 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Fixating on Prompts: Reasoning Hijacking and Constraint Tightening for Red-Teaming LLM Agents
Apr 07, 2026With the widespread application of LLM-based agents across various domains, their complexity has introduced new security threats. Existing red-team methods mostly rely on modifying user prompts, which lack adaptability to new data and may impact the agent's performance. To address the challenge, this paper proposes the JailAgent framework, which completely avoids modifying the user prompt. Specifically, it implicitly manipulates the agent's reasoning trajectory and memory retrieval with three key stages: Trigger Extraction, Reasoning Hijacking, and Constraint Tightening. Through precise trigger identification, real-time adaptive mechanisms, and an optimized objective function, JailAgent demonstrates outstanding performance in cross-model and cross-scenario environments.
ProtRLSearch: A Multi-Round Multimodal Protein Search Agent with Large Language Models Trained via Reinforcement Learning
Mar 02, 2026Protein analysis tasks arising in healthcare settings often require accurate reasoning under protein sequence constraints, involving tasks such as functional interpretation of disease-related variants, protein-level analysis for clinical research, and similar scenarios. To address such tasks, search agents are introduced to search protein-related information, providing support for disease-related variant analysis and protein function reasoning in protein-centric inference. However, such search agents are mostly limited to single-round, text-only modality search, which prevents the protein sequence modality from being incorporated as a multimodal input into the search decision-making process. Meanwhile, their reliance on reinforcement learning (RL) supervision that focuses solely on the final answer results in a lack of search process constraints, making deviations in keyword selection and reasoning directions difficult to identify and correct in a timely manner. To address these limitations, we propose ProtRLSearch, a multi-round protein search agent trained with multi-dimensional reward based RL, which jointly leverages protein sequence and text as multimodal inputs during real-time search to produce high quality reports. To evaluate the ability of models to integrate protein sequence information and text-based multimodal inputs in realistic protein query settings, we construct ProtMCQs, a benchmark of 3,000 multiple choice questions (MCQs) organized into three difficulty levels. The benchmark evaluates protein query tasks that range from sequence constrained reasoning about protein function and phenotype changes to comprehensive protein reasoning that integrates multi-dimensional sequence features with signal pathways and regulatory networks.
Exploring Jailbreak Attacks on LLMs through Intent Concealment and Diversion
May 20, 2025



Although large language models (LLMs) have achieved remarkable advancements, their security remains a pressing concern. One major threat is jailbreak attacks, where adversarial prompts bypass model safeguards to generate harmful or objectionable content. Researchers study jailbreak attacks to understand security and robustness of LLMs. However, existing jailbreak attack methods face two main challenges: (1) an excessive number of iterative queries, and (2) poor generalization across models. In addition, recent jailbreak evaluation datasets focus primarily on question-answering scenarios, lacking attention to text generation tasks that require accurate regeneration of toxic content. To tackle these challenges, we propose two contributions: (1) ICE, a novel black-box jailbreak method that employs Intent Concealment and divErsion to effectively circumvent security constraints. ICE achieves high attack success rates (ASR) with a single query, significantly improving efficiency and transferability across different models. (2) BiSceneEval, a comprehensive dataset designed for assessing LLM robustness in question-answering and text-generation tasks. Experimental results demonstrate that ICE outperforms existing jailbreak techniques, revealing critical vulnerabilities in current defense mechanisms. Our findings underscore the necessity of a hybrid security strategy that integrates predefined security mechanisms with real-time semantic decomposition to enhance the security of LLMs.
Divide and Conquer: A Hybrid Strategy Defeats Multimodal Large Language Models
Dec 21, 2024Large language models (LLMs) are widely applied in various fields of society due to their powerful reasoning, understanding, and generation capabilities. However, the security issues associated with these models are becoming increasingly severe. Jailbreaking attacks, as an important method for detecting vulnerabilities in LLMs, have been explored by researchers who attempt to induce these models to generate harmful content through various attack methods. Nevertheless, existing jailbreaking methods face numerous limitations, such as excessive query counts, limited coverage of jailbreak modalities, low attack success rates, and simplistic evaluation methods. To overcome these constraints, this paper proposes a multimodal jailbreaking method: JMLLM. This method integrates multiple strategies to perform comprehensive jailbreak attacks across text, visual, and auditory modalities. Additionally, we contribute a new and comprehensive dataset for multimodal jailbreaking research: TriJail, which includes jailbreak prompts for all three modalities. Experiments on the TriJail dataset and the benchmark dataset AdvBench, conducted on 13 popular LLMs, demonstrate advanced attack success rates and significant reduction in time overhead.
