 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSepSeq: A Training-Free Framework for Long Numerical Sequence Processing in LLMs
Apr 09, 2026While transformer-based Large Language Models (LLMs) theoretically support massive context windows, they suffer from severe performance degradation when processing long numerical sequences. We attribute this failure to the attention dispersion in the Softmax mechanism, which prevents the model from concentrating attention. To overcome this, we propose Separate Sequence (SepSeq), a training-free, plug-and-play framework to mitigate dispersion by strategically inserting separator tokens. Mechanistically, we demonstrate that separator tokens act as an attention sink, recalibrating attention to focus on local segments while preserving global context. Extensive evaluations on 9 widely-adopted LLMs confirm the effectiveness of our approach: SepSeq yields an average relative accuracy improvement of 35.6% across diverse domains while reducing total inference token consumption by 16.4% on average.
Rethinking ANN-based Retrieval: Multifaceted Learnable Index for Large-scale Recommendation System
Feb 18, 2026Approximate nearest neighbor (ANN) search is widely used in the retrieval stage of large-scale recommendation systems. In this stage, candidate items are indexed using their learned embedding vectors, and ANN search is executed for each user (or item) query to retrieve a set of relevant items. However, ANN-based retrieval has two key limitations. First, item embeddings and their indices are typically learned in separate stages: indexing is often performed offline after embeddings are trained, which can yield suboptimal retrieval quality-especially for newly created items. Second, although ANN offers sublinear query time, it must still be run for every request, incurring substantial computation cost at industry scale. In this paper, we propose MultiFaceted Learnable Index (MFLI), a scalable, real-time retrieval paradigm that learns multifaceted item embeddings and indices within a unified framework and eliminates ANN search at serving time. Specifically, we construct a multifaceted hierarchical codebook via residual quantization of item embeddings and co-train the codebook with the embeddings. We further introduce an efficient multifaceted indexing structure and mechanisms that support real-time updates. At serving time, the learned hierarchical indices are used directly to identify relevant items, avoiding ANN search altogether. Extensive experiments on real-world data with billions of users show that MFLI improves recall on engagement tasks by up to 11.8\%, cold-content delivery by up to 57.29\%, and semantic relevance by 13.5\% compared with prior state-of-the-art methods. We also deploy MFLI in the system and report online experimental results demonstrating improved engagement, less popularity bias, and higher serving efficiency.
One-Embedding-Fits-All: Efficient Zero-Shot Time Series Forecasting by a Model Zoo
Sep 04, 2025The proliferation of Time Series Foundation Models (TSFMs) has significantly advanced zero-shot forecasting, enabling predictions for unseen time series without task-specific fine-tuning. Extensive research has confirmed that no single TSFM excels universally, as different models exhibit preferences for distinct temporal patterns. This diversity suggests an opportunity: how to take advantage of the complementary abilities of TSFMs. To this end, we propose ZooCast, which characterizes each model's distinct forecasting strengths. ZooCast can intelligently assemble current TSFMs into a model zoo that dynamically selects optimal models for different forecasting tasks. Our key innovation lies in the One-Embedding-Fits-All paradigm that constructs a unified representation space where each model in the zoo is represented by a single embedding, enabling efficient similarity matching for all tasks. Experiments demonstrate ZooCast's strong performance on the GIFT-Eval zero-shot forecasting benchmark while maintaining the efficiency of a single TSFM. In real-world scenarios with sequential model releases, the framework seamlessly adds new models for progressive accuracy gains with negligible overhead.
