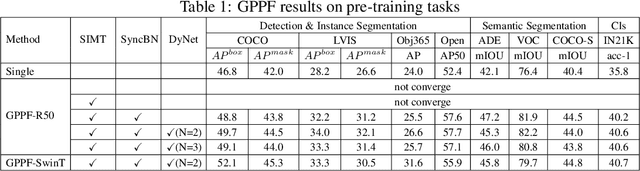
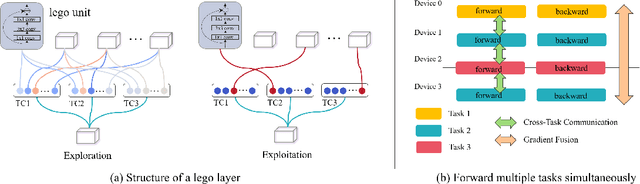
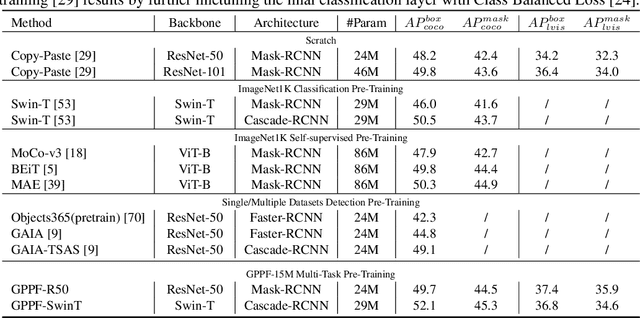
Pre-training over mixtured multi-task, multi-domain, and multi-modal data remains an open challenge in vision perception pre-training. In this paper, we propose GPPF, a General Perception Pre-training Framework, that pre-trains a task-level dynamic network, which is composed by knowledge "legos" in each layers, on labeled multi-task and multi-domain datasets. By inspecting humans' innate ability to learn in complex environment, we recognize and transfer three critical elements to deep networks: (1) simultaneous exposure to diverse cross-task and cross-domain information in each batch. (2) partitioned knowledge storage in separate lego units driven by knowledge sharing. (3) sparse activation of a subset of lego units for both pre-training and downstream tasks. Noteworthy, the joint training of disparate vision tasks is non-trivial due to their differences in input shapes, loss functions, output formats, data distributions, etc. Therefore, we innovatively develop a plug-and-play multi-task training algorithm, which supports Single Iteration Multiple Tasks (SIMT) concurrently training. SIMT lays the foundation of pre-training with large-scale multi-task multi-domain datasets and is proved essential for stable training in our GPPF experiments. Excitingly, the exhaustive experiments show that, our GPPF-R50 model achieves significant improvements of 2.5-5.8 over a strong baseline of the 8 pre-training tasks in GPPF-15M and harvests a range of SOTAs over the 22 downstream tasks with similar computation budgets. We also validate the generalization ability of GPPF to SOTA vision transformers with consistent improvements. These solid experimental results fully prove the effective knowledge learning, storing, sharing, and transfer provided by our novel GPPF framework.