Low-Resource Fast Text Classification Based on Intra-Class and Inter-Class Distance Calculation
Dec 13, 2024In recent years, text classification methods based on neural networks and pre-trained models have gained increasing attention and demonstrated excellent performance. However, these methods still have some limitations in practical applications: (1) They typically focus only on the matching similarity between sentences. However, there exists implicit high-value information both within sentences of the same class and across different classes, which is very crucial for classification tasks. (2) Existing methods such as pre-trained language models and graph-based approaches often consume substantial memory for training and text-graph construction. (3) Although some low-resource methods can achieve good performance, they often suffer from excessively long processing times. To address these challenges, we propose a low-resource and fast text classification model called LFTC. Our approach begins by constructing a compressor list for each class to fully mine the regularity information within intra-class data. We then remove redundant information irrelevant to the target classification to reduce processing time. Finally, we compute the similarity distance between text pairs for classification. We evaluate LFTC on 9 publicly available benchmark datasets, and the results demonstrate significant improvements in performance and processing time, especially under limited computational and data resources, highlighting its superior advantages.
GPPF: A General Perception Pre-training Framework via Sparsely Activated Multi-Task Learning
Aug 04, 2022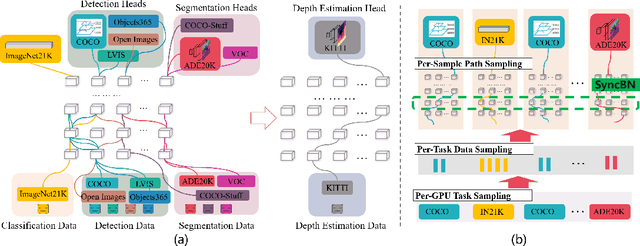
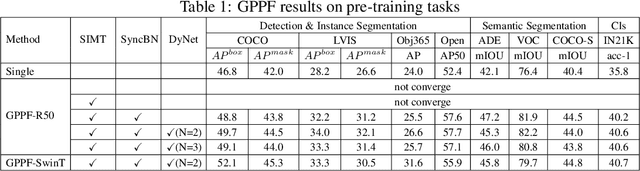
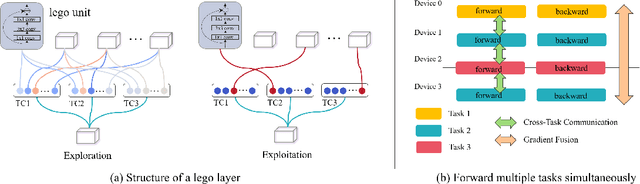
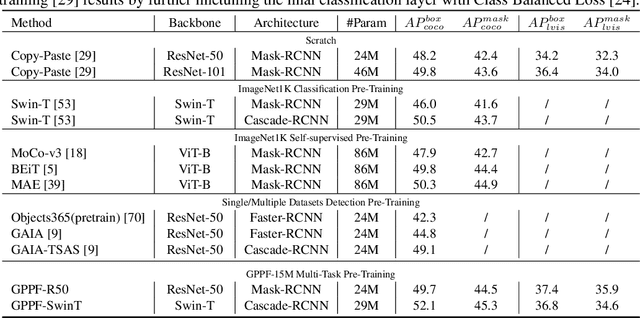
Pre-training over mixtured multi-task, multi-domain, and multi-modal data remains an open challenge in vision perception pre-training. In this paper, we propose GPPF, a General Perception Pre-training Framework, that pre-trains a task-level dynamic network, which is composed by knowledge "legos" in each layers, on labeled multi-task and multi-domain datasets. By inspecting humans' innate ability to learn in complex environment, we recognize and transfer three critical elements to deep networks: (1) simultaneous exposure to diverse cross-task and cross-domain information in each batch. (2) partitioned knowledge storage in separate lego units driven by knowledge sharing. (3) sparse activation of a subset of lego units for both pre-training and downstream tasks. Noteworthy, the joint training of disparate vision tasks is non-trivial due to their differences in input shapes, loss functions, output formats, data distributions, etc. Therefore, we innovatively develop a plug-and-play multi-task training algorithm, which supports Single Iteration Multiple Tasks (SIMT) concurrently training. SIMT lays the foundation of pre-training with large-scale multi-task multi-domain datasets and is proved essential for stable training in our GPPF experiments. Excitingly, the exhaustive experiments show that, our GPPF-R50 model achieves significant improvements of 2.5-5.8 over a strong baseline of the 8 pre-training tasks in GPPF-15M and harvests a range of SOTAs over the 22 downstream tasks with similar computation budgets. We also validate the generalization ability of GPPF to SOTA vision transformers with consistent improvements. These solid experimental results fully prove the effective knowledge learning, storing, sharing, and transfer provided by our novel GPPF framework.