 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Aligning Diffusion Models with Fine-Tuning Is Easier Than You Think
Mar 19, 2026Aligning Diffusion models has achieved remarkable breakthroughs in generating high-quality, human preference-aligned images. Existing techniques, such as supervised fine-tuning (SFT) and DPO-style preference optimization, have become principled tools for fine-tuning diffusion models. However, SFT relies on high-quality images that are costly to obtain, while DPO-style methods depend on large-scale preference datasets, which are often inconsistent in quality. Beyond data dependency, these methods are further constrained by computational inefficiency. To address these two challenges, we propose Composite Reward Assisted Fine-Tuning (CRAFT), a lightweight yet powerful fine-tuning paradigm that requires significantly reduced training data while maintaining computational efficiency. It first leverages a Composite Reward Filtering (CRF) technique to construct a high-quality and consistent training dataset and then perform an enhanced variant of SFT. We also theoretically prove that CRAFT actually optimizes the lower bound of group-based reinforcement learning, establishing a principled connection between SFT with selected data and reinforcement learning. Our extensive empirical results demonstrate that CRAFT with only 100 samples can easily outperform recent SOTA preference optimization methods with thousands of preference-paired samples. Moreover, CRAFT can even achieve 11-220$\times$ faster convergences than the baseline preference optimization methods, highlighting its extremely high efficiency.
Zeroth-Order Optimization is Secretly Single-Step Policy Optimization
Jun 17, 2025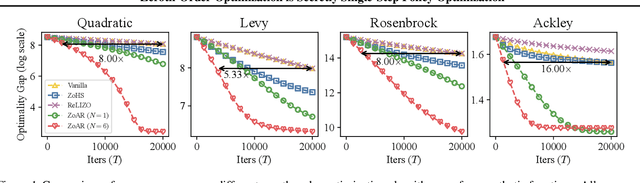

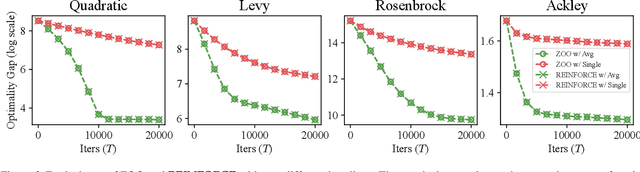

Zeroth-Order Optimization (ZOO) provides powerful tools for optimizing functions where explicit gradients are unavailable or expensive to compute. However, the underlying mechanisms of popular ZOO methods, particularly those employing randomized finite differences, and their connection to other optimization paradigms like Reinforcement Learning (RL) are not fully elucidated. This paper establishes a fundamental and previously unrecognized connection: ZOO with finite differences is equivalent to a specific instance of single-step Policy Optimization (PO). We formally unveil that the implicitly smoothed objective function optimized by common ZOO algorithms is identical to a single-step PO objective. Furthermore, we show that widely used ZOO gradient estimators, are mathematically equivalent to the REINFORCE gradient estimator with a specific baseline function, revealing the variance-reducing mechanism in ZOO from a PO perspective.Built on this unified framework, we propose ZoAR (Zeroth-Order Optimization with Averaged Baseline and Query Reuse), a novel ZOO algorithm incorporating PO-inspired variance reduction techniques: an averaged baseline from recent evaluations and query reuse analogous to experience replay. Our theoretical analysis further substantiates these techniques reduce variance and enhance convergence. Extensive empirical studies validate our theory and demonstrate that ZoAR significantly outperforms other methods in terms of convergence speed and final performance. Overall, our work provides a new theoretical lens for understanding ZOO and offers practical algorithmic improvements derived from its connection to PO.
A Dual-Agent Adversarial Framework for Robust Generalization in Deep Reinforcement Learning
Jan 29, 2025



Recently, empowered with the powerful capabilities of neural networks, reinforcement learning (RL) has successfully tackled numerous challenging tasks. However, while these models demonstrate enhanced decision-making abilities, they are increasingly prone to overfitting. For instance, a trained RL model often fails to generalize to even minor variations of the same task, such as a change in background color or other minor semantic differences. To address this issue, we propose a dual-agent adversarial policy learning framework, which allows agents to spontaneously learn the underlying semantics without introducing any human prior knowledge. Specifically, our framework involves a game process between two agents: each agent seeks to maximize the impact of perturbing on the opponent's policy by producing representation differences for the same state, while maintaining its own stability against such perturbations. This interaction encourages agents to learn generalizable policies, capable of handling irrelevant features from the high-dimensional observations. Extensive experimental results on the Procgen benchmark demonstrate that the adversarial process significantly improves the generalization performance of both agents, while also being applied to various RL algorithms, e.g., Proximal Policy Optimization (PPO). With the adversarial framework, the RL agent outperforms the baseline methods by a significant margin, especially in hard-level tasks, marking a significant step forward in the generalization capabilities of deep reinforcement learning.
The Meta-Representation Hypothesis
Jan 05, 2025Humans rely on high-level meta-representations to engage in abstract reasoning. In complex cognitive tasks, these meta-representations help individuals abstract general rules from experience. However, constructing such meta-representations from high-dimensional observations remains a longstanding challenge for reinforcement learning agents. For instance, a well-trained agent often fails to generalize to even minor variations of the same task, such as changes in background color, while humans can easily handle. In this paper, we build a bridge between meta-representation and generalization, showing that generalization performance benefits from meta-representation learning. We also hypothesize that deep mutual learning (DML) among agents can help them converge to meta-representations. Empirical results provide support for our theory and hypothesis. Overall, this work provides a new perspective on the generalization of deep reinforcement learning.
Simple Policy Optimization
Jan 29, 2024PPO (Proximal Policy Optimization) algorithm has demonstrated excellent performance in many fields, and it is considered as a simple version of TRPO (Trust Region Policy Optimization) algorithm. However, the ratio clipping operation in PPO may not always effectively enforce the trust region constraints, this can be a potential factor affecting the stability of the algorithm. In this paper, we propose SPO (Simple Policy Optimization) algorithm, which introduces a novel clipping method for KL divergence between the old and current policies. SPO can effectively enforce the trust region constraints in almost all environments, while still maintaining the simplicity of a first-order algorithm. Comparative experiments in Atari 2600 environments show that SPO sometimes provides stronger performance than PPO. Code is available at https://github.com/MyRepositories-hub/Simple-Policy-Optimization.
Dropout Strategy in Reinforcement Learning: Limiting the Surrogate Objective Variance in Policy Optimization Methods
Nov 03, 2023Policy-based reinforcement learning algorithms are widely used in various fields. Among them, mainstream policy optimization algorithms such as TRPO and PPO introduce importance sampling into policy iteration, which allows the reuse of historical data. However, this can also lead to a high variance of the surrogate objective and indirectly affects the stability and convergence of the algorithm. In this paper, we first derived an upper bound of the surrogate objective variance, which can grow quadratically with the increase of the surrogate objective. Next, we proposed the dropout technique to avoid the excessive increase of the surrogate objective variance caused by importance sampling. Then, we introduced a general reinforcement learning framework applicable to mainstream policy optimization methods, and applied the dropout technique to the PPO algorithm to obtain the D-PPO variant. Finally, we conduct comparative experiments between D-PPO and PPO algorithms in the Atari 2600 environment, and the results show that D-PPO achieved significant performance improvements compared to PPO, and effectively limited the excessive increase of the surrogate objective variance during training.