 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Embedding-Fits-All: Efficient Zero-Shot Time Series Forecasting by a Model Zoo
Sep 04, 2025The proliferation of Time Series Foundation Models (TSFMs) has significantly advanced zero-shot forecasting, enabling predictions for unseen time series without task-specific fine-tuning. Extensive research has confirmed that no single TSFM excels universally, as different models exhibit preferences for distinct temporal patterns. This diversity suggests an opportunity: how to take advantage of the complementary abilities of TSFMs. To this end, we propose ZooCast, which characterizes each model's distinct forecasting strengths. ZooCast can intelligently assemble current TSFMs into a model zoo that dynamically selects optimal models for different forecasting tasks. Our key innovation lies in the One-Embedding-Fits-All paradigm that constructs a unified representation space where each model in the zoo is represented by a single embedding, enabling efficient similarity matching for all tasks. Experiments demonstrate ZooCast's strong performance on the GIFT-Eval zero-shot forecasting benchmark while maintaining the efficiency of a single TSFM. In real-world scenarios with sequential model releases, the framework seamlessly adds new models for progressive accuracy gains with negligible overhead.
SeqFusion: Sequential Fusion of Pre-Trained Models for Zero-Shot Time-Series Forecasting
Mar 04, 2025Unlike traditional time-series forecasting methods that require extensive in-task data for training, zero-shot forecasting can directly predict future values given a target time series without additional training data. Current zero-shot approaches primarily rely on pre-trained generalized models, with their performance often depending on the variety and relevance of the pre-training data, which can raise privacy concerns. Instead of collecting diverse pre-training data, we introduce SeqFusion in this work, a novel framework that collects and fuses diverse pre-trained models (PTMs) sequentially for zero-shot forecasting. Based on the specific temporal characteristics of the target time series, SeqFusion selects the most suitable PTMs from a batch of pre-collected PTMs, performs sequential predictions, and fuses all the predictions while using minimal data to protect privacy. Each of these PTMs specializes in different temporal patterns and forecasting tasks, allowing SeqFusion to select by measuring distances in a shared representation space of the target time series with each PTM. Experiments demonstrate that SeqFusion achieves competitive accuracy in zero-shot forecasting compared to state-of-the-art methods.
Improving LLMs for Recommendation with Out-Of-Vocabulary Tokens
Jun 12, 2024



Characterizing users and items through vector representations is crucial for various tasks in recommender systems. Recent approaches attempt to apply Large Language Models (LLMs) in recommendation through a question and answer format, where real users and items (e.g., Item No.2024) are represented with in-vocabulary tokens (e.g., "item", "20", "24"). However, since LLMs are typically pretrained on natural language tasks, these in-vocabulary tokens lack the expressive power for distinctive users and items, thereby weakening the recommendation ability even after fine-tuning on recommendation tasks. In this paper, we explore how to effectively tokenize users and items in LLM-based recommender systems. We emphasize the role of out-of-vocabulary (OOV) tokens in addition to the in-vocabulary ones and claim the memorization of OOV tokens that capture correlations of users/items as well as diversity of OOV tokens. By clustering the learned representations from historical user-item interactions, we make the representations of user/item combinations share the same OOV tokens if they have similar properties. Furthermore, integrating these OOV tokens into the LLM's vocabulary allows for better distinction between users and items and enhanced capture of user-item relationships during fine-tuning on downstream tasks. Our proposed framework outperforms existing state-of-the-art methods across various downstream recommendation tasks.
Model Spider: Learning to Rank Pre-Trained Models Efficiently
Jun 06, 2023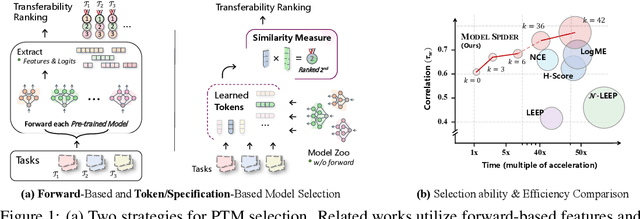
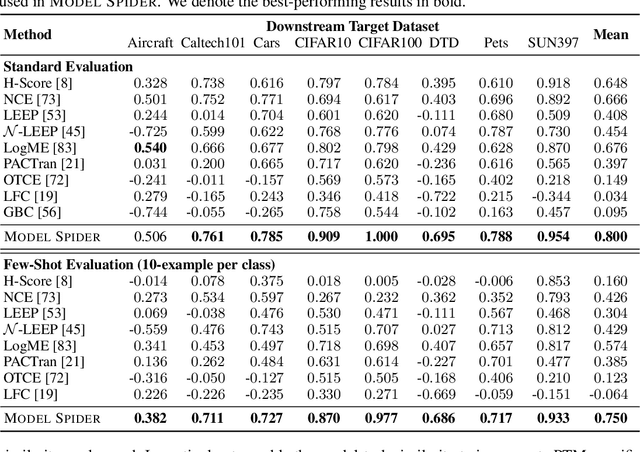
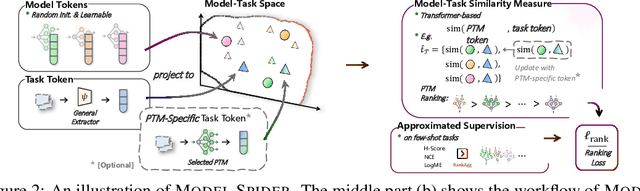
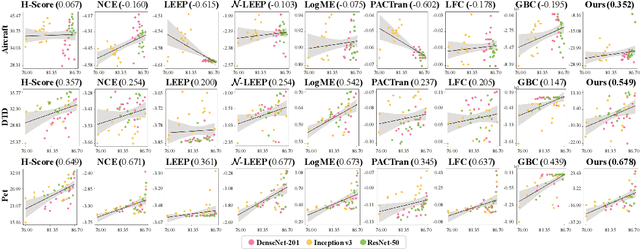
Figuring out which Pre-Trained Model (PTM) from a model zoo fits the target task is essential to take advantage of plentiful model resources. With the availability of numerous heterogeneous PTMs from diverse fields, efficiently selecting the most suitable PTM is challenging due to the time-consuming costs of carrying out forward or backward passes over all PTMs. In this paper, we propose Model Spider, which tokenizes both PTMs and tasks by summarizing their characteristics into vectors to enable efficient PTM selection. By leveraging the approximated performance of PTMs on a separate set of training tasks, Model Spider learns to construct tokens and measure the fitness score between a model-task pair via their tokens. The ability to rank relevant PTMs higher than others generalizes to new tasks. With the top-ranked PTM candidates, we further learn to enrich task tokens with their PTM-specific semantics to re-rank the PTMs for better selection. Model Spider balances efficiency and selection ability, making PTM selection like a spider preying on a web. Model Spider demonstrates promising performance in various configurations of model zoos.