OmniAD: Detect and Understand Industrial Anomaly via Multimodal Reasoning
May 28, 2025While anomaly detection has made significant progress, generating detailed analyses that incorporate industrial knowledge remains a challenge. To address this gap, we introduce OmniAD, a novel framework that unifies anomaly detection and understanding for fine-grained analysis. OmniAD is a multimodal reasoner that combines visual and textual reasoning processes. The visual reasoning provides detailed inspection by leveraging Text-as-Mask Encoding to perform anomaly detection through text generation without manually selected thresholds. Following this, Visual Guided Textual Reasoning conducts comprehensive analysis by integrating visual perception. To enhance few-shot generalization, we employ an integrated training strategy that combines supervised fine-tuning (SFT) with reinforcement learning (GRPO), incorporating three sophisticated reward functions. Experimental results demonstrate that OmniAD achieves a performance of 79.1 on the MMAD benchmark, surpassing models such as Qwen2.5-VL-7B and GPT-4o. It also shows strong results across multiple anomaly detection benchmarks. These results highlight the importance of enhancing visual perception for effective reasoning in anomaly understanding. All codes and models will be publicly available.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025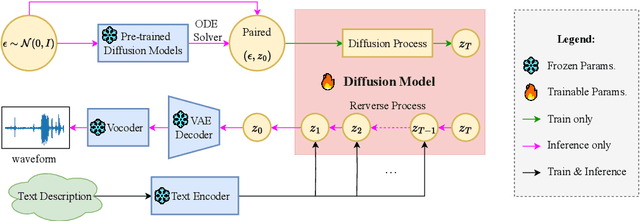
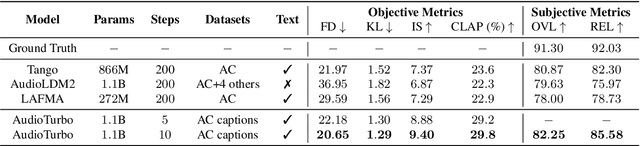
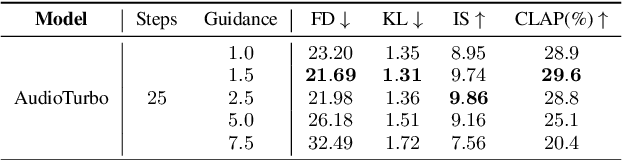
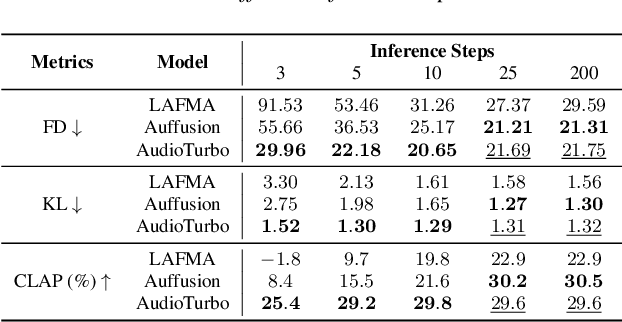
Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.
DongbaMIE: A Multimodal Information Extraction Dataset for Evaluating Semantic Understanding of Dongba Pictograms
Mar 05, 2025
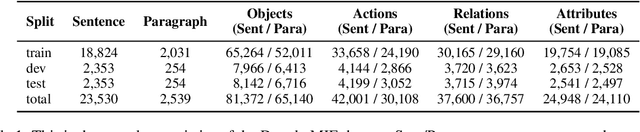
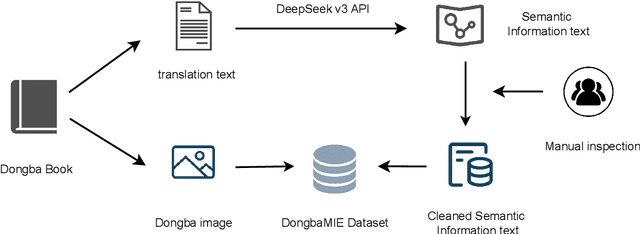
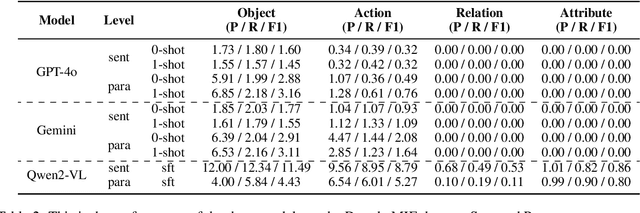
Dongba pictographs are the only pictographs still in use in the world. They have pictorial ideographic features, and their symbols carry rich cultural and contextual information. Due to the lack of relevant datasets, existing research has difficulty in advancing the study of semantic understanding of Dongba pictographs. To this end, we propose DongbaMIE, the first multimodal dataset for semantic understanding and extraction of Dongba pictographs. The dataset consists of Dongba pictograph images and their corresponding Chinese semantic annotations. It contains 23,530 sentence-level and 2,539 paragraph-level images, covering four semantic dimensions: objects, actions, relations, and attributes. We systematically evaluate the GPT-4o, Gemini-2.0, and Qwen2-VL models. Experimental results show that the F1 scores of GPT-4o and Gemini in the best object extraction are only 3.16 and 3.11 respectively. The F1 score of Qwen2-VL after supervised fine-tuning is only 11.49. These results suggest that current large multimodal models still face significant challenges in accurately recognizing the diverse semantic information in Dongba pictographs. The dataset can be obtained from this URL.
