 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongbaMIE: A Multimodal Information Extraction Dataset for Evaluating Semantic Understanding of Dongba Pictograms
Mar 05, 2025
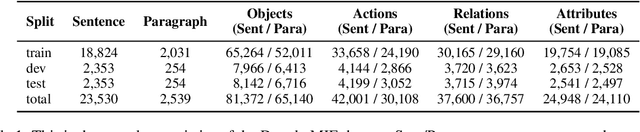
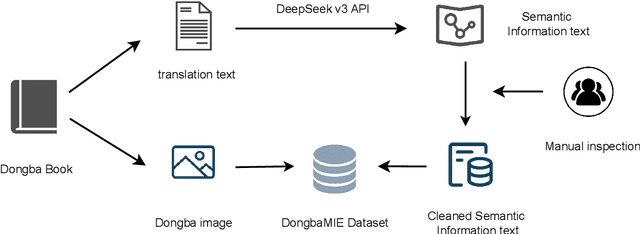
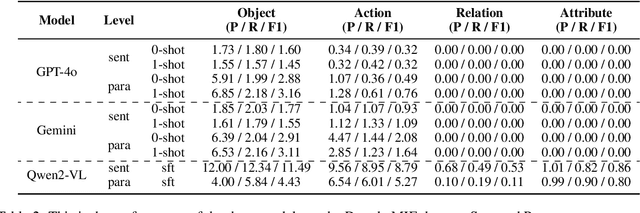
Dongba pictographs are the only pictographs still in use in the world. They have pictorial ideographic features, and their symbols carry rich cultural and contextual information. Due to the lack of relevant datasets, existing research has difficulty in advancing the study of semantic understanding of Dongba pictographs. To this end, we propose DongbaMIE, the first multimodal dataset for semantic understanding and extraction of Dongba pictographs. The dataset consists of Dongba pictograph images and their corresponding Chinese semantic annotations. It contains 23,530 sentence-level and 2,539 paragraph-level images, covering four semantic dimensions: objects, actions, relations, and attributes. We systematically evaluate the GPT-4o, Gemini-2.0, and Qwen2-VL models. Experimental results show that the F1 scores of GPT-4o and Gemini in the best object extraction are only 3.16 and 3.11 respectively. The F1 score of Qwen2-VL after supervised fine-tuning is only 11.49. These results suggest that current large multimodal models still face significant challenges in accurately recognizing the diverse semantic information in Dongba pictographs. The dataset can be obtained from this URL.
Dropout Strategy in Reinforcement Learning: Limiting the Surrogate Objective Variance in Policy Optimization Methods
Nov 03, 2023Policy-based reinforcement learning algorithms are widely used in various fields. Among them, mainstream policy optimization algorithms such as TRPO and PPO introduce importance sampling into policy iteration, which allows the reuse of historical data. However, this can also lead to a high variance of the surrogate objective and indirectly affects the stability and convergence of the algorithm. In this paper, we first derived an upper bound of the surrogate objective variance, which can grow quadratically with the increase of the surrogate objective. Next, we proposed the dropout technique to avoid the excessive increase of the surrogate objective variance caused by importance sampling. Then, we introduced a general reinforcement learning framework applicable to mainstream policy optimization methods, and applied the dropout technique to the PPO algorithm to obtain the D-PPO variant. Finally, we conduct comparative experiments between D-PPO and PPO algorithms in the Atari 2600 environment, and the results show that D-PPO achieved significant performance improvements compared to PPO, and effectively limited the excessive increase of the surrogate objective variance during training.