Molly: Making Large Language Model Agents Solve Python Problem More Logically
Dec 24, 2024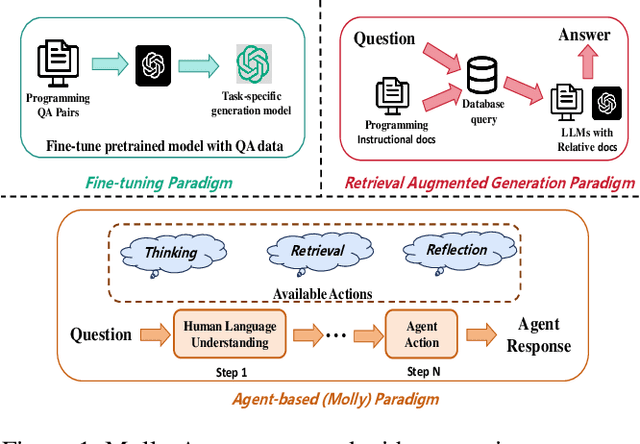
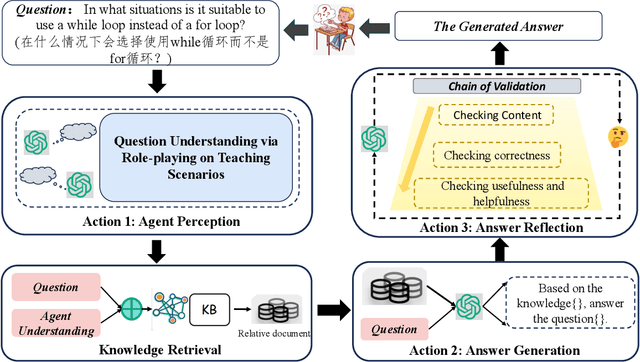

Applying large language models (LLMs) as teaching assists has attracted much attention as an integral part of intelligent education, particularly in computing courses. To reduce the gap between the LLMs and the computer programming education expert, fine-tuning and retrieval augmented generation (RAG) are the two mainstream methods in existing researches. However, fine-tuning for specific tasks is resource-intensive and may diminish the model`s generalization capabilities. RAG can perform well on reducing the illusion of LLMs, but the generation of irrelevant factual content during reasoning can cause significant confusion for learners. To address these problems, we introduce the Molly agent, focusing on solving the proposed problem encountered by learners when learning Python programming language. Our agent automatically parse the learners' questioning intent through a scenario-based interaction, enabling precise retrieval of relevant documents from the constructed knowledge base. At generation stage, the agent reflect on the generated responses to ensure that they not only align with factual content but also effectively answer the user's queries. Extensive experimentation on a constructed Chinese Python QA dataset shows the effectiveness of the Molly agent, indicating an enhancement in its performance for providing useful responses to Python questions.
MIETT: Multi-Instance Encrypted Traffic Transformer for Encrypted Traffic Classification
Dec 19, 2024



Network traffic includes data transmitted across a network, such as web browsing and file transfers, and is organized into packets (small units of data) and flows (sequences of packets exchanged between two endpoints). Classifying encrypted traffic is essential for detecting security threats and optimizing network management. Recent advancements have highlighted the superiority of foundation models in this task, particularly for their ability to leverage large amounts of unlabeled data and demonstrate strong generalization to unseen data. However, existing methods that focus on token-level relationships fail to capture broader flow patterns, as tokens, defined as sequences of hexadecimal digits, typically carry limited semantic information in encrypted traffic. These flow patterns, which are crucial for traffic classification, arise from the interactions between packets within a flow, not just their internal structure. To address this limitation, we propose a Multi-Instance Encrypted Traffic Transformer (MIETT), which adopts a multi-instance approach where each packet is treated as a distinct instance within a larger bag representing the entire flow. This enables the model to capture both token-level and packet-level relationships more effectively through Two-Level Attention (TLA) layers, improving the model's ability to learn complex packet dynamics and flow patterns. We further enhance the model's understanding of temporal and flow-specific dynamics by introducing two novel pre-training tasks: Packet Relative Position Prediction (PRPP) and Flow Contrastive Learning (FCL). After fine-tuning, MIETT achieves state-of-the-art (SOTA) results across five datasets, demonstrating its effectiveness in classifying encrypted traffic and understanding complex network behaviors. Code is available at \url{https://github.com/Secilia-Cxy/MIETT}.
Sharingan: Extract User Action Sequence from Desktop Recordings
Nov 13, 2024Video recordings of user activities, particularly desktop recordings, offer a rich source of data for understanding user behaviors and automating processes. However, despite advancements in Vision-Language Models (VLMs) and their increasing use in video analysis, extracting user actions from desktop recordings remains an underexplored area. This paper addresses this gap by proposing two novel VLM-based methods for user action extraction: the Direct Frame-Based Approach (DF), which inputs sampled frames directly into VLMs, and the Differential Frame-Based Approach (DiffF), which incorporates explicit frame differences detected via computer vision techniques. We evaluate these methods using a basic self-curated dataset and an advanced benchmark adapted from prior work. Our results show that the DF approach achieves an accuracy of 70% to 80% in identifying user actions, with the extracted action sequences being re-playable though Robotic Process Automation. We find that while VLMs show potential, incorporating explicit UI changes can degrade performance, making the DF approach more reliable. This work represents the first application of VLMs for extracting user action sequences from desktop recordings, contributing new methods, benchmarks, and insights for future research.
SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion
Apr 22, 2024

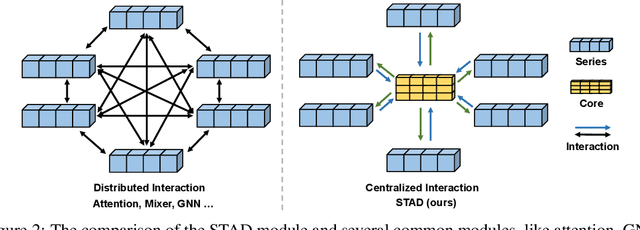

Multivariate time series forecasting plays a crucial role in various fields such as finance, traffic management, energy, and healthcare. Recent studies have highlighted the advantages of channel independence to resist distribution drift but neglect channel correlations, limiting further enhancements. Several methods utilize mechanisms like attention or mixer to address this by capturing channel correlations, but they either introduce excessive complexity or rely too heavily on the correlation to achieve satisfactory results under distribution drifts, particularly with a large number of channels. Addressing this gap, this paper presents an efficient MLP-based model, the Series-cOre Fused Time Series forecaster (SOFTS), which incorporates a novel STar Aggregate-Dispatch (STAD) module. Unlike traditional approaches that manage channel interactions through distributed structures, e.g., attention, STAD employs a centralized strategy. It aggregates all series to form a global core representation, which is then dispatched and fused with individual series representations to facilitate channel interactions effectively. SOFTS achieves superior performance over existing state-of-the-art methods with only linear complexity. The broad applicability of the STAD module across different forecasting models is also demonstrated empirically. For further research and development, we have made our code publicly available at https://github.com/Secilia-Cxy/SOFTS.